ITS
Abschlussprüfung Teil 2
- Subnetting
- Aufbau / Planung WLAN-Netzwerk
- Routing
- VPN (E2E, E2S, S2S)
- IT-Security
- Backupstrategien
- DMZ
- Proxy
- Zertifikate
- Symmetrisch / Asymmetrische Leitungen
- RAID-Level
- IPv6
- Strukturierte Verkabelung
- NAT/PAT
- Firewall
- Verschlüsselung
- Bootloader & Partitionstabellen
- Gängige Ports im Internet
- Logische Operatoren
- Berechnungshilfe
- VLAN
- Unicast, Multicast, Broadcast und Anycast
- WLAN-Authentifizierung
Subnetting
Beim Subnetting geht es darum, den IP-Adressraum in kleinere Teile zu zerschneiden.
Dies wird aus verschiedenen Gründen gemacht:
- Sicherheit: Zwischen den Subnetzen kann der Traffic von einer Firewall/Router mithilfe von Paketfiltern kontrolliert werden. Im Falle eines Sicherheitsvorfalls sind Geräte in anderen Subnetzen geschützt. Bei der Verwendung von Subnetzen ohne andere Schutzmechanismen (z.B. VLANs) ist aber Vorsicht geboten. Eine IP-Adresse kann einfach auf Client-Seite geändert werden.
- Broadcasts als Performancekiller: Viele Protokolle (DHCP, ARP etc) nutzen Broadcasts. Da Broadcasts an alle Geräte im Netzwerk geschickt werden, steigt bei großen Netzwerken mit vielen Hosts die Anzahl der Pakete und damit die Last im Netzwerk.
- Verwaltbarkeit: Mit Subnetzen kann eine logische Struktur im Netzwerk geschaffen, welche die Übersicht und damit die Verwaltung erleichtert. Zum Beispiel verschiedene Subnetze pro Firmenstandort oder Netze für Server, Clients etc.
IPv4 Subnetting
Subnetzmaske
Zu jeder IP-Adresse wird die Subnetzmaske angegeben.
IPv4: 192.168.178.10/24
Subnetzmaske: 255.255.255.0Die Subnetzmaske gibt an, wie viele der 32 Bits einer IP-Adresse die Netzadresse darstellen. Die Bits des Netzanteils werden binär mit 1 und die Bits des Hostanteils mit 0 angegeben. Nach einer 0 darf keine 1 mehr folgen. Die Anzahl der möglichen Subnetze/Hosts erhält man, indem man 2^(Anzahl Bits) rechnet.
Die Subnetzmaske 255.255.255.0 entspricht binär 11111111 11111111 11111111 00000000. Folglich stellen die ersten 24 Bit den Netzanteil und die verbleibenden 8 Bit den Hostanteil dar.
Die Subnetzmaske kann auf zwei Arten aufgeschrieben werden. In der alten Schreibweise werden die 32 Bit, welche die Subnetzmaske hat, in 4 Blöcke zu je 8 Bit aufgeteilt und anschließend in Dezimalzahlen umgerechnet und mit Punkt getrennt aufgeschrieben werden, z.B. 255.255.255.0. Mittlerweile hat sich eine andere Darstellung etabliert. Bei dieser wird die Anzahl der Bits, welche zum Netzanteil gehören, mit einem "/" hinter die IP-Adresse geschrieben, z.B. 192.168.178.10/24, was der oben genannten Subnetzmaske 255.255.255.0 entspricht.
Um von CIDR in die herkömmliche Notation zu kommen, muss man lediglich die die 32 Bit einer IP Adresse aufschreiben und von links nach rechts die Anzahl der Bits auf 1 setzen, die in CIDR angegeben ist, und anschließend den 8er-Block in dezimal umrechnen, in dem nicht alles 1 oder 0 ist. Blöcke in denen alles 1 ist sind 255, Blöcke in denen alles 0 ist sind 0.
Bei allen Subnetzmasken, die mit 255 enden (in CIDR vielfache von 8 sind), kann man sich die Dotted-Dezimal-Schreibweise der IP-Adresse zu nutze machen, denn in dem Fall ist die Grenze zwischen Netzanteil und Hostanteil genau auf einem Punkt und damit sehr einfach abzulesen.
| Subnetzmaske CIDR |
Subnetzmaske Dotted-Dezimal |
Format (X = Netzanteil, Y = Hostanteil) |
| /8 |
255.0.0.0 |
X.Y.Y.Y |
| /16 |
255.255.0.0 |
X.X.Y.Y |
| /24 |
255.255.255.0 |
X.X.X.Y |
Gibt es in der Subnetzmaske einen Block, welcher nicht 255 oder 0 ist, lassen sich Netz-und Hostanteil nur bestimmen, indem der Block binär betrachtet wird.
Beispiel
Subnetzmaske: 255.255.224.0Die Blöcke 1, 2 und 4 sind uninteressant. Block 1 und 2 gehören fest zum Netzanteil, Block 4 gehört fest zum Hostanteil. Im 3. Block befindet sich die Grenze zwischen Netz-und Hostanteil. Die 224 ist binär 1110 0000, folglich gehören die ersten 3 Bit des Blocks zum Netzanteil und die weiteren 5 Bit zum Hostanteil. Über die gesamten 32 Bit betrachtet sind die ersten 19 Bit dem Netzanteil und die restlichen 13 Bit dem Hostanteil zugehörig. Folglich wäre die Subnetzmaske als "/19" darzustellen.
Anzahl Subnetze und Anzahl Hosts in einem Subnetz
Um die Anzahl der möglichen Subnetze und möglichen Hosts in einem Subnetz muss man lediglich 2^(Anzahl der Bit) rechnen. Beim Hostanteil gibt es die Besonderheit, dass die erste (alle Bit des Hostanteils auf 0) und die letzte (alle Bit des Hostanteils auf 1) mögliche IP nicht für Hosts nutzbar sind, da sie für Netzadresse und directed Broadcast reserviert sind. Bei der Bildung von Subnetzen muss dies beachtet werden, denn man braucht immer 2 Adressen mehr als man Hosts in dem Netz haben möchte. Bei 4 Hosts müssen 3 Bit verwendet werden, da 6 Adressen benötigt werden. 2 Bit reichen nicht.
Bei einer Subnetzmaske von 255.255.255.0 oder CIDR "/24" sind 2^24 Subnetze möglich mit jeweils 2^8 - 2 (Netz-und Broadcast-Adresse) Hosts pro Subnetz.
Berechnen der Netz-Adresse
Anhand einer IP-Adresse und der zugehörigen Subnetzmaske kann die Netz-Adresse berechnet werden. Dazu muss man zunächst IP-Adresse und Subnetzmaske in die binäre Schreibweise bringen und diese anschließend mit einem logischen UND miteinander verknüpfen.
| IP-Adresse |
192.168.178.10 |
11000000 10101000 10110010 00001010 |
| Subnetzmaske |
255.255.255.0 |
11111111 11111111 11111111 00000000 |
| logisches UND | ||
| Netz-Adresse | 192.168.178.0 |
11000000 10101000 10110010 00000000 |
Subnetze bilden
gegeben:
IP: 10.0.23.192/25
Subnetzmaske: 255.255.255.128
Aufgabe:
- 4 Subnetze erstellen
- 4 Hosts (Subnetz 1), 12 Hosts (Subnetz 2), 31 Hosts (Subnetz 3), 6 Hosts (Subnetz 4)
- keine LückenIm ersten Schritt wird notiert, wie viele Hosts in dem Subnetz benötigt werden, wie viele Host-Bits dafür nötig sind, mit wie vielen Bit die Subnetzmaske erweitert wird (zusätzliche Netz-Bits) und wie die Subnetzmaske des Subnetzes aussieht. Es ist sinnvoll, die zu erstellenden Subnetze bereits hier nach Größe vom größten zum kleinsten zu sortieren.
Erinnerung: Da die erste und letzte Adresse eines Subnetzes reserviert sind, werden immer 2 Adressen mehr benötigt als Hosts in dem Netzwerk sind.
| Subnetz |
Anzahl Hosts |
Anzahl nötiger Host-Bits |
Anzahl zusätzlicher Netz-Bits |
CIDR |
Subnetzmaske |
| 3 |
31 + 2 |
6 (max. 64 Hosts) |
1 |
/26 |
255.255.255.224 |
| 2 |
12 + 2 |
4 (max. 16 Hosts) |
3 |
/28 |
255.255.255.240 |
|
1 |
4 + 2 |
3 (max. 8 Hosts) |
4 |
/29 |
255.255.255.248 |
| 4 |
6 + 2 |
3 (max. 8 Hosts) |
4 |
/29 |
255.255.255.248 |
Anschließend muss zunächst die Netzadresse des Bereichs gefunden werden, in dem die Subnetze gebildet werden. Hierfür wird die gegebene IP-Adresse und Subnetzmaske mit einem logischen UND verknüpft. Es muss nur der Block betrachtet werden, der nicht 255 und 0 ist, d.h. der Block mit der 128.
| 10.0.23.192 |
1100 0000 |
|
| 255.255.255.128 |
1000 0000 | |
| UND |
10.0.23.128 |
1000 0000 |
Der Bereich, der für die Bildung der Subnetze zur Verfügung steht, ist der Bereich zwischen 10.0.23.128 und 10.0.23.255.
Anschließend fängt man mit der ausgerechneten Netzadresse an und bildet die Subnetze (die Subnetzmaske hat man ja bereits herausgefunden).
Die Netzadresse des 1. Subnetzes ist identisch mit der Netzadresse des gesamten gegebenen Netzbereichs (die Subnetzmaske aber nicht). Anhand der Anzahl der Host-Bits kann man die Anzahl der möglichen Adressen des Subnetzes berechnen. Dies hilft bei der Errechnung der Netzadressen, da man einfach auf die Netzadresse des vorigen Netzwerks die Anzahl der Adressen dazuaddieren kann, um auf die Netzadresse des Folgenetzes zu kommen.
| Subnetz |
Netzadresse |
erster Host |
letzter Host |
Broadcast |
Subnetzmaske |
| 3 |
10.0.23.128 |
10.0.23.129 |
10.0.23.190 |
10.0.23.191 |
255.255.255.224 bzw. /26 |
| 2 |
10.0.23.192 | 10.0.23.193 |
10.0.23.206 |
10.0.23.207 |
255.255.255.240 bzw. /28 |
| 1 |
10.0.23.208 |
10.0.23.209 |
10.0.23.214 |
10.0.23.215 |
255.255.255.248 bzw. /29 |
| 4 | 10.0.23.216 |
10.0.23.217 |
10.0.23.222 |
10.0.23.223 |
255.255.255.248 bzw. /29 |
IPv6 Subnetting
Bei IPv6 wurde das Subnetting deutlich erleichtert. Während bei IPv4 Host-und Netzanteil variabel sind und mithilfe der Subnetzmaske nach Belieben verändert werden können, sind Netzanteil und Hostanteil fix jeweils 64 Bit lang, was bedeutet, dass es 2^64 verschiedene Netze und pro Netz 2^64 Hosts geben kann. Die Subnetzmaske ist nicht mehr nötig bzw. ist sie bei einem Client immer /64, da die ersten 64 Bit der Adresse immer das Netz angeben. Bei IPv6 werden die Subnetze im Bereich zwischen Präfix und Anfang des Hostanteils gebildet. Hier kommt es darauf an, welche Länge das IPv6-Präfix hat, welches einem vom Provider zugewiesen wurde. Das Präfix wird wie die Subnetzmaske in CIDR-Notation angegeben, z.B. "/48". Bei einem Präfix mit einer Länge von 48 Bit (CIDR: /48) hat man also 16 Bit, mit denen man Subnetze bilden kann.
Privatkunden bekommen in der Regel ein /64 Prefix zugeteilt, d.h. es können keine Subnetze gebildet werden.
Zwischen dem Ende des zugeteilten Präfix und dem Ende des Netzanteils der IPv6-Adresse (die ersten 64 Bit), können Subnetze gebildet werden. Bei Präfixlängen, welche durch 4 teilbar sind, liegt die Grenze zwischen Präfix und Teil für Subnetting auf zwischen 2 Stellen, d.h. die Subnetze können durch simples hexadezimales Hochzählen (0-9, A-F) gebildet werden. Ist dies nicht der Fall, muss die Stelle, in der die Grenze verläuft, binär betrachtet werden.
Der Hostanteil ist bei IPv6 fest 64 Bit lang, d.h. der Denksport wie bei IPv4 entfällt vollständig.
Beispiel 1
gegebenes Präfix: 2001:db8:db8:b008/62Zwischen Präfix und sind 2 Bit, d.h. es können 2^2 (4) Subnetze gebildet werden. Eine Stelle wird bei einer IPv6 Adresse als Hexadezimal-Ziffer geschrieben. Jede Hexadezimal-Ziffer kann durch 4 Bit repräsentiert werden. Da 62 nicht ohne Rest durch 4 teilbar ist, verläuft die Grenze zwischen Präfix und Subnetzteil nicht zwischen 2 Stellen, sondern innerhalb einer Stelle (hier vor den letzten 2 Bit der letzten Stelle). Diese muss daher binär betrachtet werden. Man zählt binär innerhalb der Bit hoch, in welchem die Subnetze gebildet werden, die anderen Bit bleiben stehen.
| Subnetz |
Netz-Präfix |
hex |
Netzadresse |
| 1 |
2001:db8:db8:b00[1000]/64 |
8 |
2001:db8:db8:b008/64 |
| 2 |
2001:db8:db8:b00[1001]/64 | 9 |
2001:db8:db8:b009/64 |
| 3 |
2001:db8:db8:b00[1010]/64 | a |
2001:db8:db8:b00a/64 |
| 4 |
2001:db8:db8:b00[1011]/64 | b |
2001:db8:db8:b00b/64 |
Beispiel 2
gegebenes Präfix: 2001:db8:db8:b000/56Bei der Präfixlänge 60 sind 8 Bit für Subnetze übrig, d.h. es können 2^8 (256) Subnetze gebildet werden. Da 56 durch 4 teilbar ist, verläuft die Grenze zwischen Präfixanteil und Subnetzteil zwischen 2 Stellen (im Beispiel vor der vorletzten Stelle des Netzanteils), d.h. Subnetze können durch simples hexadezimales Hochzählen gebildet werden.
| Subnetz |
Netzadresse |
| 0 |
2001:db8:db8:b000/64 |
| 1 |
2001:db8:db8:b001/64 |
| 2 |
2001:db8:db8:b002/64 |
| 3 |
2001:db8:db8:b003/64 |
| ... |
... |
| 10 | 2001:db8:db8:b00a/64 |
| ... |
... |
| 15 |
2001:db8:db8:b00f/64 |
| 16 |
2001:db8:db8:b010/64 |
| ... |
... |
| 31 |
2001:db8:db8:b01f/64 |
| 32 |
2001:db8:db8:b020/64 |
| ... |
... |
| 47 |
2001:db8:db8:b02f/64 |
| ... |
... |
| 63 |
2001:db8:db8:b03f/64 |
| ... |
... |
| 79 |
2001:db8:db8:b04f7/64 |
| ... |
... |
| 95 |
2001:db8:db8:b05f/64 |
| ... |
... |
| 255 |
2001:db8:db8:b0ff/64 |
Aufbau / Planung WLAN-Netzwerk
Festlegen von Anforderungen
Es empfiehlt sich, die Anforderungen und Ziele an ein WLAN-Netzwerk zu bestimmen. Dies ist ein wichtiger Schritt, denn manche Ziele stehen im Widerspruch zueinander. Zum Beispiel könnte ein Unternehmen Wert auf eine große Umgebung legen, um viele Videoclients zu unterstützen, die alle auf der 2,4-GHz-Frequenz arbeiten. Diese beiden Anforderungen wären aufgrund der geringeren Bandbreite der Frequenz nicht miteinander vereinbar.
Eine gründliche Bewertung vor der Installation kann den Teams helfen, Konflikte zu vermeiden und die
Geschäftsanforderungen zu erfüllen.
Durchführen von Standortanalysen vor der Installation
In diesem Prozess gilt es unter anderem, die Grundrisse zu berücksichtigen, die Wanddämpfung zu prüfen und die Ausbreitung der Funkfrequenzen zu messen. Im Wesentlichen lässt sich mit Standortanalysen herausfinden, wo die besten Standorte für die Montage von Access Points (AP) sind, um eine optimale Abdeckung zu erreichen. Standortanalysen können auch Problembereiche bei bestehenden Designs aufzeigen.
Eine weitere Möglichkeit, WLAN-Probleme zu beurteilen, besteht darin, mit Mitarbeitende zu sprechen, die in der Nähe der Abdeckungsbereiche arbeiten. Sie werden höchstwahrscheinlich in der Lage sein, Stellen mit schlechtem Empfang, Signalausfällen und Signalverlusten präzise zu lokalisieren.
Auch ein wichtiger Punkt bei der Wahl des Standortes ist die Verfügbarkeit bzw. Machbarkeit von PoE. Mit „Power over Ethernet“ ist die Stromversorgung von verschiedenen netzwerkfähigen Geräten über das LAN-Kabel gemeint. Dabei übernimmt das Kabel sozusagen nicht nur die Versorgung mit Daten, sondern auch mit Energie. Der Vorteil dieser Technik liegt auf der Hand: Man kann das Stromkabel einsparen. Das wiederum vermeidet Kabelsalat, spart auf engem Raum Platz und meist auch Installationskosten.
Erkunden der Umgebung
Eine der einfachsten Möglichkeiten, ein Gefühl für die Situation in den Versorgungsgebieten zu bekommen, ist eine Umgebungsbegehung. Teams können sehen, wie die Racks und Kabel organisiert sind, prüfen, ob die APs richtig beschriftet wurden, und kontrollieren, in welchem Zustand sich das Data Center befindet.
Das IT-Team sollte darauf zu achten, wo und wie die APs angebracht sind. Einige der Faktoren, die es zu überprüfen gilt:
- APs für die Deckenmontage, die an Wänden installiert sind.
- Falsch ausgerichtete Richt- oder Patch-Antennen.
- LED-Anzeigen an APs.
- AP-Ausbreitungsmuster.
- Interferenzen, wenn zwei APs versuchen, dieselbe Frequenz zu nutzen.
In diesem Zusammenhang können die IT-Teams auch Umgebungsfaktoren wie Metallregale, Weihnachtsbäume, Mikrowellengeräte und ungünstige AP-Standorte berücksichtigen. Es ist ebenfalls wichtig, den physischen Zugang zu den IT-Bereichen ordnungsgemäß zu sichern, damit niemand einfach hereinspazieren und auf das Netzwerk zugreifen kann.
Potenzielle AP-Upgrades beobachten
Eine weitere Best Practice besteht darin, die Hardwareversionen und Software-Updates der verschiedenen drahtlosen Geräte zu kontrollieren. Überwachen Sie deren Alter, beachten Sie Meldungen über Sicherheitslücken. Vergessen Sie nicht das Patchen, das eine wichtige Sicherheitsmaßnahme ist, um Ransomware-Angriffe zu verhindern.
In einigen Fällen kann für IT-Teams ein Upgrade der Geräte kostengünstiger sein als eine Umgestaltung des WLAN-Netzwerks. Neuere APs verfügen über erweiterte Fähigkeiten und bieten mehr Reichweite, bessere Funktionen und Kontrolle.
Management-Tools
Per Event Reporting, wie Syslog- und SNMP-Traps (Simple Network Management Protocol), können die Geräte auftretende Probleme an das Netzwerkmanagementsystem melden. Die IT-Abteilung kann dann diese Ereignisse überwachen und die Probleme beheben.
Digital Experience Monitoring (DEM) ist eine weitere Option, die Endpoint Monitoring, Real User Monitoring und Synthetic Transaction Monitoring vereint. Mit dieser Kombination kann DEM die Application Experience eines Endpunkts überwachen und Probleme bei Clients, Anwendungen und im Netzwerk erkennen.
Standortanalysen nach der Installation
Zu guter Letzt sollte die IT-Abteilung eine Standortanalyse nach der Installation durchführen, um festzustellen, ob sich die erwartete Abdeckung erreichen lässt.
WPA2 und WPA3
2,4 GHz und 5 GHz
Routing
Routing dient dazu, den Pfad eines Pakets über ein oder mehrere Netze zu bestimmen.
MAC-und IP-Adressen beim Routing
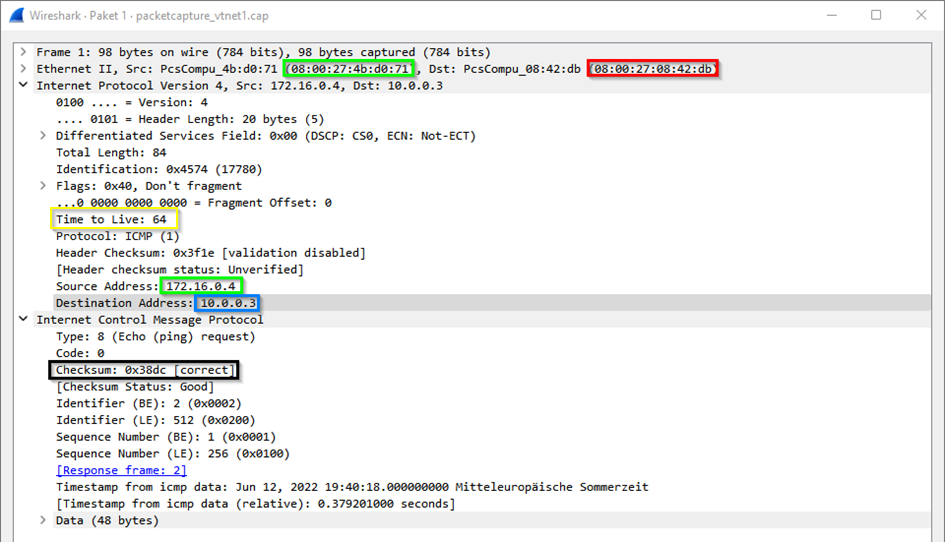
Das folgende Bild zeigt ein ICMP Paket im Netz des Senders (grün = IP + MAC des Quell-Rechners; blau = MAC/IP-Adresse des Ziel-Rechners; gelb = TTL; schwarz = Prüfsumme; rot = MAC des Gateways im Subnetz):
Im Subnetz des Ziels sieht das Paket so aus:
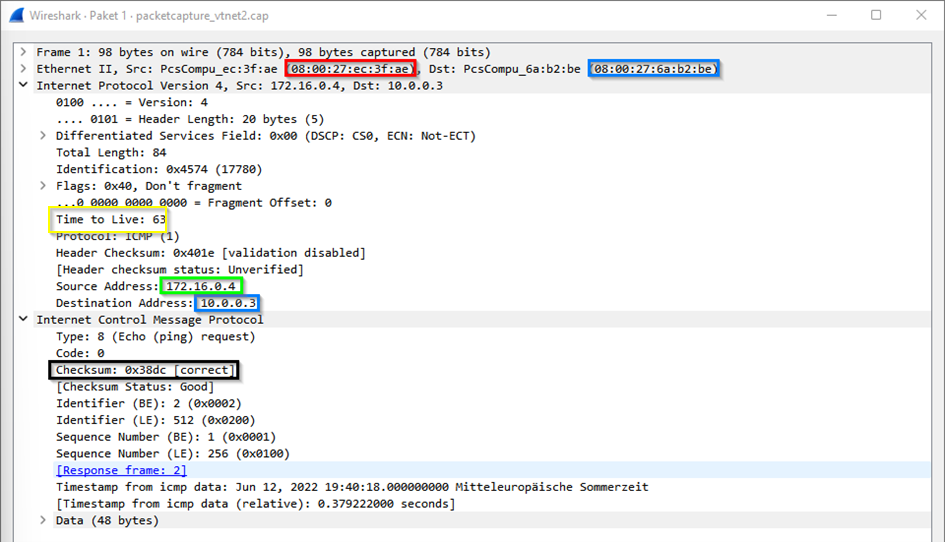
Die Prüfsumme zeigt, dass es sich um dasselbe Paket handelt. Die IP-Adressen haben sich nicht geändert. Geändert haben sich die MAC-Adressen und die TTL (time to live) des Pakets.
Innerhalb eines Subnetzes wird ausschließlich über MAC-Adressen mit anderen Geräten kommuniziert. Zur Auflösung von IP-Adressen in MAC-Adressen wird das Address Resolution Protocol (ARP) verwendet. Befindet sich der Empfänger in einem anderen Subnetz, ändern Router Quell-und Ziel-MAC-Adresse, um das Paket weiterzuleiten.
Die TTL ist eine Zahl, welche von jedem Router, über den das Paket wandert, um 1 reduziert wird. Sie soll verhindern, dass Pakete ziellos im Netzwerk umherwandern. Erreicht sie 0, wird das Paket vom nächsten Router verworfen, den es erreicht. Bei ungünstigen Routen kann es unter Umständen sein, dass Pakete ihr Ziel nicht erreichen können, weil zwischen Sender und Empfänger zu viele Hops (Router) liegen.
Routingtabellen
Anhand ihrer Routingtabellen entscheiden Router und Clients, wohin sie ihre Pakete schicken, damit diese am Ziel ankommen. In der Routingtabelle stehen also folglich alle Ziele und wie diese erreicht werden können.
Ein Client mit Windows/Linux/Mac routet in der Standardeinstellung nicht, d.h. er leitet keine Pakete anhand seiner Routingtabelle weiter, die er erhält, auch wenn er den Weg zum Ziel kennt. Dafür benötigt man eine Routing-Software oder einen Router in Hardware.
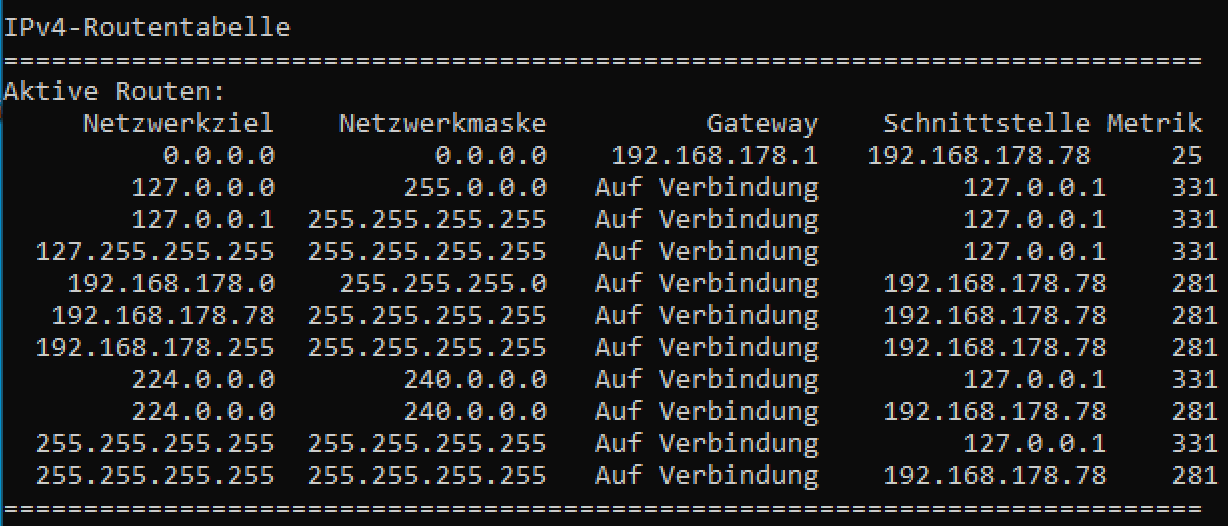
Ein Eintrag in einer Routingtabelle besteht aus folgenden Angaben:
| Ziel | Adresse des zu erreichenden Empfängers (dies kann die Adresse eines Subnetzes oder eines Hosts sein) |
| Netzwerkmaske |
Subnetzmaske des Ziels 0.0.0.0 (CIDR /0) ist keine Netzmaske 255.255.255.255 (CIDR /32) schließt nur die IP des Ziels ein |
| Gateway bzw. next hop | Adresse, an welche ein Paket für den Empfänger geschickt werden soll |
| Schnittstelle | über welches Interface soll das Paket geschickt werden |
| Metrik | Kann das Ziel über 2 Routen erreicht werden, bestimmt die Metrik, welche Route genommen wird. Die Metrik einer Route kann anhand von verschiedenen Parametern bestimmt werden, z.B. der Anzahl der Hops zum Ziel oder der Geschwindgkeit der Route. Die Route mit der geringeren Metrik wird bevorzugt. |
Einsehen und Ändern der Routingtabelle
Unter Windows gibt es den Befehl "route" zum Einsehen und Ändern der Routingtabelle. Dessen grundlegende Syntax sieht folgendermaßen aus:
route [<command> [<destination>] [mask <netmask>] [<gateway>] [metric <metric>] [if <interface>]]Der Befehl kennt folgende "commands":
| gibt einen (bei Angabe eines Ziels), ansonsten alle Einträge der Routingtabelle aus | |
| add | Hinzufügen einer statischen Route (Angabe des Ziels ist notwendig) |
| delete | Löscht eine Route in der Routingtabelle (Angabe des Ziels ist notwendig) |
| change | Ändert einen Eintrag in der Routingtabelle (Angabe des Ziels ist notwendig) |
Besondere Ziele
Default-Route
Das Ziel 0.0.0.0/0 in einer Routingtabelle steht für die Default-Route. Ist kein passender Eintrag für ein Paket vorhanden, wird die IP-Adresse des Gateways dieses Eintrags mittels ARP-Protokoll aufgelöst und als Empfänger die ermittelte MAC-Adresse in das Ethernet-Frame eingetragen. Es können mehrere Default-Routen definiert sein, um den Ausfall eines Gateways zu kompensieren.
Loopback
Das Netz 127.0.0.0/8 bzw. 127.0.0.0 mit Subnetzmaske 255.0.0.0, also die IP-Adressen 127.0.0.1 bis 127.255.255.255, ist für Loopback-Traffic reserviert. Dieser verlässt das Interface nicht, sondern wird intern an es zurückgeschickt.
Limited Broadcast
Die IP-Adresse 255.255.255.255 mit der Subnetzmaske 255.255.255.255 (CIDR: /32) ist eine spezielle IP-Adresse, welche zum Limited Broadcast gehört. Ein Paket, welches an diese IP-Adresse geschickt wird, wird an alle Geräte im Subnetz geschickt. Es verlässt das aktuelle Subnetz nicht und kann nicht geroutet werden. Jedes Netz, mit dem das Gerät verbunden ist, hat einen Eintrag mit der Limited Broadcast Adresse.
Multicast
Das Netz 224.0.0.0 mit der Subnetzmaske 240.0.0.0 bzw. 240.0.0.0/4 (CIDR) ist für Multicast reserviert, d.h. für Traffic, welche an eine Gruppe von Systemen gerichtet ist, z.B. an alle Router oder alle DHCP-Server in einem Netz. Jedes Netz hat einen Eintrag für das Multicast-Netz.
Lesen einer Routing Tabelle anhand eines Beispiels
Die Einträge der Routingtabelle aus der oberen Abbildung haben die folgenden Bedeutungen.
| Ziel |
Netzwerkmaske | Gateway/Next Hop | Schnittstelle |
Metrik |
Bedeutung |
| 0.0.0.0 | 0.0.0.0 | 192.168.178.1 | 192.168.178.78 |
25 |
Pakete ohne expliziten Eintrag werden an 192.168.178.1 über das Interface mit der IP 192.168.178.78 gesendet (Default Route) |
| 127.0.0.0 | 255.0.0.0 |
- | 127.0.0.1 |
331 |
Pakete an das Loopback-Netz werden über das Interface mit der IP 127.0.0.1 gesendet |
| 127.0.0.1 | 255.255.255.255 | - | 127.0.0.1 |
331 |
Pakete an die Loopback-Adresse 127.0.0.1 werden über das Interface mit der IP 127.0.0.1 gesendet |
| 127.255.255.255 | 255.255.255.255 |
- | 127.0.0.1 |
331 |
Pakete an die Broadcast-Adresse des Loopback-Netzes werden über das Interface mit der IP 127.0.0.1 gesendet (directed broadcast) |
| 192.168.178.0 | 255.255.255.0 | - |
192.168.178.78 |
281 |
Pakete an das Netz 192.168.178.X werden über das Interface mit der IP 192.168.178.78 gesendet |
| 192.168.178.78 | 255.255.255.255 | - | 127.0.0.1 |
281 | Pakete an die eigene IP 192.168.178.78 werden über das Interface mit der IP 127.0.0.1 gesendet |
| 192.168.178.255 |
255.255.255.255 | - |
192.168.178.78 |
281 |
Pakete an die Broadcast-Adresse des Netzes 192.168.178.X werden über das Interface mit der IP 192.168.178.78 gesendet |
| 224.0.0.0 | 240.0.0.0 | - |
127.0.0.1 |
331 |
Pakete an das Multicast-Netz werden über das Interface mit der IP 127.0.0.1 gesendet |
| 224.0.0.0 | 240.0.0.0 | - | 192.168.178.78 |
281 |
Pakete an das Multicast-Netz werden bevorzugt (Metrik 281 vs 331) über das Interface mit der IP 192.168.178.78 gesendet |
| 255.255.255.255 | 255.255.255.255 | - | 127.0.0.1 |
331 |
Pakete an die Limited Broadcast IP werden über das Interface mit der IP 127.0.0.1 gesendet |
| 255.255.255.255 |
255.255.255.255 |
- |
192.168.178.78 |
281 |
Pakete an die Limited Broadcast IP werden bevorzugt (Metrik 281 vs 331) über das Interface mit der IP 192.168.178.78 gesendet |
Wie kommen Routen in die Routing-Tabelle
Direkt angeschlossene Netze
Wird einem Interface eine IP mit Subnetzmaske zugewiesen, werden für dieses Netzwerk automatisch Einträge in der Routingtabelle generiert.
Statisches Routing
Routen können manuell in die Routingtabelle eingetragen werden. Unter Windows geschieht dies unter anderem mit dem oben erklärten "route" Befehl.
Dynamisches Routing
Bei weit verzweigten Netzwerken wie dem Internet ist das manuelle Pflegen der Routingtabellen äußerst aufwändig und fehleranfällig. Stattdessen gibt es Protokolle (BGP Border Gateway Protocol, OSPF Open Shortest Path First, RIP Router Information Protocol, IGRP Interior Gateway Routing Protocol), welche es Routern erlauben, ihre Routingtabellen durch den Austausch von Informationen mit anderen Routern dynamisch aufzubauen. Beim dynamischen Routing kommen im Wesentlichen 2 Algorithmen zum Einsatz:
Beim Distance Vector Algortihmus sendet jeder Router seine Routingtabelle regelmäßig via Broadcast an alle anderen Router im Netz, welche mit diesen Informationen ihre eigene Routingtabelle ergänzen. Da dies recht ineffizient ist und zu einem hohen Paketaufkommen innerhalb eines Netzwerks sorgt (Broadcastlawine), wurden einige Erweiterungen implementiert.
Beim Link State Algorithmus verursacht eine Änderung eines Routingeintrags ein Link State Announcement, welches an alle benachbarten Router geschickt wird. Diese ergänzen dadurch ihre Routintabelle. Da bei diesem Algorithmus nur bei Veränderungen Informationen ausgetauscht werden, ist dieser Algorithmus sehr effizient. Er ist die Implementierung des Djikstra-Algorithmus.
VPN (E2E, E2S, S2S)
VPN bedeutet Virtuelles Privates Netzwerk (aus dem Englischen „Virtual Private Network“). Eine VPN-Verbindung bietet die Möglichkeit, von außen auf ein bestehendes Netzwerk zuzugreifen. Dabei kann es sich um ein Unternehmens- aber auch um ein privates Netzwerk handeln.
Grundsätzlich gibt es drei Arten von VPNs, die in verschiedenen Szenarien zum Einsatz kommen.
End-to-End-VPN
Bei einem End-to-End-VPN werden zwei Clients miteinander verbunden. Dabei befindet sich ein Client innerhalb eines Netzwerks, der andere hingegen außerhalb. Diese Art von VPN ermöglicht beispielsweise den direkten Zugang zu einem Server im Netzwerk.
Um einen solchen VPN-Tunnel herzustellen, ist jedoch auf beiden Clients eine VPN-Software erforderlich. Die Verbindung wird allerdings nicht direkt hergestellt. Stattdessen geht man den Umweg über ein Gateway, mit dem sich beide Clients verbinden. Das Gateway sorgt dann dafür, dass die zwei aufgebauten Verbindungen zusammengeschaltet werden und eine direkte Kommunikation erfolgen kann.
End-to-Site-VPN
Über ein End-to-Site-VPN wird ein einzelner Client außerhalb eines Netzwerkes mit einem Unternehmensnetzwerk verbunden. Auch hier bedient man sich wiederum der öffentlichen Internetverbindung, um sich in das Unternehmensnetzwerk einzuwählen.
Verwendet wird diese Art von VPN beispielsweise für Heimarbeiter oder mobile Außendienstmitarbeiter, die sich von zuhause oder vom Kundentermin aus per Remote Access mit dem Unternehmensnetzwerk verbinden. Sie können es dann so nutzen als würden sie gerade im Betrieb sitzen.
Site-to-Site-VPN
Bei einem Site-to-Site-VPN werden mehrere lokale Netzwerke zusammengeschlossen. Im Gegensatz zur herkömmlichen Standleitung, die eine physikalische Verbindung zwischen den zwei Netzwerken herstellt, wird beim Site-to-Site-VPN eine Internetverbindung herangezogen. Dadurch können die hohen Kosten eingespart werden, die eine Standleitung mit sich bringt. Auf diese Weise können beispielsweise die lokalen Netzwerke eines Unternehmens mit mehreren Filialen oder Betrieben miteinander kommunizieren.
MPLS-VPN
Es handelt sich um ein in sich geschlossenes, privates IP-Netz, das vom Anbieter zur Verfügung gestellt und komplett gemanagt wird. MPLS (Multiprotocol Label Switching) ist eine Kombination von Switching und Routing. Bei MPLS ist der Transportweg von Datenpaketen im Unterschied zur „normalen“ Internet-Übertragung vorgegeben. Es handelt sich somit um eine Lösung, die die verbindungsorientierte Übertragung von Datenpaketen in einem eigentlich verbindungslosen Netz ermöglicht. So werden unnötige Umwege oder falsche Paketreihenfolgen bei der Datenübertragung beispielsweise zwischen Unternehmensstandorten verhindert. Auf diese Weise entstehen vordefinierte Pfade, da Pakete mit dem gleichen Label immer den gleichen Weg nehmen.
Vor- und Nachteile eines MPLS-VPN:
| + Stabile Qualität | – Höhere Kosten |
| + Gesicherte Bandbreite | – Weniger Flexibilität |
| + Geringer betrieblicher Aufwand |
Vorteile von VPN
- Kosteneinsparung durch Verzicht auf eine physikalische Standleitung
- Hohe Verfügbarkeit durch gute Netzabdeckung
- Höhere Abhörsicherheit
- Verschlüsselte Datenübertragung
- Bedienerfreundlichkeit
Neben diesen Vorteilen haben VPN außerdem den großen Vorteil, dass sie ohne großen Aufwand eingesetzt werden können. Es bedarf lediglich eines entsprechenden Clients, um sichere Verbindungen herzustellen.
Nachteile von VPN
- Geschwindigkeitseinbußen
- Webseiten-Blockaden
- Dubiose Anbieter
Transport vs Tunnel Mode
Im Transport Mode kommunizieren zwei Hosts direkt via Internet miteinander. In diesem Szenario lässt sich IPsec zum einen dazu nutzen, die Authentizität und Integrität der zu gewährleisten. Man kann also nicht nur sicher sein, mit wem man da gerade kommuniziert, sondern sich auch darauf verlassen, dass die Pakete nicht unterwegs verändert wurden. Per optionaler Verschlüsselung kann man zudem verhindern, dass Unbefugte die transportierten Inhalte mitlesen. Da hier zwei Rechner direkt über ein frei zugängliches Netz miteinander Daten austauschen, lassen sich jedoch Ursprung und Ziel des Datenstroms nicht verschleiern.
Der Tunnel Mode kommt stets dann zum Einsatz, wenn zumindest einer der beteiligten Rechner nicht direkt angesprochen, sondern als Security Gateway genutzt wird. In diesem Fall bleibt zumindest einer der Kommunikationspartner - der hinter dem Gateway - anonym. Tauschen gar zwei Netze über ihre Security Gateways Daten aus, dann lässt sich von außen gar nicht mehr bestimmen, welche Rechner hier tatsächlich miteinander sprechen. Auch im Tunnel Mode lassen sich natürlich Authentifizierung, Integritätskontrolle und Verschlüsselung einsetzen.
IT-Security
IT-Sicherheit reicht vom Schutz einzelner Dateien bis hin zur Absicherung von Rechenzentren und Cloud-Diensten. IT-Security gehört zu jeder Planung und Maßnahme in der IT und ist grundlegend für die Compliance im Unternehmen.
Unter IT-Sicherheit versteht man alle Planungen, Maßnahmen und Kontrollen, die dem Schutz der IT dienen. Der Schutz der IT hat drei klassische Ziele: Die Vertraulichkeit der Informationen, die Integrität der Informationen und Systeme und die Verfügbarkeit der Informationen und Systeme. Der Schutz der IT-Systeme vor Ausfall und die notwendige Belastbarkeit der IT-Systeme ist grundlegend für die Aufrechterhaltung des Geschäftsbetriebs, für die „Business Continuity“.
Im Gegensatz zur Datensicherheit geht es in der IT-Sicherheit nicht nur um personenbezogene Daten, für die der rechtlich geforderte Datenschutz Sicherheitsmaßnahmen verlangt. Es geht vielmehr um alle Arten von Informationen, die es zu schützen gilt.
Informationssicherheit
In der Informationssicherheit geht es allgemein um den Schutz von Informationen. Diese können auch in nicht-technischen Systemen vorliegen, zum Beispiel auf Papier. Die Schutzziele der Informationssicherheit bestehen darin, die Vertraulichkeit, Integrität und Verfügbarkeit von Informationen sicherzustellen.
In Deutschland gilt der IT-Grundschutz des Bundesamts für Sicherheit in der Informationstechnik (BSI) als Leitlinie für die Informationssicherheit.
Im Anhang A der ISO 27001 gibt es eine Liste von 114 Sicherheitsmaßnahmen zur Überprüfung des Sicherheitsniveaus in Unternehmen, sogenannte Controls. Zum Schutz des geistigen Eigentums können wir diese hier nicht einfach auflisten. Die 14 Abschnitte des Anhang A mit kurzer Erklärung:
- A.5 Informationssicherheitspolitik – Kontrollen, wie die Politik geschrieben und überprüft ist
- A.6 Organisation der Informationssicherheit – Kontrollen, wie die Verantwortlichkeiten zugewiesen sind, enthält auch die Kontrollen für Mobilgeräte und Telearbeit
- A.7 Personalsicherheit – Kontrollen vor, während und nach der Anstellung
- A.8 Asset Management – Kontrollen in Bezug auf das Asset-Verzeichnis und akzeptable Nutzung sowie auch für Informationsklassifizierung und Medien-Handhabung
- A.9 Zugriffskontrolle – Kontrollen für die Zugriffskontrollen-Richtlinie, die Benutzerzugriffsverwaltung, System- und Applikations-Zugriffskontrolle sowie Anwenderverantwortlichkeiten
- A.10 Kryptografie – Kontrollen in Bezug auf Verschlüsselung und Schlüsselverwaltung
- A.11 Physische und Umgebungssicherheit – Kontrollen, die Sicherheitsbereiche, Zutrittskontrollen, Schutz gegen Bedrohungen, Gerätesicherheit, sichere Entsorgung, Clear Desk- und Clear Screen-Richtlinie usw. definieren
- A.12 Betriebssicherheit – eine Menge an Kontrollen im Zusammenhang mit dem Management der IT-Produktion: Change Management, Capacity Management, Malware, Backup, Protokollierung, Überwachung, Installation, Schwachstellen usw.
- A.13 Kommunikationssicherheit – Kontrollen in Bezug auf Netzwerksicherheit, Segregation, Netzwerk-Services, Informationstransfer, Nachrichtenübermittlung etc.
- A.14 Systemerwerb, Entwicklung und Wartung – Kontrollen, die Sicherheitsanforderungen und die Sicherheit in Entwicklungs- und Support-Prozessen definieren
- A.15 Lieferantenbeziehungen – Kontrollen, was in Vereinbarungen zu inkludieren ist und wie die Lieferanten zu überwachen sind
- A.16 Informationssicherheits-Störfallmanagement – Kontrollen für die Meldung von Vorfällen und Gebrechen, welche die Verantwortlichkeiten, Sofortmaßnahmen und Sammlung von Beweisen definieren
- A.17 Informationssicherheitsaspekte des betrieblichen Kontinuitätsmanagements – Kontrollen, welche die Planung von Betriebskontinuität, Verfahren, Verifizierung und Überprüfung sowie der IT-Redundanz verlangen
- A.18 Compliance/Konformität – Kontrollen, welche die Identifizierung anwendbarer Gesetze und Bestimmungen, des Schutzes geistigen Eigentums, des Schutzes persönlicher Daten und die Überprüfung der Informationssicherheit verlangen
Datensicherheit
Datensicherheit hat das Ziel, die Vertraulichkeit, Integrität und Verfügbarkeit von Daten sicherzustellen. Im Unterschied zum Datenschutz beschränkt sie sich nicht auf personenbezogene Daten, sondern erstreckt sich auf alle Daten. Vertraulichkeit bedeutet, dass nur befugte Personen auf die Daten zugreifen können. Integrität heißt: Die Daten wurden nicht manipuliert oder beschädigt. Die Verfügbarkeit bezieht sich darauf, dass Daten verwendet werden können, wenn man sie benötigt. Um Datensicherheit zu etablieren, sind verschiedene technische und organisatorische Maßnahmen nötig, zum Beispiel Zugriffskontrollen, Kryptografie oder redundante Speichersysteme.
Um Datensicherheit zu etablieren, sind verschiedene technische und organisatorische Maßnahmen nötig, zum Beispiel Zugriffskontrollen, Kryptografie oder redundante Speichersysteme.
Information Security Management System (ISMS)
Ein Informationssicherheits-Management-System, auf Englisch „Information Security Management System (ISMS)“, ist kein technisches System, sondern definiert Regeln und Methoden, um die Informationssicherheit zu gewährleisten, zu überprüfen und kontinuierlich zu verbessern. Das umfasst unter anderem die Ermittlung und Bewertung von Risiken, die Festlegung von Sicherheitszielen sowie eine klare Definition und Dokumentation von Verantwortlichkeiten, Kommunikationswegen und Abläufen.
Cyber-Resilienz
Unter Cyber-Resilienz versteht man die Fähigkeit eines Unternehmens oder einer Organisation, ihre Geschäftsprozesse trotz widriger Cyber-Umstände aufrechtzuerhalten. Das können Cyber-Angriffe sein, aber auch unbeabsichtigte Hindernisse wie ein fehlgeschlagenes Software-Update oder menschliches Versagen. Cyber-Resilienz ist ein umfassendes Konzept, das über die IT-Sicherheit hinausgeht. Es vereint die Bereiche Informationssicherheit, Business-Kontinuität und organisatorische Resilienz. Um einen Zustand der Cyber-Resilienz zu erreichen, ist es wichtig, Schwachstellen frühzeitig zu erkennen, sie wirtschaftlich zu priorisieren und zu beseitigen.
Authentisierung, Authentifizierung und Autorisierung
Die Authentisierung stellt den Nachweis einer Person dar, dass sie tatsächlich diejenige Person ist, die sie vorgibt zu sein. Eine Person legt also Nachweise vor, die ihre Identität bestätigen sollen.
Die Authentifizierung stellt eine Prüfung der behaupteten Authentisierung dar. Bei der Authentifizierung ist nun der Prüfer an der Reihe. Er überprüft die Angaben auf ihre Echtheit. Zeitlich betrachtet findet eine „Authentifizierung“ also nach einer „Authentisierung“ statt.
Die Autorisierung ist die Einräumung von speziellen Rechten. War die Identifizierung einer Person erfolgreich, heißt es noch nicht automatisch, dass diese Person bereitgestellte Dienste und Leistungen nutzen darf. Darüber entscheidet die Autorisierung.
Schutzbedarfsstufen
| normal | hoch | sehr hoch |
|---|---|---|
| Die Schadensauswirkungen sind begrenzt und überschaubar. | Die Schadensauswirkungen können beträchtlich sein. | Die Schadensauswirkungen können ein existenziell bedrohliches, katastrophales Ausmaß erreichen. |
Beispiele für Sicherheitstests / Penetrationstest / Eindringungstest / Juckts im Schritt?
- Überprüfung der vom Kunden zur Verfügung gestellten Daten auf Korrektheit
- Identifizierung von Betriebssystemen und erreichbaren Diensten
- Test der erkannten Dienste mit Schwachstellenscannern
- Überprüfung der Ergebnisse, Verifizierung von erkannten Sicherheitslücken
- Einsatz von Werkzeugen, die Gebiete abdecken, die von Schwachstellenscannern nicht berücksichtigt werden
- Manuelle Prüfungen
- Nachweis von DoS-Potenzialen nach Absprache mit dem Kunden
Backupstrategien
Allgemeines
Bevor man über eine Backupstrategie nachdenkt, sollte grundsätzlich immer zunächst einmal analysiert werden, wie hoch der Schutzbedarf der Daten ist und welche gesichert werden sollten. Sobald dies getan ist, sollten Überlegungen angestellt werden, wie wichtig die Integrität der Daten ist und wie hoch der Kostenfaktor des Backups sein sollte / darf. Danach kann sich für eine bestimmte Art Backup entschieden werden und sich eine für sich passende Strategie überlegt werden.
Backuparten
Es gibt im Wesentlichen drei verschiedene Arten von Backups. Diese unterscheiden sich jeweils in der Zugriffsgeschwindigkeit und dem Speicherbedarf.
| Bezeichnung |
Funktionsweise |
Speicherbedarf |
Geschwindigkeit |
Schutz |
| Full Backup |
Hierbei werden immer alle Daten gesichert, egal ob sie sich verändert haben oder nicht. Da einfach der komplette Datenbestand kopiert wird, handelt es sich hierbei um ein nicht sonderlich komplexes Backup. |
Ist bei dieser Variante sehr hoch. |
Sehr langsam, da immer alle Daten aufs neue kopiert werden. |
Hoher Schutzfaktor vor Datenverlust, da eine hohe Redundanz vorhanden ist. |
| Differenzielles Backup |
Hierbei wird zunächst ein Full Backup zugrunde gelegt. Danach werden dann immer nur die Änderungen gespeichert. Sollte es mehrere solcher Backups geben, sind diese unabhängig voneinander. |
Ist deutlich weniger als bei Full Backups. |
Deutlich schneller als ein Full Backup. |
Nicht ganz so gut wie bei einem Full Backup, da es hier zu Problemen kommen kann, wenn das Initialbackup beschädigt ist. |
| Inkrementelles Backup |
Hierbei handelt es sich um viele kleine Backups, die immer wieder aufeinander aufbauen. Dieser „Kette“ liegt gewöhnlich ein Full Backup zugrunde. |
Sehr gering. |
Sehr schnell, da nur kleine Datenmengen. | Leider ist dieser hier sehr gering, da die Backups aufeinander aufbauen. Sollte eines in der Kette beschädigt sein, sind alle folgenden auch nicht zu gebrauchen. |
Backupsysteme
Es gibt die verschiedensten Arten von Backups, die je nach Schutzbedarf und Kostenfaktor kombiniert werden können / sollten.
Hierbei sind grundsätzlich Langzeit und Kurzzeit Backups voneinander zu unterscheiden.
Bei den Langzeitbackups ist es meist nicht wichtig, dass schnell auf die Daten zugegriffen werden kann. Daher kommen hier meistens Techniken wie z. B. Bänder zum Einsatz. Es gibt allerdings auch Langzeitbackups auf Festplatten.
Sollen Daten jedoch nur kurze Zeit gespeichert werden, werden die Backups vorwiegend auf Festplatten vorgenommen, da hier ein schneller Zugriff auf die Daten möglich ist.
Des Weiteren ist es in Betracht zu ziehen, dass das gesamte Gebäude abbrennen oder anderweitig zerstört werden könnte. Hier kann nur ein sogenanntes Offsitebackup Abhilfe schaffen. Dieses sollte sich idealerweise weit genug entfernt befinden, um bei Naturkatastrophen nicht auch betroffen zu sein. Des Weiteren ist hier meist ein externer Datenzugriff nicht auszuschließen. Daher sollte man sich bei einem Offsitebackup auch davor schützen.
Zusätzlich kann ein Backup nicht nur vor Datenverlust schützen, sondern auch vor Datenänderung. Hierzu sollte ein Speichermedium genutzt werden, das sich nicht mehr oder erst nach einer bestimmten Zeit wieder überschreiben lässt. Dies ist sowohl bei Bändern als auch bei Festplatten (durch Software) möglich. Möchte man noch eine Stufe weiter gehen, so ist es auch möglich Daten, die gesichert werden sollen, vor der Sicherung auf Schadsoftware und unbefugte Änderung zu prüfen.
Backupstrategie
Eine universelle ideale Backupstrategie gibt es nicht. Jede Backupstrategie muss individuell aus den verschiedenen Backuparten und Backupsystemen zusammengestellt werden. Hierbei spielen Faktoren wie Sicherheit, Zeit, Wiederanlaufzeit, Speicherbedarf, Kosten oder auch die Internetgeschwindigkeit eine große Rolle. Des weiteren ist zu beachten, dass Raid kein Backup ist!
Eine Häufig angewendete Strategie ist die sogenannte 3-2-1 Regel.
Hierbei werden von allen wichtigen Daten 3 Kopien angefertigt. Diese sollten auf mindestens 2 unterschiedlichen Speichermedien gemacht werden. Eines der drei Medien wird dann an einen anderen Ort gesendet, um ein Offsite Backup zu realisieren.
DMZ
Eine demilitarisierte Zone bezeichnet ein Computernetz mit sicherheitstechnisch kontrollierten Zugriffsmöglichkeiten auf die daran angeschlossenen Server.
Die in der DMZ aufgestellten Systeme werden durch eine oder mehrere Firewalls gegen andere Netze (z. B. Internet, LAN) abgeschirmt. Durch diese Trennung kann der Zugriff auf öffentlich erreichbare Dienste gestattet und gleichzeitig das interne Netz (LAN) vor unberechtigten Zugriffen von außen geschützt werden.
Der Sinn besteht darin, auf möglichst sicherer Basis Dienste des Rechnerverbundes sowohl dem WAN (Internet) als auch dem LAN (Intranet) zur Verfügung zu stellen.
Ihre Schutzwirkung entfaltet eine DMZ durch die Isolation eines Systems gegenüber zwei oder mehr Netzen.
- DMZ = Demilitarisierte Zone
- Bezeichnung für ein Computernetzwerk mit kontrollierten Zugriffsmöglichkeiten auf die daran angeschlossenen Server
- Abgrenzung gegenüber anderen Netzen mithilfe von Firewalls
- Ermöglicht den Zugriff auf die gleichen Server sowohl aus dem Internet (WAN) als auch dem Intranet (LAN)
- Verbindungsaufbau sollte immer aus dem internen Netz in die DMZ erfolgen und nicht umgekehrt
|
DMZ mit einstufigem Firewall-Konzept |
DMZ mit zweistufigem Firewall-Konzept |
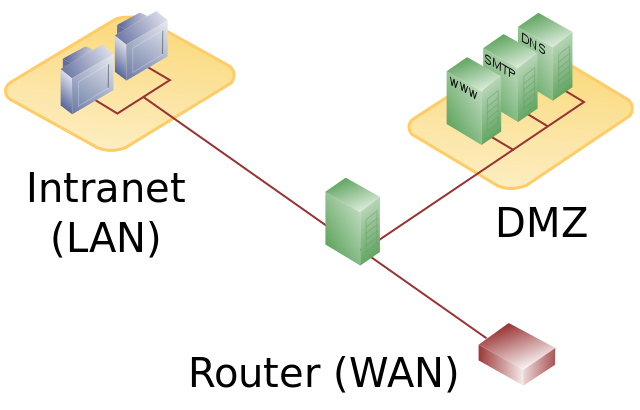 |
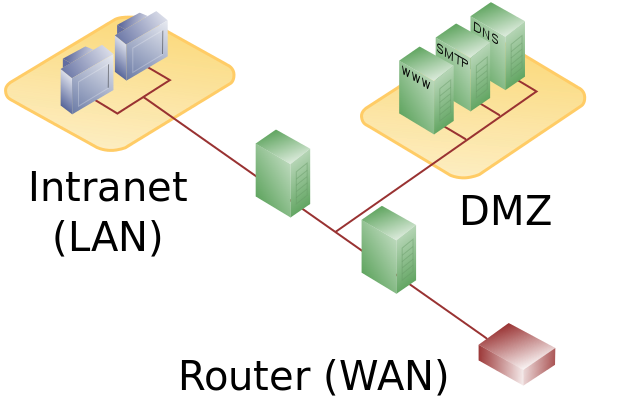 |
Proxy
Proxy bedeutet Stellvertreter. Ein Proxy-Server tritt anstelle eines anderen Systems in Erscheinung. Ein Proxy kann allen Traffic oder nur bestimmten Traffic weiterleiten, z.B. nur HTTP/HTTPS-Traffic (Web-Proxy).
Proxy-Server

Ein normaler Proxy-Server wird Clients vorgeschaltet. Ein Client sendet seinen Traffic an den Proxy-Server, welcher den Traffic seinerseits mit seiner eigenen IP-Adresse weiterleitet. Der Empfänger, z. B. ein Web-Server, erhält die Anfrage und schickt seine Antwort an den Proxy-Server. Dieser ersetzt im Paket seine IP-Adresse durch die des Clients und schickt das Paket an diesen zurück.
Durch einen solchen Proxy-Server wird die IP-Adresse des Clients vor dem Empfänger des Pakets verborgen, was ein Nachverfolgen einer Anfrage erschwert. Proxy-Server können aber auch noch andere Funktionalität bereitstellen, z. B. kann der Web-Proxy Squid als Cache-Server für Webseiten fungieren, was zumindest die Anzahl der Anfragen auf das Internet reduziert und zumindest theoretisch das Netzwerk entlastet. Auch Funktionen zur Kontrolle von Traffic (Access Control, Routing) sind über einen Proxy-Server implementierbar.
Reverse Proxy-Server

Die andere Art eines Proxy-Servers sind sogenannte Reverse Proxy-Server. Reverse Proxy-Server werden Servern vorgeschaltet. Der Client schickt seine Anfrage nicht direkt an das Backend (hier Web-Server), sondern an den Reverse Proxy-Server. Dieser leitet die Anfragen an das Backend weiter, z. B. den Web-Server, und liefert anschließend die Antwort an den Client zurück.
Durch einen Reverse Proxy werden die IP-Adressen des Backends vor dem Client verborgen, was die Sicherheit erhöht. Ein Reverse Proxy kann außerdem Funktionen zur Lastverteilung (dadurch High Availability), DoS Protection etc. implementieren.
Squid kann sowohl als Proxy-Server als auch als Reverse Proxy konfiguriert werden. Wikipedia nutzt Squid als Reverse Proxy mit aktiviertem HTTP/HTTPS-Cache und reduziert so die Anfragen auf die Web-Server, da eine Seite im Cache nicht von den Web-Servern bezogen werden muss.
Es ist auch möglich, Proxy-Server und Reverse Proxy-Server zu verketten. (kaskadierender Proxy)
Zertifikate
Einsatzzweck
Zertifikate werden im Allgemeinen verwendet, um die Echtheit von Daten zu beweisen. Daten können hierbei E-Mails, Dokumente, Software / Updates, Webdaten oder gar ganze Verbindungen wie z. B. bei einem VPN sein.
Funktionsweise
Damit Zertifikate funktionieren, sind in der Regel zwei Dinge notwendig. Zum einen wird eine Zertifizierungsstelle (Certification Authority oder auch CA) benötigt. Diese vergibt die Zertifikate und stellt sicher, dass derjenige der das Zertifikat beantragt auch der ist, der zu dem Zertifikat hinterlegt ist. Hierbei gibt es verschiedenste Stufen der Überprüfung, denn nicht jedes Zertifikat ist gleich vertrauenswürdig.
Des Weiteren ist, um die Zertifikate überprüfen zu können, eine sogenannte Public Key Infrastruktur, kurz PKI notwendig. Sie vereinfacht den Austausch von Zertifikaten dahingehend, dass es ein Root Zertifikat gibt, dem vertraut wird. Alle Zertifikate, die mit diesem signiert wurden, können als vertrauenswürdig betrachtet werden, da bei der Signierung der Zertifikate die Ansprüche der Root CA zu erfüllen sind.
Das gesamte System der Zertifikate basiert auf der asymmetrischen Verschlüsselung, wobei das Zertifikat immer nur den Public Key enthält. Der jeweilige Private Key bleibt bei den signierenden Parteien.
Der Ablauf einer mit Zertifikaten signierten Verbindung ist folgender Grafik zu entnehmen.
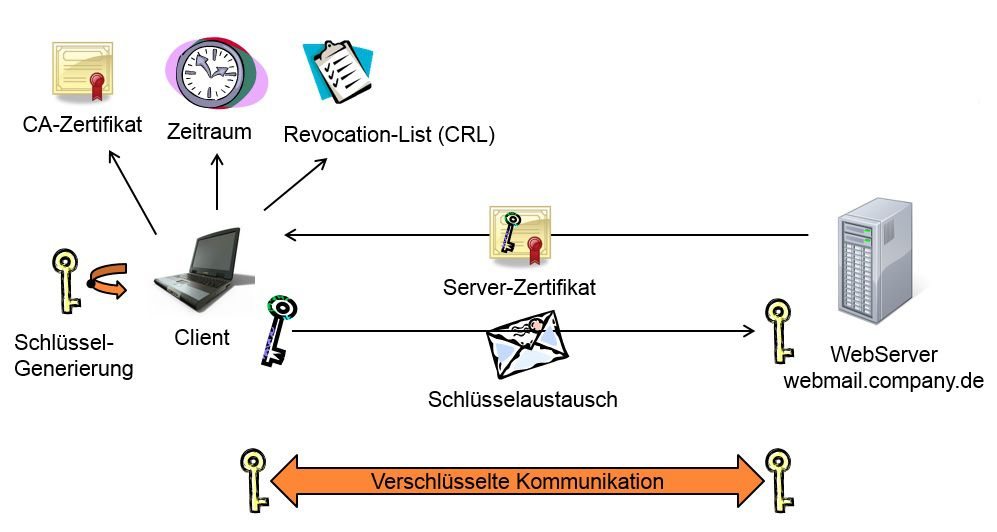
Symmetrisch / Asymmetrische Leitungen
Upstream
- Datenfluss vom Verbraucher zur Quelle
- zum Upload zur Verfügung stehende Bandbreite
- Anfragen, die von einem Client an einen Server gestellt werden
Downstream
- Datenfluss von der Quelle zum Verbraucher
- zum Download zur Verfügung stehende Bandbreite
- Antwort des Servers auf eine Anfrage des Clients
Asymmetrisch
- Upload und Download sind nicht gleich groß. Zur Verfügung stehende Bandbreite wird in ungleiche Bestandteile aufgeteilt.
- Beispiel: DSL, VDSL
- je nach zu erwartendem Datenverkehr wird Upload oder Download bevorzugt
- Beispiel:
- Haushaltsanschlüsse haben oft einen hohen Download und einen niedrigen Upload
- Streamingdienste brauchen einen deutlich höheren Upload
Symmetrisch
- Upload und Download sind gleich groß
- Bandbreite ist nicht aufgeteilt und in beide Richtungen konstant
- Beispiele: Glasfaseranschlüsse
RAID-Level
Definition
Ein RAID (Redundant Array of Independent Disks) ist ein Verbund zwei oder mehr verschiedenen Speichermedien zu einem einzelnen logischen Laufwerk. Die konkrete Funktion bestimmen die jeweiligen Festplatten-Setups, die man auch als RAID-Level bezeichnet.
Das primäre Ziel von einem RAID ist es, die Sicherheit gespeicherter Daten zu erhöhen. Ausfälle einzelner Festplatten sollen auf diese Weise kompensiert werden und nicht zu Datenverlust führen. Hierfür setzen die einzelnen RAID-Level verschiedene Techniken ein, um Dateien redundant zu speichern. Das klassische Verfahren ist beispielsweise die Spiegelung aller Daten. Alternativ setzen andere RAID-Level auf Paritätsinformationen, die gemeinsam mit den Nutzdaten auf den eingebundenen Datenträgern gespeichert werden und – im Falle eines defekten Speichermediums – die schnelle und einfache Wiederherstellung der Daten ermöglichen.
Ein RAID ist kein Backup-Ersatz: Die räumlich und zeitlich getrennte Speicherung von Dateien, die klassische Backups auszeichnen, ist in RAID-Verbunden nicht gegeben!
RAID: 0, 1,5, 6, 01, & 10 von Sunny Classroom
Spiegelung aller Daten
Alle Schreibzugriffe erfolgen parallel auf zwei Laufwerke, sodass jede Platte quasi ein Spiegelbild der anderen darstellt. Alle Daten stehen also doppelt zur Verfügung. Auch wenn eines der beiden Laufwerke komplett ausfällt, bleiben alle Nutzdaten erhalten. Allerdings steht bei RAID 1 nur die Hälfte der gesamten Plattenkapazität für die Speicherung zur Verfügung. Die Kosten der Datenhaltung verdoppeln sich also.
Paritätsinformationen
Ein Paritätsbit ist ein Prüfbit, das zur Fehlererkennung in der Paritätsprüfung eingesetzt wird. Dies wird sendeseitig zu den Datenbits hinzugefügt, wodurch die Bitsumme gerade oder ungerade wird. Empfangsseitig wird die Bitsumme überprüft. Entspricht die empfangene Bitsumme nicht der vorgegebenen Parität, - die beispielsweise gerade sein muss - dann liegt ein Übertragungsfehler vor. Eine gerade Parität ist dann gegeben, wenn durch das hinzugefügte Bit die Gesamtzahl der Einsen in einer Dateneinheit geradzahlig wird.
Ein RAID-Verbund nutzt erweiterte Versionen von Paritätschecks. Manche RAID-Level, etwa RAID 4 oder RAID 5, legen die Paritätsinformationen auf einem oder mehreren Laufwerken ab und können so das RAID wiederherstellen, wenn ein Laufwerk ausfällt. Wenn Daten auf ein RAID geschrieben werden, haben diese immer die korrekte Parität, da sie zuvor diverse Fehlerkorrekturchecks durchlaufen. Fällt ein Laufwerk in einem RAID-Verbund aus, kann das System die verlorenen Daten aus den auf den verbliebenen Laufwerken gespeicherten Informationen und den Paritätsinformationen rekonstruieren und auf ein Spare-Laufwerk schreiben.
Beispiel eine RAID 4/5/6 Parität
Paritätsinformationen in Fett und Rot (0111)
- Berechnen der Paritätsinformationen mittels eines XOR aus den Eingangsdaten von HDD 1 und HDD 2
- Ausfall der HDD 2
- Wiederherstellung der Informationen von HDD 2 aus Daten von HDD 1 und HDD 3 mittels XOR
| Schritt | HDD 1 | HDD 2 | HDD 3 |
| 1 | 1010 | 1101 | 0111 |
| 2 | 1010 | XXXX | 0111 |
| 3 | 1010 | 1101 | 0111 |
RAID-Level
| RAID 0 | RAID 1 | RAID 5 | RAID 6 | RAID 10 (1+0) | |
| Mindestanzahl an Festplatten | 2 | 2 | 3 | 4 | 4 |
| Verwendete Verfahren | Striping | Spiegelung (Mirroring) | Striping und Parität | Striping und doppelte Parität auf unterschiedlichenPlatten | Striping gespiegelter Daten |
| Ausfallsicherheit | niedrig | sehr hoch; Ausfall eines Laufwerks möglich | mittel; Ausfall eines Laufwerks möglich | hoch; Ausfall von zwei Laufwerken möglich | sehr hoch; Ausfall eines Laufwerks pro Sub-Array möglich |
| Speicherkapazität | 100 % | 50 % | 67 % (steigt mit jeder weiteren Platte) | 50 % (steigt mit jeder weiteren Platte) | 50 % |
| Geschwindigkeit beim Schreiben | sehr hoch | niedrig | mittel | niedrig | mittel |
| Geschwindigkeit beim Lesen | sehr hoch | mittel | hoch | hoch | sehr hoch |
| Kostenfaktor | niedrig | sehr hoch | mittel | hoch | sehr hoch |
IPv6
Was ist IPv6 und warum brauchen wir es?
IPv6 (Internet Protocol Version 6) ist ein auf Layer 3 stattfindendes Protokoll für die Übertragung und Vermittlung von Datenpaketen in einem paketorientiert arbeitenden Netzwerk wie dem Internet. Es soll das bisher verwendete IP-Protokoll Version 4 (IPv4) ablösen.
Das Internetprotokoll der Version 4 ist in vielen Bereichen veraltet und kann die Anforderungen moderner Netzwerke und netzwerkfähiger Applikationen nicht mehr im gewünschten Maß erfüllen. Es vereinfacht die Einrichtung und den Betrieb und ist direkt nach dem Start eines netzwerktauglichen Gerätes verfügbar. Zustands behaftete Verfahren zur Adressvergabe wie DHCP, die bei IP der Version 4 zum Einsatz kommen, werden überflüssig.
Im Vergleich zu den IP-Adressen der Version 4 mit 32 Bit Länge sind IPv6-Adressen 128 Bit lang. Sie bieten damit einen wesentlich größeren Adressraum und eine Lösung für die Adressknappheit von IPv4-Adressen im Internet.
Beispiel einer IPv6 Adresse
2001:0000:0000:0000:0080:ACDE:02CE:1234
- Acht Gruppen mit je 16 Bit, separiert mit Doppelpunkten
- Jede Gruppe hat vier Hexadezimalzeichen zu je 4 Bit
Jede in einer Gruppe vorausführende Null kann weggelassen werden
Somit würde die IPv6 Adresse wie folgt aussehen:
2001:0:0:0:80:ACDE:2CE:1234
Gruppen aus Nullen können wiederum durch zwei Doppelpunkte dargestellt werden. Dies darf aber nur ein mal angewendet werden. Es können also keine doppelten Paare aus Doppelpunkten verwendet werden!
Schlussendlich sieht unsere IPv6 Adresse dann wie folgt aus:
2001::80:ACDE:2CE:1234
Unterteilung der Gruppen
2001:0000:0000:0000:0080:ACDE:02CE:1234
| 2001:0000:0000:0000 | Network Prefix (Präfix oder Netz-ID) – Wobei dieses Modell weiter unterteilt werden kann. So können die letzten 8 Bits der Network Prefix die Subnet Prefix angeben. |
| 0080:ACDE:02CE:1234 | Interface Identifier (Suffix, IID oder EUI) |
Segmentierung: Präfix und Präfixlänge
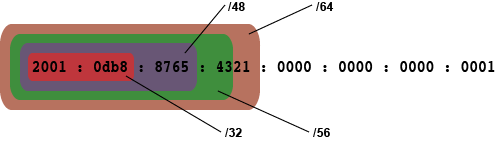
Die von IPv4 bekannte Netzmaske bzw. Subnetzmaske fällt bei IPv6 ersatzlos weg. Um trotzdem eine Segmentierung und Aufteilung von Adressbereichen bzw. Subnetzen vornehmen zu können, wird die Präfixlänge definiert und mit einem / an die eigentliche IPv6-Adresse angehängt. Der hierarchische Aufbau des Präfixes soll das Routing mit IPv6 vereinfachen.
Standardmäßig ist /64 die Präfixlänge. Es gibt jedoch weitere typische Präfixe, die 32, 48 und 56 Bit lang sind.
IPv6-Address-Scopes (Gültigkeitsbereiche)
| Unicast | Link-Local-Adressen (Verbindungslokale Unicast-Adressen) sind nur innerhalb von geschlossenen Netzsegmenten gültig. Router dürfen Datenpakete mit Link-Local Adressen als Quelle oder Ziel nicht an andere Links weiterleiten. Präfix: fe80::/10 |
| Multicast-Adressen | Eine Multicast-Adresse ist ein Identifier für eine Gruppe von Geräten. Jedes Gerät kann zu beliebig vielen Multicast-Gruppen gehören. Präfix: ff00::/8 |
| Anycast-Adressen | Im IPv6 wurde ein neuer Adresstyp "Anycast" definiert. Dieser Adresstyp erlaubt es, dass Datenpakete zu einem oder mehreren Geräten mit gleicher Adresse geroutet werden. Anycast-Adressen können einem oder mehreren, typischerweise an unterschiedlichen Geräten befindlichen, Netzwerk-Interfaces zugewiesen werden. Die Routing-Protokolle liefern jedes Paket zum nächsten Interface. |
SLAAC und DAD
Stateless Address Autoconfiguration (SLAAC) ist ein Verfahren zur zustandslosen und automatischen Konfiguration von IPv6-Adressen an einem Netzwerk-Interface. Mit „stateless“ bzw. „zustandslos“ ist gemeint, dass die jeweilige IPv6-Adresse nicht zentral vergeben und gespeichert wird. Demnach erzeugt sich der Host seine IPv6-Adresse unter Zuhilfenahme zusätzlicher Informationen selbst.
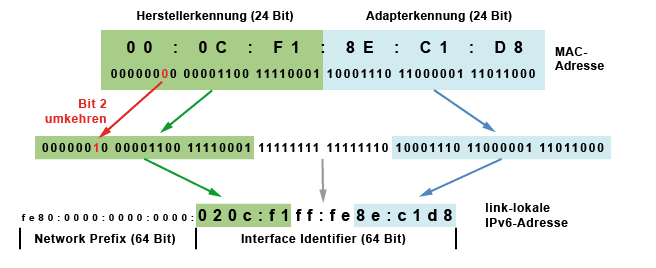
Eine link-lokale IPv6-Adresse wird aus einem Präfix (64 Bit) und einem Suffix (64 Bit) gebildet. Der Präfix für alle link-lokalen IPv6-Adressen ist immer "fe80:0000:0000:0000". Das Suffix (Interface Identifier) ist der EUI-64-Identifier oder IEEE-Identifier, der aus der MAC-Adresse (Hardware-Adresse des Netzwerkadapters) gebildet wird.
In der Mitte der 48-Bit-MAC-Adresse (zwischen dem dritten und dem vierten Byte) werden mit "ff:fe" zwei feste Bytes eingefügt, damit es 64 Bit werden. Zusätzlich wird noch das zweite Bit im ersten Byte der MAC-Adresse invertiert. Das heißt, aus "1" wird "0" und aus "0" wird "1".
Auf diese Weise wird zum Beispiel die MAC-Adresse "00:0C:F1:8E:C1:D8" zum Interface Identifier "020c:f1ff:fe8e:c1d8". Und der Host bildet sich so die link-lokale Adresse "fe80:0000:0000:0000:020c:f1ff:fe8e:c1d8".
Um Adresskollisionen zu vermeiden sollte der Host bei einer neu generierten IPv6-Adresse eine Duplicate Address Detection (DAD) durchführen.
- Neighbor Solicitation: Dazu schickt der Host eine Anfrage an die generierte Adresse ins lokale Netz. Als Antwort-Adresse dient eine Multicast-Adresse.
- Neighbor Advertisement: Falls eine andere Station die IPv6-Adresse bereits nutzt, kommt eine Antwort zurück.
Erst wenn keine Antwort von dieser Adresse zurückkommt, bindet sich das Interface an diese Adresse und kann sie für die Kommunikation nutzen.
Weil es keine Pflicht gibt eine DAD durchzuführen, sind Adresskollisionen durchaus möglich. Aufgrund des sehr großzügigen Adressraums und der weltweit eindeutigen MAC-Adressen aber eher unwahrscheinlich.
Sollte es doch einmal zu einer Kollision kommen und die IPv6-Adresse tatsächlich schon existieren, dann muss die IPv6-Adresse vom Anwender manuell geändert werden.
Dann sollte man gleich das ganze Netzwerk überprüfen. Es könnte dann sein, dass jemand eine MAC-Adresse gekapert hat und per MAC-Spoofing ins Netzwerk eingedrungen ist.
Strukturierte Verkabelung
Eine strukturierte Verkabelung oder universelle Gebäudeverkabelung (UGV) ist ein einheitlicher Aufbauplan für eine zukunftsorientierte und anwendungsunabhängige Netzwerkinfrastruktur, auf der unterschiedliche Dienste (Sprache oder Daten) übertragen werden. Damit sollen teure Fehlinstallationen und Erweiterungen vermieden und die Installation neuer Netzwerkkomponenten erleichtert werden.
Bestandteile einer strukturierten Verkabelung
- standardisierte Komponenten, wie Leitungen und Steckverbindungen
- hierarchische Netzwerk-Topologie (Stern, Baum, …)
- Empfehlungen für Verlegung und Installation
- standardisierte Mess-, Prüf- und Dokumentationsverfahren
Ziele einer strukturierten Verkabelung
- Unterstützung aller aktuellen und zukünftigen Kommunikationssysteme, strukturierte anwendungsneutrale Verkabelung
- Kapazitätsreserve hinsichtlich der Grenzfrequenz
- das Netz muss sich gegenüber dem Übertragungsprotokoll und den Endgeräten neutral verhalten. Es ist egal, wie wir das Gerät verbinden, das Netzwerk sollte am Ende einfach funktionieren
- flexible Erweiterbarkeit
- Ausfallsicherheit durch vermaschte und/oder eine baumstrukturierte Verkabelung
- Datenschutz und Datensicherheit müssen realisierbar sein
- Einhaltung existierender Standards
Primärverkabelung - Geländeverkabelung
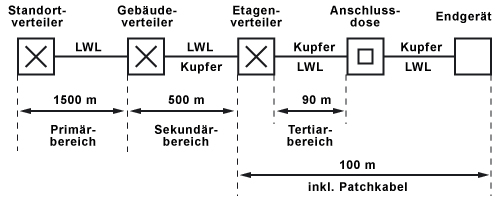
Der Primärbereich wird als Campusverkabelung oder Geländeverkabelung bezeichnet. Er sieht die Verkabelung von einzelnen Gebäuden untereinander vor. Der Primärbereich umfasst meist große Entfernungen, hohe Datenübertragungsraten, sowie eine geringe Anzahl von Stationen.
Sekundärverkabelung - Gebäudeverkabelung
Der Sekundärbereich wird als Gebäudeverkabelung oder Steigbereichsverkabelung bezeichnet. Er sieht die Verkabelung von einzelnen Etagen und Stockwerken untereinander innerhalb eines Gebäudes vor.
Tertiärverkabelung - Etagenverkabelung
Der Tertiärbereich wird als Etagenverkabelung bezeichnet. Er sieht die Verkabelung von Etagen- oder Stockwerksverteilern zu den Anschlussdosen vor. Während sich im Stockwerksverteiler ein Netzwerkschrank mit Patchfeld befindet, mündet das Kabel am Arbeitsplatz des Anwenders in einer Anschlussdose in der Wand, in einem Kabelkanal oder in einem Bodentank mit Auslass.
NAT/PAT
NAT = Network Address Translation
PAT = Port Address Translation
Der IPv4-Adressraum ist auf rund 4,3 Milliarden Adressen begrenzt (2^32). Es wurde relativ schnell klar, dass diese 4,3 Milliarden IP-Adressen nicht ausreichen würden. Um dieses Problem zu adressieren, wurden Teile des IPv4-Raums als privat deklariert.
| Netzadressebereich |
CIDR - Notation |
Anzahl Adressen |
| 10.0.0.0 bis 10.255.255.255 |
10.0.0.0/8 |
2^24 = 16.777.216 |
| 172.16.0.0 bis 172.31.255.255 |
172.16.0.0/12 |
2^20 = 1.048.576 |
| 192.168.0.0 bis 192.168.255.255 |
192.168.0.0/16 |
2^16 = 65.536 |
Diese IP-Adressen werden im Internet nicht geroutet und können daher nicht verwendet werden. Stattdessen werden diese Adressen für die lokalen Netzwerke beim Endkunden verwendet. Der Endkunde erhält von seinem Provider eine (teilweise auch mehrere) öffentliche IP-Adressen. Gleichzeitig spannt der Router des Endkunden intern ein neues Netzwerk innerhalb des privaten IPv4-Adressraums auf, aus welchem er den Clients IP-Adressen vergibt.
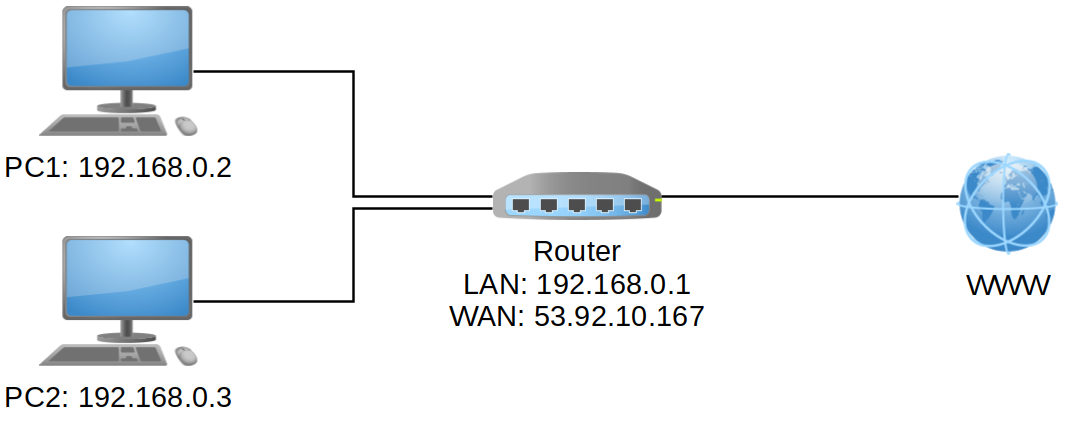
Im Gegensatz zum Routing wird bei NAT/PAT tatsächlich die IP-Adresse ausgetauscht
Um die Kommunikation zwischen den privaten und öffentlichen IP-Adressbereichen zu ermöglichen wurden mehrere Verfahren entwickelt:
Source NAT/PAT
- Beim Verbindungsaufbau durch einen internen Client wird die interne Quell-IP-Adresse durch die öffentliche IP-Adresse ersetzt
- Zusätzlich wird der Quellport des Clients durch eine freien Port des Routers ersetzt
- Die Zuordnung merkt sich der Router in einer Tabelle (NAT-Table)
- Beispiel:
Quelle Ziel Quelle Ziel 192.168.0.2:49701 170.0.0.1:80
Router 205.0.0.2:49701 170.0.0.1:80
192.168.0.3:50387 170.0.0.1:80
===========>
205.0.0.2:50387 170.0.0.1:80
lokales Netz NAT
öffentliches Netz
Destination NAT/PAT
- Bei jedem Verbindungsaufbau durch den Client wird die Ziel-IP-Adresse durch die des eigentlichen Empfängers in LAN ersetzt
- Router hat also ins WAN eine IP-Adresse und je nach Anfrage wird passende interne IP-Adresse eingesetzt
- Beispiel:
Quelle Ziel Quelle Ziel 170.0.0.1:1001
171.4.2.1:80
Router 170.0.0.1:1001 192.168.0.2:80
170.0.0.1:1001
171.4.2.1:22
===========>
170.0.0.1:1001 192.168.0.3:22
öffentliches Netz
NAT
lokales Netz
Firewall
Bei einer Firewall handelt es sich um ein System, das in der Lage ist, Datenverkehr zu analysieren. Sie schützt IT-Systeme vor Angriffen oder unbefugten Zugriffen. Die Firewall kann als dedizierte Hardware oder als Softwarekomponente ausgeführt sein.
Jede Firewall besteht aus einer Softwarekomponente, die Netzwerkpakete lesen und auswerten kann. Innerhalb dieser Software lassen sich die Regeln, welche Datenpakete durchgelassen werden und welche zu blockieren sind, definieren.
Häufig sind Firewalls an Netzwerkgrenzen zwischen einem internen und einem externen Netzwerk platziert. An dieser zentralen Stelle kontrollieren Sie den ein- und ausgehenden Datenverkehr.
Wichtigsten Funktionskomponenten
Um die Schutzfunktion zu erfüllen, besitzen klassische Firewalls verschiedene Funktionskomponenten. Die Anzahl und der Featureumfang der einzelnen Komponenten kann sich je nach Leistungsfähigkeit von Firewall- zu Firewalllösung unterscheiden. Wesentliche in Firewalls implementierte Funktionen sind häufig diese:
| Paketfilter | Kann IP-Pakete anhand von Merkmalen wie IP-Absenderadressen, IP-Zieladressen und Ports filtern. |
| Network Address Translation | Setzt dynamisch eine öffentliche IP-Adresse auf mehrere private IP-Adressen um. Jede ausgehende Verbindung wird mit IP-Adresse und Portnummer festgehalten. Anhand der Portnummer kann NAT eingehende Datenpakete einer lokalen Station zuordnen. |
| URL-Filter | Hiermit wird eingeschränkt, auf welche Webinhalte Benutzer zugreifen können. Dazu wird das Laden bestimmter URLs blockiert. |
| Content-Filter | Bezeichnet die Nutzung eines Programms zum Screenen und/oder Unterbinden von Zugriff auf als unzulässig betrachtete Webinhalten oder E-Mails. |
| Proxyserver | Ist ein Vermittler in einem Netzwerk, der Anfragen entgegennimmt und sie stellvertretend weiterleitet. Mithilfe des Proxyservers lässt sich die Kommunikation zwischen einem lokalen Client und einem Webserver absichern, verschleiern oder beschleunigen. |
| Virtual Private Networks (VPN) | Eine VPN-Verbindung bietet die Möglichkeit, von außen auf ein bestehendes Netzwerk zuzugreifen. |
| Stateful Packet Inspection | Ist eine dynamische Paketfiltertechnik für Firewalls, die im Gegensatz zu statischen Filtertechniken den Zustand einer Datenverbindung in die Überprüfung der Pakete einbezieht und entscheidet, ob ein Datenpaket zugelassen oder blockiert wird. |
| Stateless Packet Filtering | Stateless Firewalls sind für den Schutz von Netzwerken auf der Grundlage statischer Informationen wie Quelle und Ziel konzipiert. Während Stateful Firewalls Pakete auf der Grundlage des gesamten Kontexts einer bestimmten Netzwerkverbindung filtern, filtern Stateless Firewalls Pakete auf der Grundlage der einzelnen Pakete selbst. |
| Deep Packet Inspection | In einem Netzwerk übertragene Datenpakete lassen sich bis auf Anwendungsebene des ISO/OSI-Schichtenmodells inspizieren und filtern. Im Gegensatz zur Stateful Packet Inspection (SPI) werden nicht nur die Daten-Header, sondern auch die Nutzlast eines Datenpakets analysiert. |
| Routing | Routing sorgt dafür, dass Datenpakete über Netzgrenzen hinweg einen Weg zu anderen Hosts finden. Es kann die Daten über jede Art von physikalischer Verbindung oder Übertragungssystem vermitteln. |
Verschlüsselung
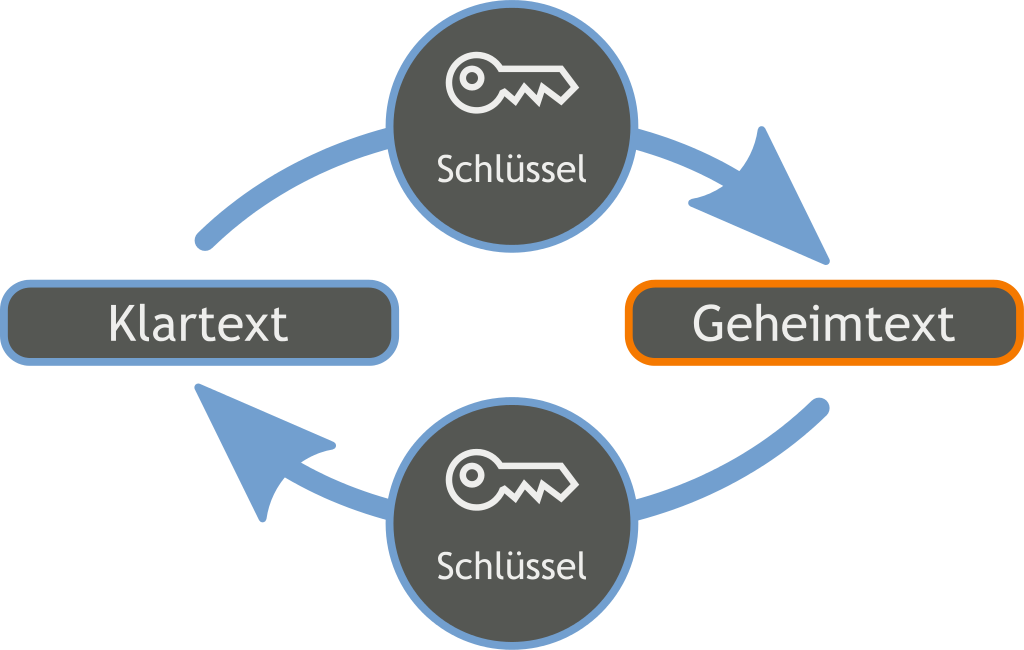
Grundsätzlich
- Die von einem Schlüssel abhängige Umwandlung von Klartext in Geheimtext, so das der Klartext aus dem Geheimtext nur mit Hilfe des Schlüssels wieder gewonnen werden kann

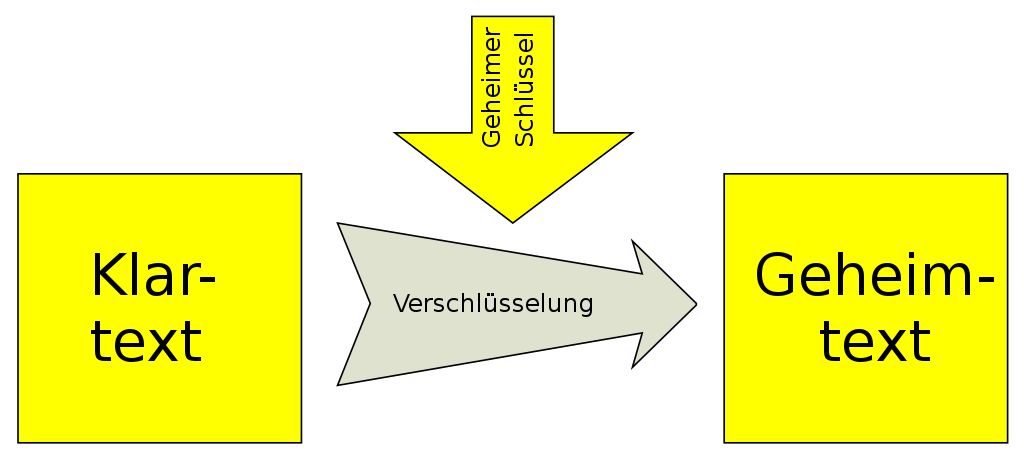
symmetrische Verschlüsselung
- beide Teilnehmer verwenden den gleichen Schlüssel
- Vorteil: Verschlüsselung und Entschlüsselung sehr schnell
- Nachteil: Der Schlüssel muss über einen gesicherten Kanal ausgetauscht werden
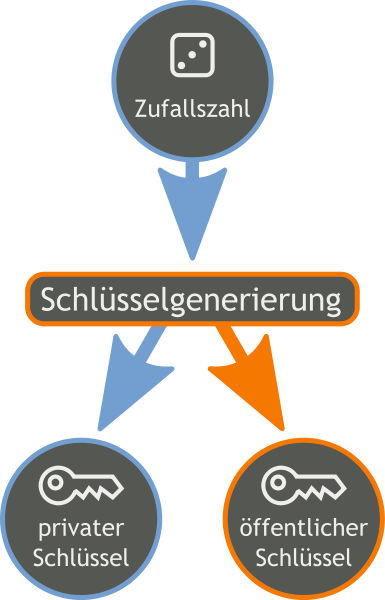
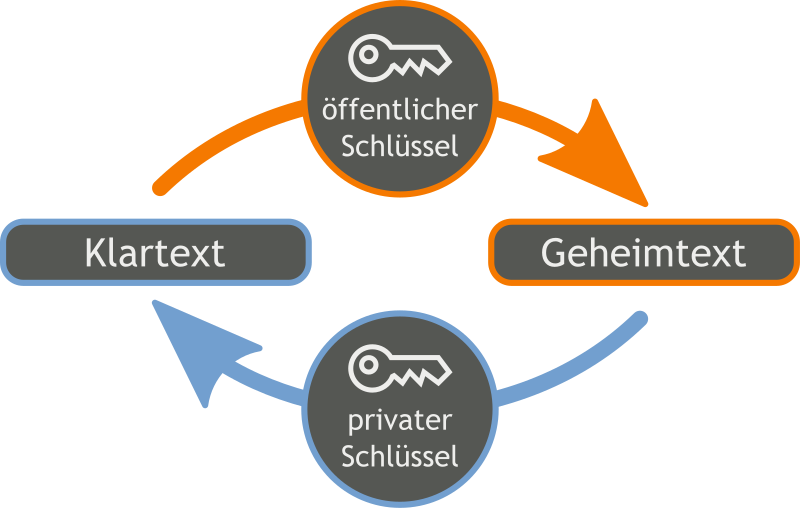
asymmetrische Verschlüsselung
- Aufteilung in einen privaten und einen öffentlichen Schlüssel
- Der private Schlüssel wird mit niemanden geteilt und von niemandem eingesehen
- Der öffentliche Schlüssel kann frei zugängig gemacht werden
- Nachrichten werden mit Hilfe des öffentlichen Schlüssels des Gegenüber verschlüsselt und können nur mit Hilfe des privaten Schlüssels entschlüsselt werden
- Vorteil: Der Datenaustausch ist sehr sicher
- Nachteil: Schlüssel-Infrastruktur notwendig und Kommunikations nicht mehr so schnell
- Lösung: Kombination beider Verfahren
- Nach dem Verbindungsaufbau wird mit Hilfe von privaten und öffentlichen Schlüsseln ein gemeinsamer Schlüssel ausgehandelt. Damit ist die Kommunikation zu Beginn kurz langsamer, man kann sich aber sicher sein, dass der gemeinsame Schlüssel geheim ist.
- Aufbau: handelt mit Hilfe des asymmetrischen Schlüssels einen symmetrischen Schlüssel aus
- Austausch: Daten werden mit Hilfe des symmetrischen Schlüssels ausgetauscht
- Abbau: Verbindung wird beendetk
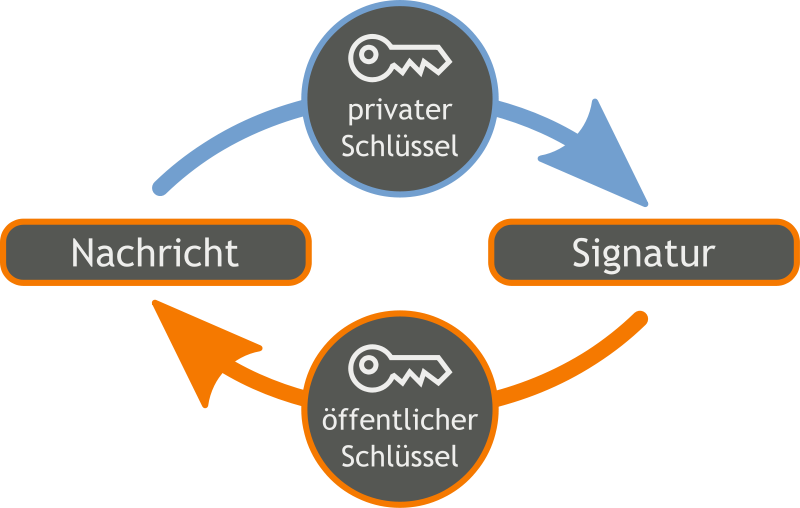
Signatur
- Authentizität: Stammen die Informationen wirklich vom Absender
- Integrität: Sind die Informationen nicht verändert worden
- Lösung:
- erstellen einer Prüfsumme
- Signieren der Prüfsumme mit Hilfe des privaten Schlüssels
- Kontrolle der Authentizität durch Entschlüsseln der Signatur mit Hilfe des öffentlichen Schlüssels
- Kontrolle der Integriät durch eigene Berechnung der Prüfsumme und Vergleich mit gesendeter, signierter Prüfsumme
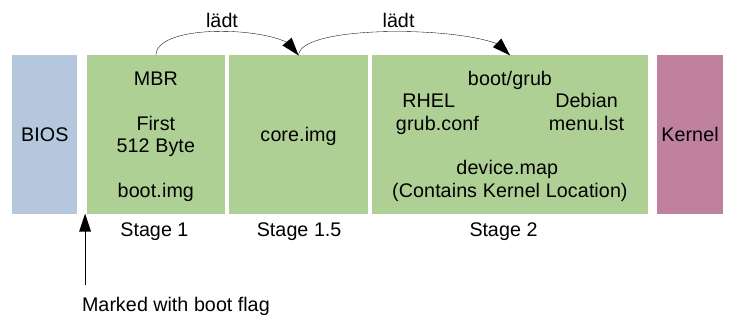
Bootloader & Partitionstabellen
Bootloader
Bootloader sorgen dafür, dass alle relevanten Daten des Betriebssystems bereits mit Gerätestart in den Arbeitsspeicher geladen werden. Während des Boot-Prozesses übermittelt die Firmware die hierfür erforderlichen Informationen.
Ein Bootloader oder auch Bootmanager verwaltet in erster Linie die Boot-Sequenz eines Computers und führt diese aus. Dieser wird in der Regel gestartet, nachdem der Computer oder das BIOS die anfänglichen Strom- und Hardwareprüfungen sowie Tests abgeschlossen hat. Er holt den Betriebssystem-Kernel von der Festplatte oder einem bestimmten Boot-Gerät innerhalb der Boot-Sequenz (Reihenfolge der zu startenden Systeme) in den Hauptspeicher.
Windows als Beispiel nutzt den Bootloader Bootmgr. Mit diesem lassen sich mehrere parallel installierte Windows-Betriebssysteme oder auch zusätzliche Linux-Systeme starten. Ein Beispiel für ein Linux-Bootloader wäre GRUB (Grand Unified Bootloader). Dieser kann ebenfalls eine Vielzahl an Betriebssystemen flexibler starten und wird auch unter anderen Unix-artigen Betriebssystemen eingesetzt.
Wo sich der Bootloader auf dem veränderlichen Datenspeicher zu befinden hat und wie er geladen wird, ist je nach Rechnerarchitektur und Plattform unterschiedlich. Auf moderneren Architekturen liegt er meist als Datei auf einem von der Firmware unterstützten Dateisystem auf einer bestimmten Partition und wird direkt geladen und ausgeführt. Das ist beispielsweise bei Open Firmware und bei UEFI der Fall, wobei die verwendeten Partitionstabellen und Dateisysteme unterschiedlich sein können.
Partitionstabellen
Als Partitionstabelle, auch Partitionsschema, bezeichnet man genormte Datenstrukturen, welche Informationen über die Aufteilung eines Datenspeichers in separate Bereiche beinhalten. Diese Bereiche werden als Partitionen bezeichnet und sind mehrere voneinander unabhängig benutzbare Teile auf normalerweise einem Speichermedium.
Wenn die Partitionstabelle der Festplatte verloren geht, können Benutzer die Daten auf der Festplatte nicht lesen und keine neuen Daten darauf schreiben.
MBR-Partitionstabelle
Der Master Boot Record (kurz MBR) enthält ein Startprogramm für BIOS-basierte Computer und eine Partitionstabelle. Er befindet sich im ersten Sektor eines in Partitionen aufteilbaren Speichermediums, wie beispielsweise einer Festplatte.
Das Startprogramm befindet sich auf den ersten 446 Bytes des MBR. Die nicht sehr umfangreiche Software wird beim Hochfahren des PCs aktiv und initiiert auf operativer Ebene den Bootvorgang. Eine umfangreichere Routine mit standardisierten Verarbeitungsschritten wird in Gang gesetzt, die mit einem einsatzbereiten Betriebssystem (z. B. Windows) endet.
Über die Datenträger- oder Disk-Signatur identifizieren Windows-Rechner (ab Windows 2000) einen Datenträger mit Partitionstabelle.
Die Partitionstabelle dokumentiert die Aufteilung eines Datenspeichers in separate Speichersektionen. Dafür verwendet sie vier Einträge à 16 Byte, die Auskunft über die Lage und die Größe jeder Partition geben. So wird angegeben, wo eine C:\-Partition oder eine D:\-Partition anfängt und endet. Die Tabelle enthält zudem Informationen über den Typ des Datenträgers.
Die MBR- oder Boot-Signatur enthält in zwei Bytes die Zeichenfolgen „55“ und „AA“. Durch die charakteristische Kodierung, die immer am Ende des MBR-Sektors zu finden ist, wird ein Master Boot Record als solcher eindeutig erkannt. Fehlt diese Information, wird der Master Boot Sektor nicht identifiziert und der Bootvorgang wird mit einer Fehlermeldung abgebrochen.
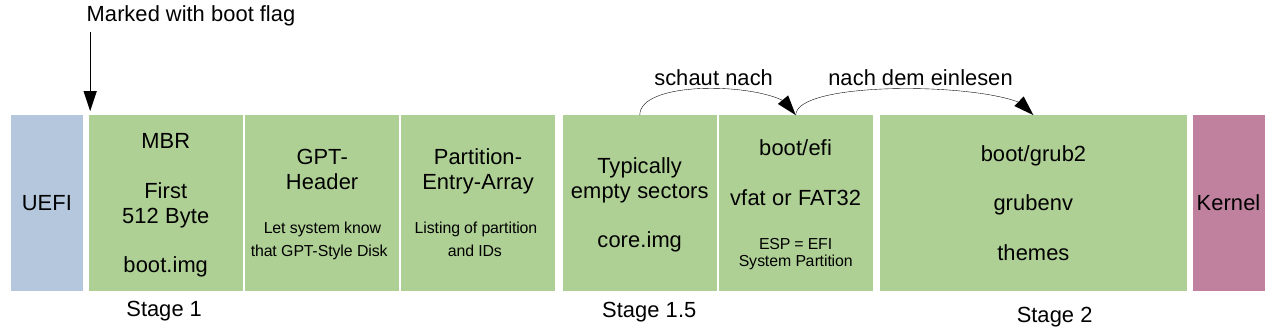
GPT-Partitionstabelle
GUID Partition Table (GPT), zu Deutsch GUID-Partitionstabelle, ist ein Standard zur Formatierung von Partitionstabellen für Speichermedien, insbesondere für Festplatten. GPT ist Bestandteil von UEFI (Unified Extensible Firmware Interface), einer Schnittstellen-Spezifikation, die den Austausch zwischen Firmware und Betriebssystemen während des Bootvorgangs regelt und im Jahr 2000 als BIOS-Nachfolger entwickelt und veröffentlicht worden ist.
Der Aufbau eines Datenträgers mit GUID-Partition-Table-Schema bestehen im Wesentlichen aus diesen vier Teilen:
- Protective Master Boot Record: An erster Stelle steht der bereits erwähnte Protective-MBR, der für die Abwärtskompatibilität des Partitionierungsstils sorgt
- Primäre GUID-Partitionstabelle: GPT-Header und Partitionseinträge
- Partitionen: Auf den Header und die Partitionseinträge folgen die jeweiligen Einheiten des aufgeteilten Speicherplatzes, also die verschiedenen Partitionen
- Sekundäre GUID-Partitionstabelle: Backup von GPT-Header und Partitionseinträgen in gespiegelter Reihenfolge
MBR oder GPT
Das MBR-Format wird seit Anfang der 80er Jahre verwendet und wird weitgehend unterstützt, ist aber auf maximal vier primäre Partitionen mit bis zu 2 Terabyte (TB) beschränkt.
Das GPT-Format ist eine neuere Technologie, die es erlaubt, deutlich größere Festplatten zu verwenden: bis zu einer theoretischen Grenze von 9,4 Zettabyte (ZB) oder fast 10 Milliarden Terabyte. Es wird geschätzt (Stand 2013), dass das gesamte World Wide Web etwa 4 ZB einnimmt. Windows begrenzt GPT-Partitionen derzeit auf 256 TB.
Mit GPT können bis zu 128 Partitionen erstellt werden. Ein weiterer Vorteil von GPT gegenüber MBR ist, dass zwei Kopien des GPT-Headers gespeichert werden, eine am Anfang der Festplatte und eine am Ende. Damit sind die Daten besser vor Beschädigung geschützt als beim MBR-Format, das nur eine einzige Partitionstabelle speichert.
Bootvorgang unter Linux
Grub bzw. Grub Legacy
Grub2
Gängige Ports im Internet
| Port |
TCP |
UDP |
Beschreibung |
| 22 | x |
x |
SSH - Secure Shell |
| 25 |
x |
SMTP - Simple Mail Transfer Protocol |
|
| 53 |
x |
x |
DNS - Domain Name System |
| 67 |
x |
DHCP - Dynamic Host Configuration Protocol - Server |
|
| 68 |
x |
DHCP - Dynamic Host Configuration Protocol - Client |
|
| 80 |
x |
HTTP - Hypertext Transfer Protocol |
|
| 110 |
x |
POP3 - Post Office Protocol v3 |
|
| 123 |
x |
x |
NTP - Network Time Protocol |
| 443 |
x |
HTTPS - Hypertext Transfer Protocol over TLS |
|
| 993 |
x |
IMAPS - Internet Message Accesss Protocol over TLS |
Logische Operatoren
Wahrheitstabelle
| A |
B |
A AND B |
A NAND B |
A OR B |
A NOR B |
A XOR B |
A XNOR B |
NOT A |
||||
| 0 |
0 |
0 |
1 |
0 |
1 |
0 |
1 |
1 |
||||
| 1 |
0 |
0 |
1 |
1 |
0 |
1 |
0 |
0 |
||||
| 0 |
1 |
0 |
1 |
1 |
0 |
1 |
0 |
1 |
||||
| 1 |
1 |
1 |
0 |
1 |
0 |
0 |
1 |
0 |
Mathematische und Technische Symbolik
| Operator |
Formel |
Schaltsymbolik |
Relaislogik |
| AND |
|
 |
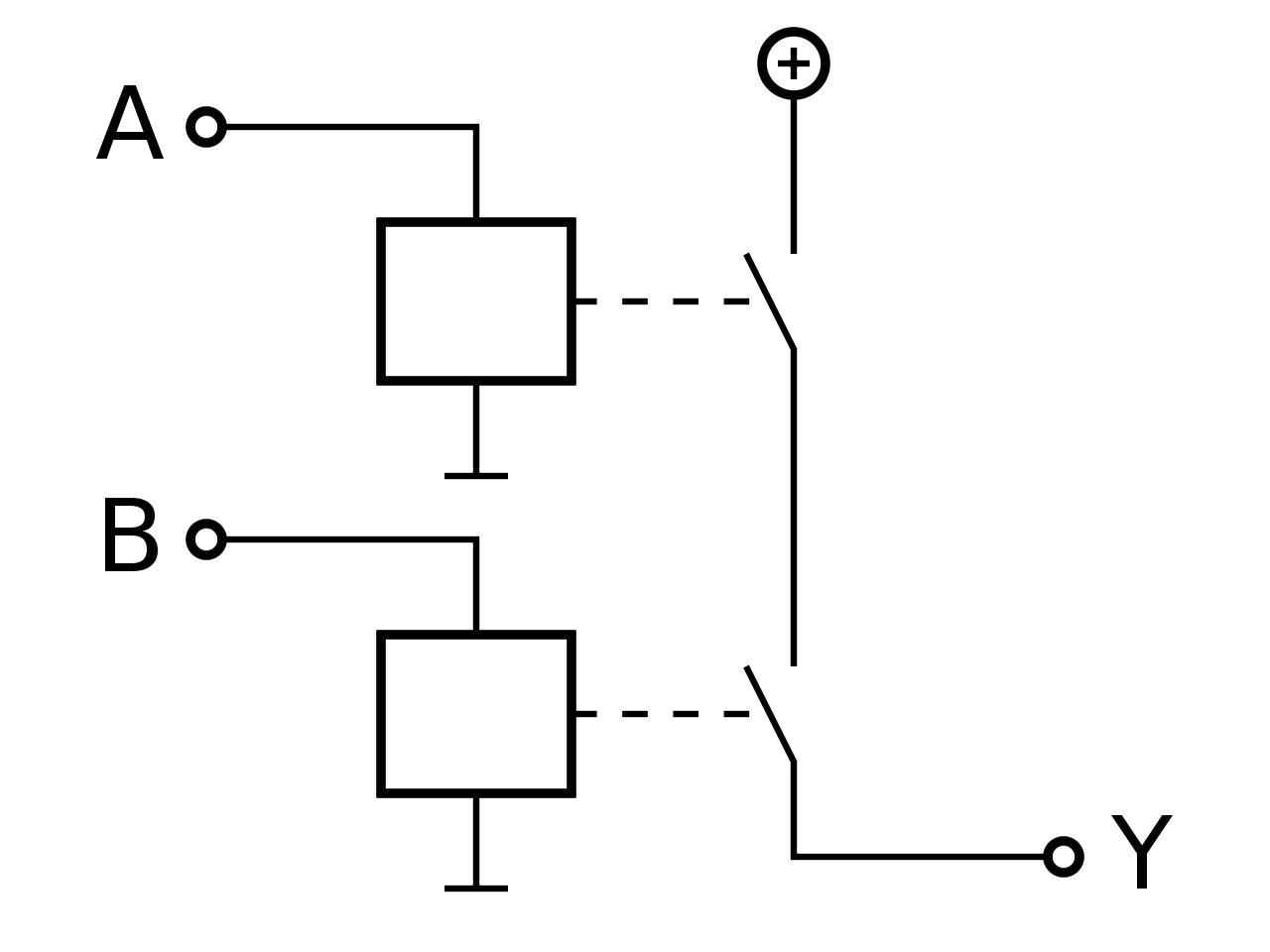 |
| NAND |
 |
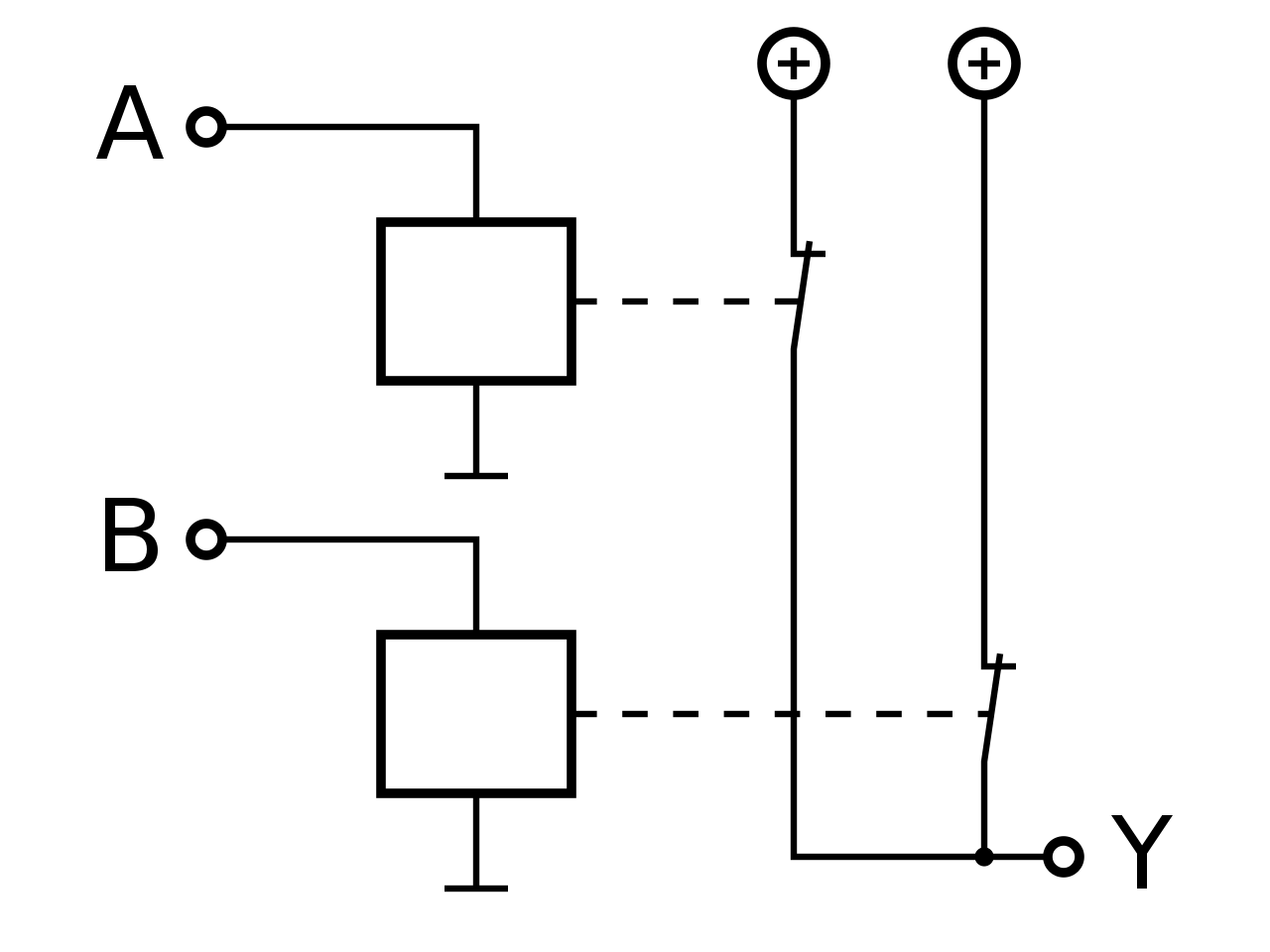 |
|
| OR |
 |
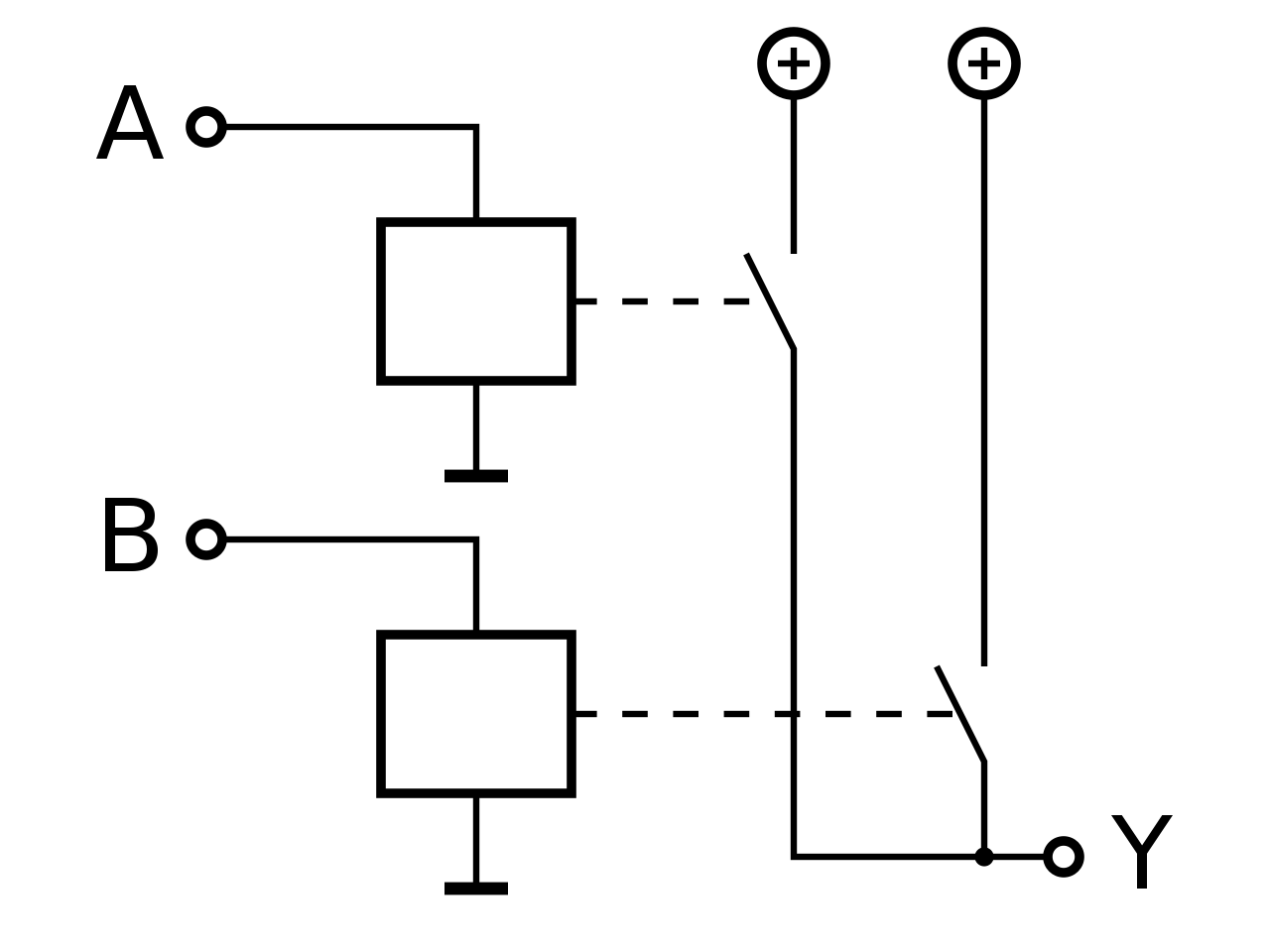 |
|
| NOR |
 |
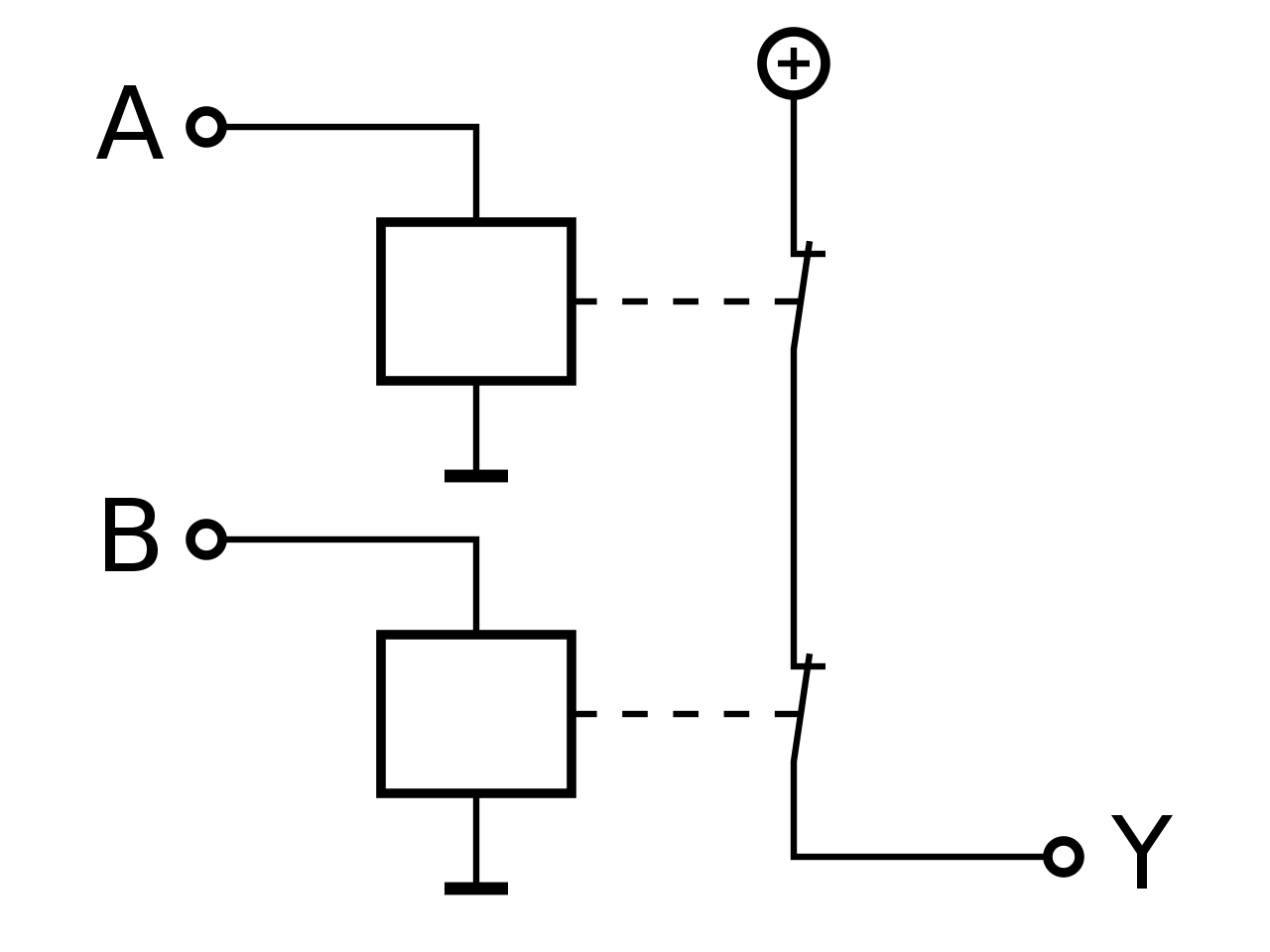 |
|
| XOR |
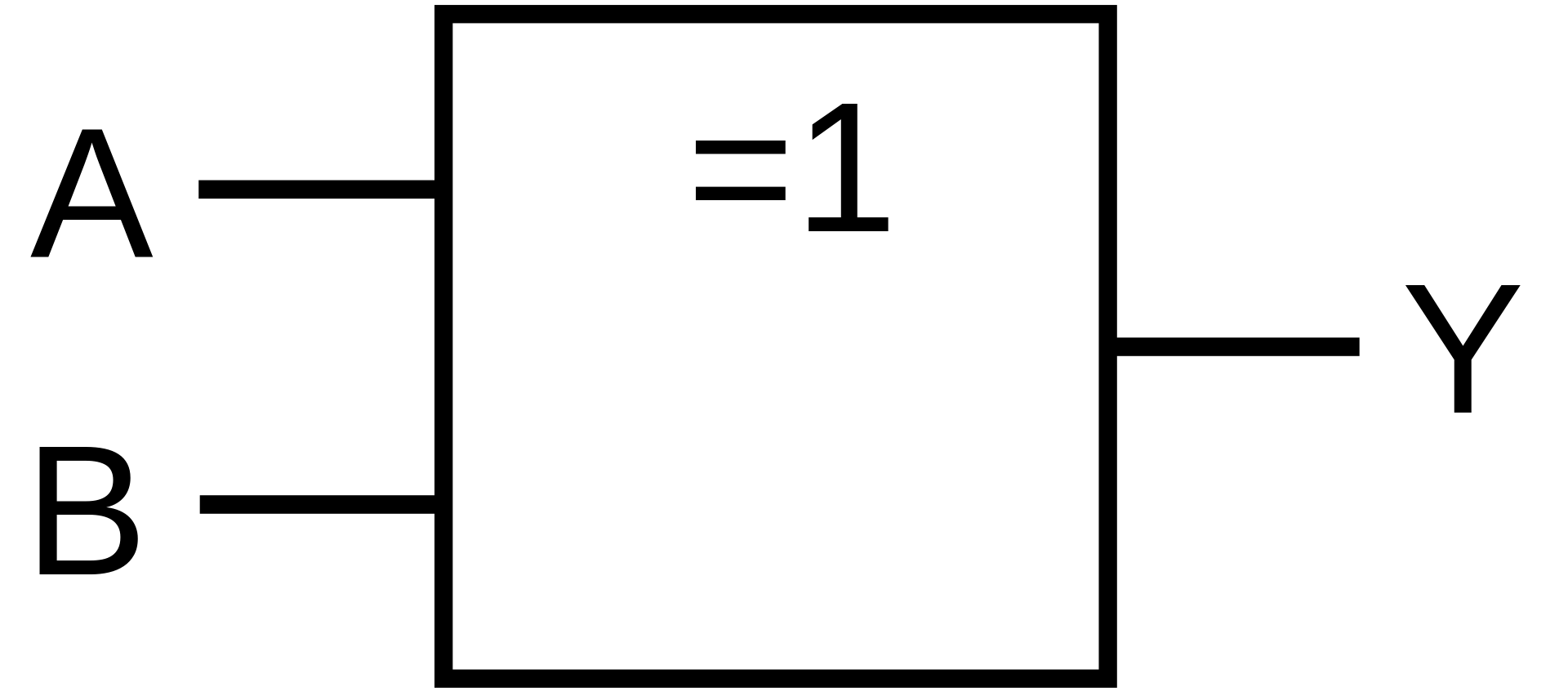 |
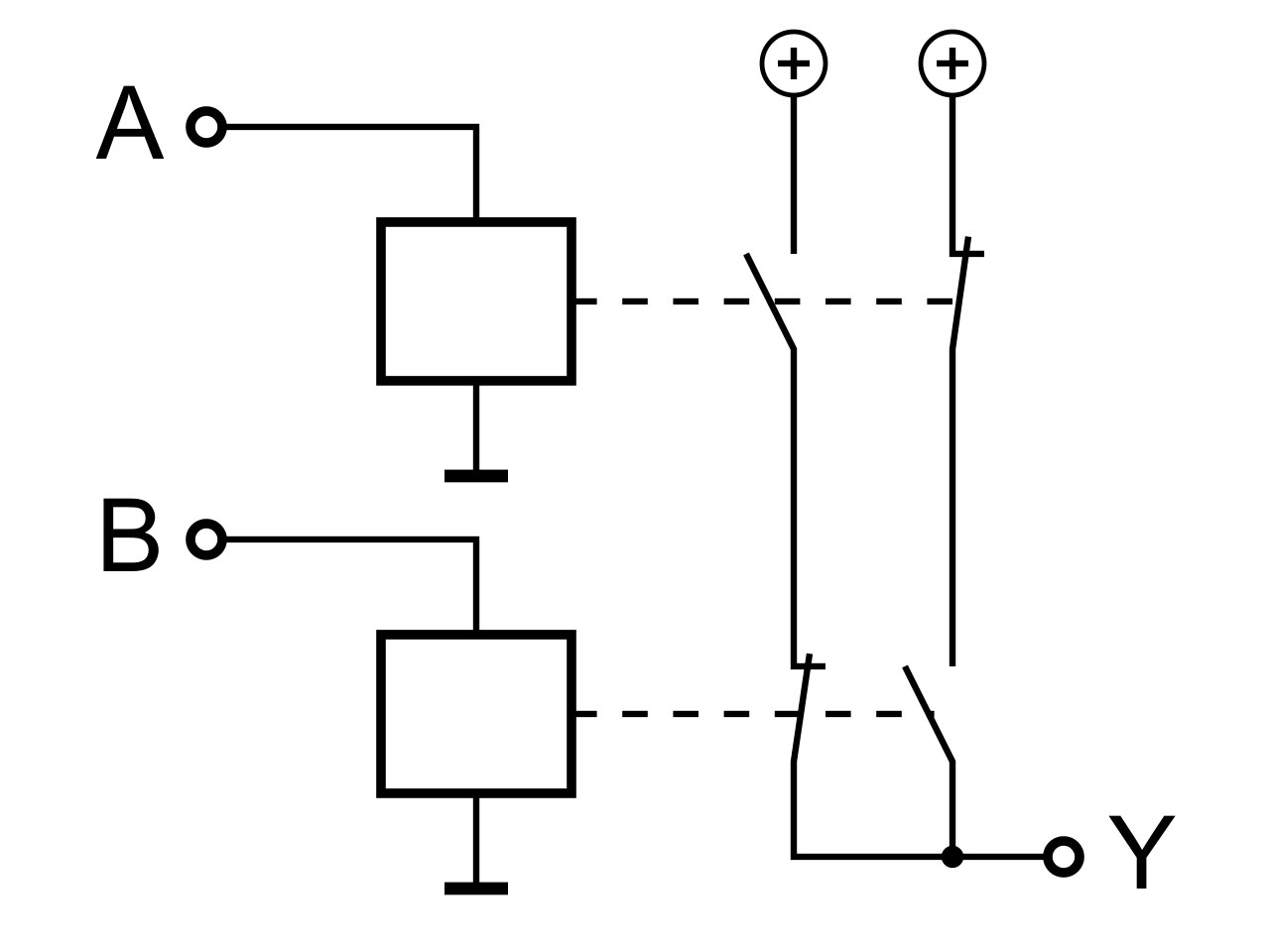 |
|
| XNOR |
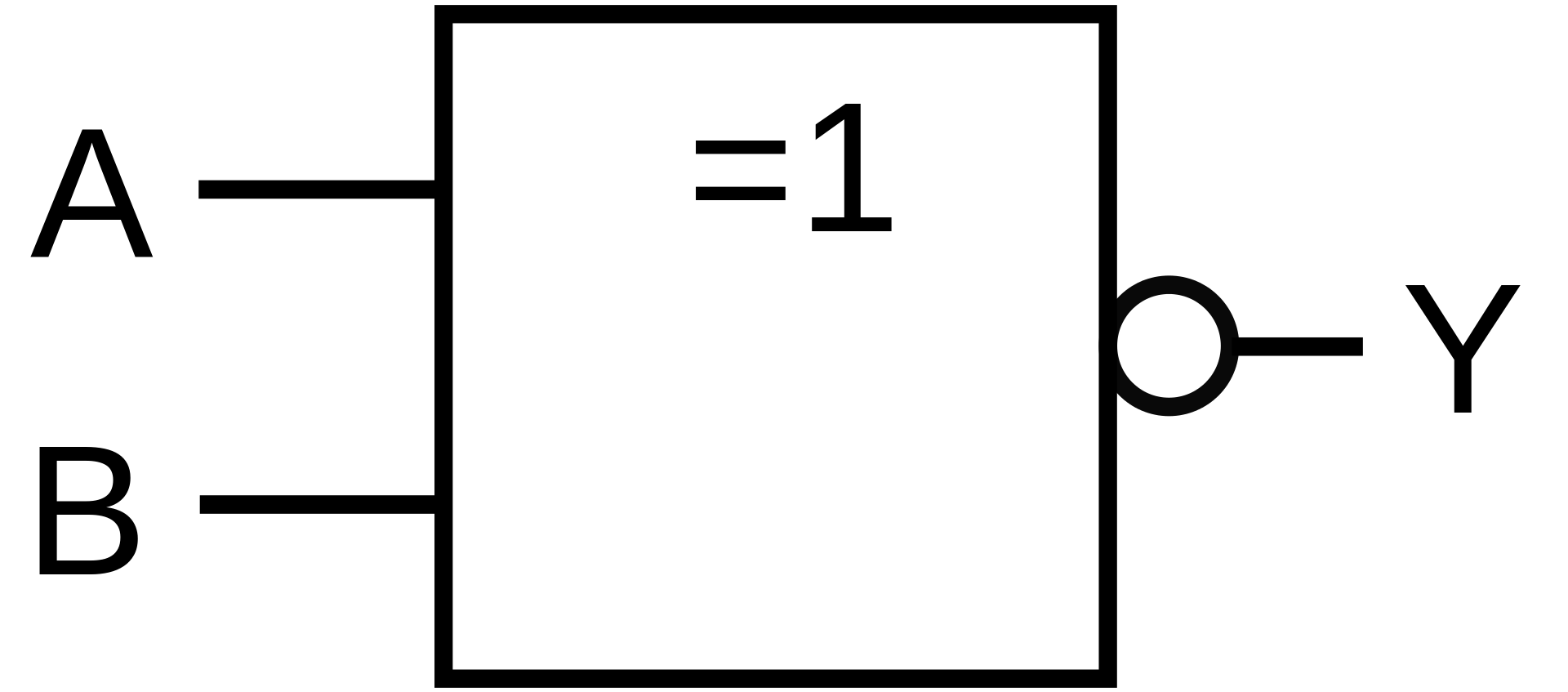 |
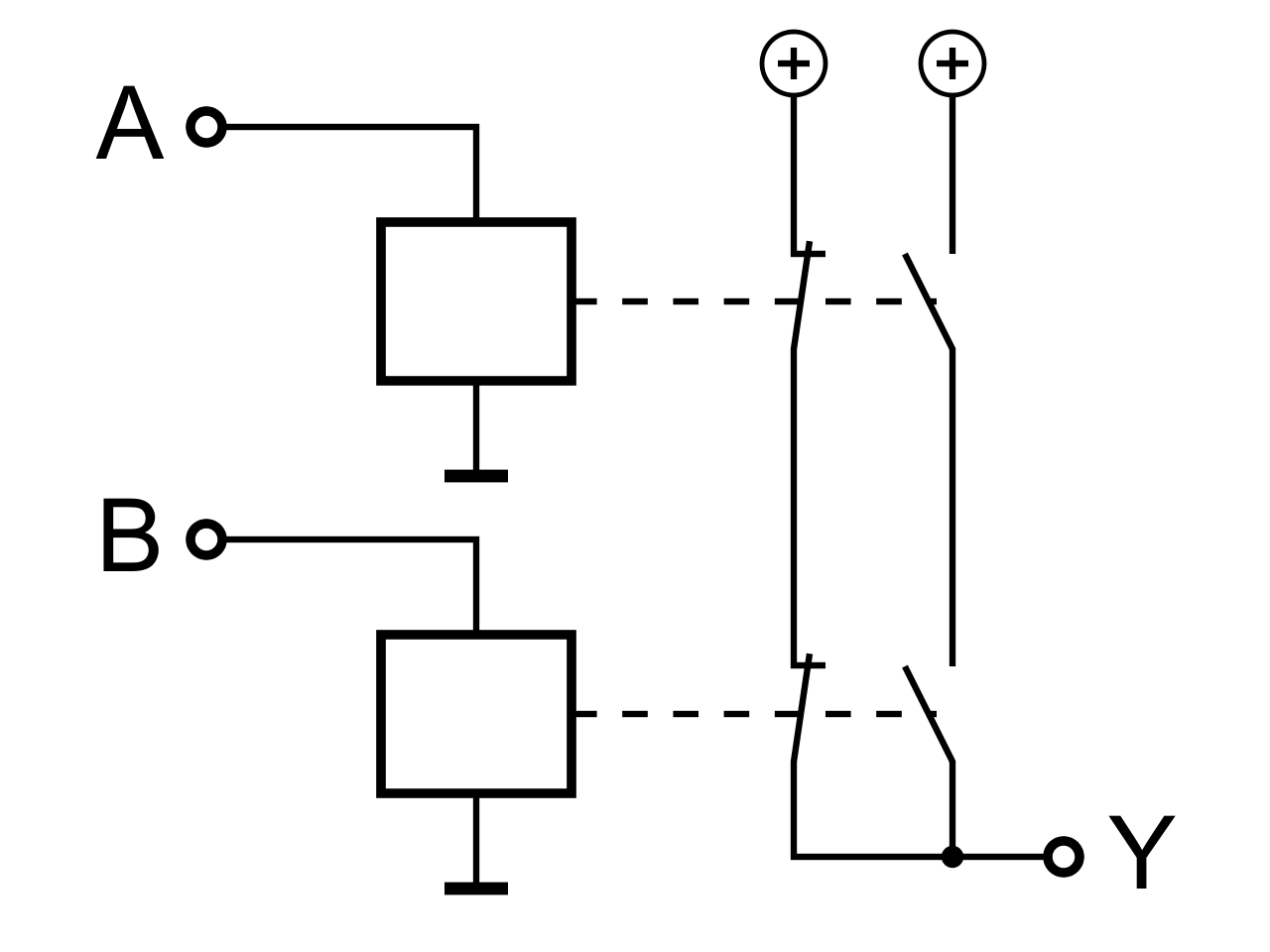 |
|
| NOT |
 |
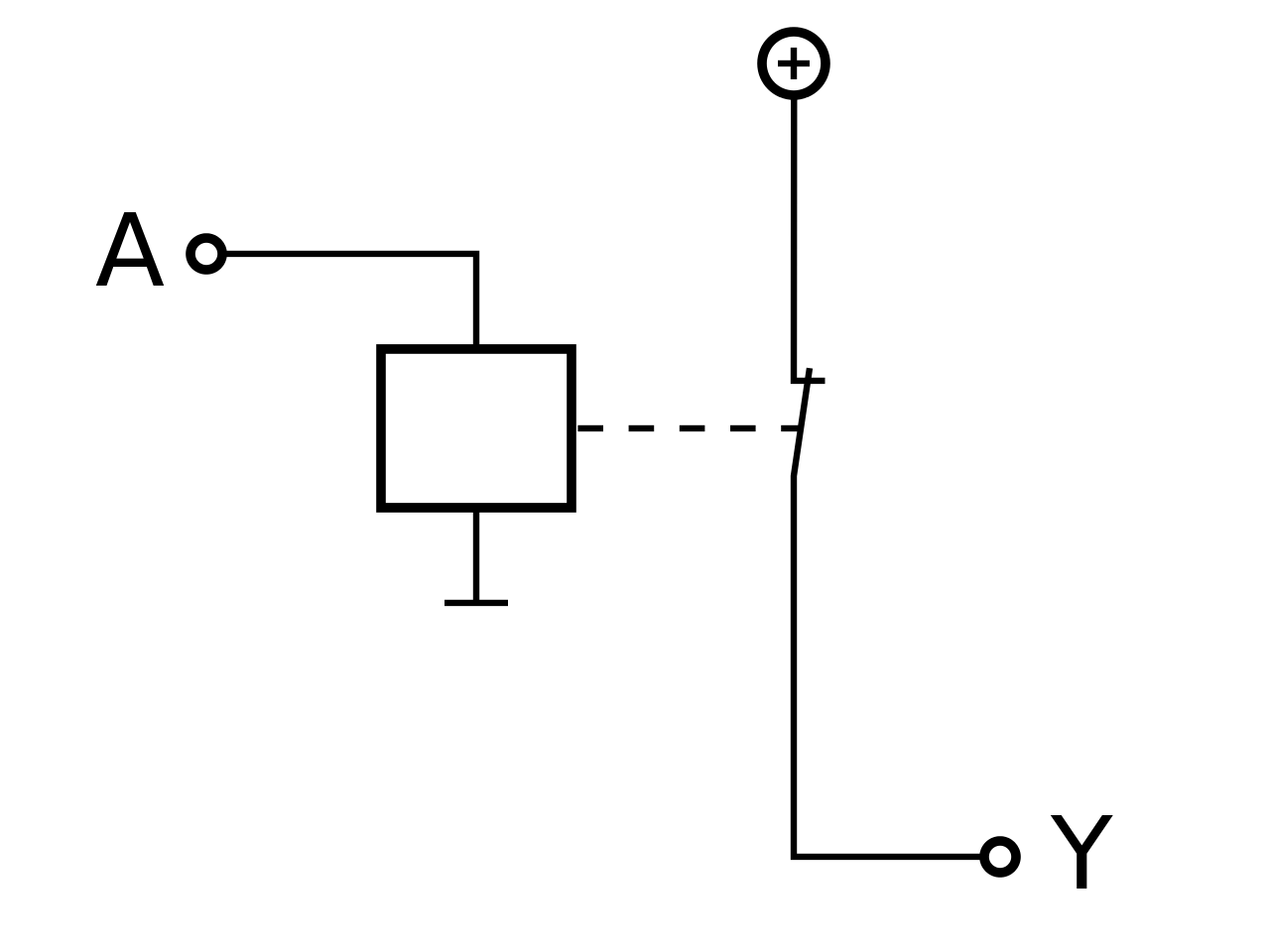 |







Berechnungshilfe
Binär |
Dezimal |
Hexadezimal |
|||
| 0 |
0 |
0 |
0 |
0 |
0 |
| 0 |
0 |
0 |
1 |
1 |
1 |
| 0 |
0 |
1 |
0 |
2 |
2 |
| 0 |
0 |
1 |
1 |
3 |
3 |
| 0 |
1 |
0 |
0 |
4 |
4 |
| 0 |
1 |
0 |
1 |
5 |
5 |
| 0 |
1 |
1 |
0 |
6 |
6 |
| 0 |
1 |
1 |
1 |
7 |
7 |
| 1 |
0 |
0 |
0 |
8 |
8 |
| 1 |
0 |
0 |
1 |
9 |
9 |
| 1 |
0 |
1 |
0 |
10 |
a |
| 1 |
0 |
1 |
1 |
11 |
b |
| 1 |
1 |
0 |
0 |
12 |
c |
| 1 |
1 |
0 |
1 |
13 |
d |
| 1 |
1 |
1 |
0 |
14 |
e |
| 1 |
1 |
1 |
1 |
15 |
f |
Mit Hilfe dieser Tabelle kann man sehr leicht jede dezimal Zahl in eine hexadezimale Zahl umrechnen. Dabei geht man den Umweg über die binären Zahlen. Der Rückweg ist ebenfalls möglich.
Umrechnung am Beispeil von 999
| Dividend |
Divisor |
Quotient |
Rest |
||
| 999 | / |
2 |
= |
499 | 1 |
| 499 | / |
2 |
= |
249 | 1 |
| 249 | / |
2 |
= |
124 | 1 |
| 124 | / |
2 |
= |
62 | 0 |
| 62 | / |
2 |
= |
31 | 0 |
| 31 | / |
2 |
= |
15 | 1 |
| 15 | / |
2 |
= |
7 | 1 |
| 7 | / |
2 |
= |
3 | 1 |
| 3 |
/ |
2 |
= |
1 |
1 |
| 1 |
/ |
2 |
= |
0 |
1 |
- Es ergibt sich die binäre Zahl (von unten nach oben gelesen):
1111100111 - Diese wird von rechts nach links in vierer Blöcke unterteilt:
11 | 1110 | 0111 - sollte der Block ganz links nicht aus vier Bit bestehen wird mit Null aufgefüllt:
0011 | 1110 | 0111 - jeder Block kann mit Hilfe der Tabelle in eine hexadezimale Zahl umgewandelt werden:
3 | e | 7 -> 0x 3e7
VLAN
Ein VLAN ist eine Struktur, in welcher Netzwerkswitche in mehrere „logische Switche“ aufgeteilt und voneinander isoliert werden.
Jedes VLAN bildet ein eigenes Netz. Jedes LAN bildet eine Broadcastdomäne. Broadcasts bleiben somit im eigenen VLAN und gelangen nicht in andere. Damit zwei Rechner in unterschiedlichen VLANs miteinander kommunizieren können, müssen diese über einen Router verbunden werden.
VLAN Typen
Uplinks einzelner logischer Switche, werden physikalisch zu einem Link zusammengefasst. Damit die Datenframes der einzelnen logischen virtuellen Netzwerke dem jeweiligen VLAN zugeordnet werden können, müssen die Frames mit VLAN-Tags modifiziert werden. Die Zugehörigkeit zum virtuellen Netzwerk muss zusätzlich im Frame (Layer-2, Ethernet-Frame) transportiert werden.
Tagged und Untagged VLANs
Der PC schickt einen normalen Datenframe heraus. Der Switch macht die Zuordnung zum virtuell LAN und erweitert den Frame mit dem Tag. Das so gekennzeichnete Ethernet-Frame wird wie gewohnt durch das Netzwerk transportiert. Der letzte Switch entfernt diesen VLAN-Tag wieder, bevor er die Daten an den Zielrechner schickt.
Untagged VLAN bedeutet, dass der komplette Switchport dem VLAN angehört. Egal welches Gerät angeschlossen wird, wird automatisch im definierten VLAN landen. Untagged VLAN ist auch als portbasierten VLAN bekannt.
VLAN-Trunking
Mit VLAN-Trunking lassen sich Switches so verschalten, dass sie mehrere verschiedene VLANs untereinander zu Netzwerken verbinden. VLAN-Trunking ist in der Lage, die Informationen mehrerer virtueller LANs über eine einzige Leitung zu übertragen. Es lassen sich einzelne oder gebündelte Ports für das Trunking verwenden.
Bei portbasierten VLANs (d. h. bei Paketen, die kein Tag besitzen) wird zum Weiterleiten eines Datenpakets über einen Trunk hinweg üblicherweise vor dem Einspeisen in den Trunk ein VLAN-Tag hinzugefügt, welches kennzeichnet, zu welchem VLAN das Paket gehört. Der Switch auf Empfängerseite muss dieses wieder entfernen. Bei tagged VLANs (nach IEEE 802.1Q) hingegen werden die Pakete entweder vom Endgerät (z. B. Tagging-fähigem Server) oder vom Switch am Einspeiseport mit dem Tag versehen. Daher kann ein Switch ein Paket ohne jegliche Änderung in einen Trunk einspeisen.
Kollisions- und Broadcastdomäne
Kollisionsdomäne: alle Stationen auf einem gemeinsamen Medium
Teilen sich mehrerer Endgeräte ein Medium (Netzwerkkabel, WLAN, etc.), spricht man von einem shared medium. Zusammen bilden sie eine Kollisionsdomäne. Senden zwei oder mehrere Endgeräte gleichzeitig, so kommt es zu Kollisionen auf dem Medium. Steigt die Anzahl der Endgeräte, so steigt auch die Anzahl der Kollisionen. Sind zu viele Stationen vorhanden, dann ist gar keine Kommunikation mehr möglich und das Medium ist dauernd (durch Kollisionen) belegt.
Broadcastdomäne: alle Stationen eines Netzes
Eine Broadcast-Meldung ist eine Rundsendung an alle Netzwerkteilnehmer. Die Menge der Stationen, die eine Broadcastmeldung empfangen, bildet eine Broadcastdomäne.
Durch VLANs verringert sich der Traffic auf einer Kollisionsdomäne durch Reduzierung der Broadcastmeldungen, da VLANs die Broadcastdomäne verkleinern.
Unicast, Multicast, Broadcast und Anycast
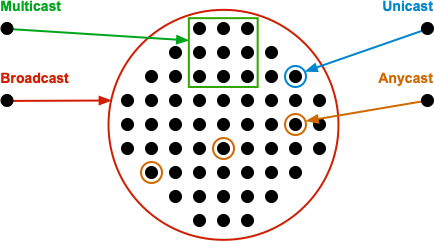
Netzwerk-Topologien beschreiben, wie die Teilnehmer eines Netzwerks physikalisch zusammengeschaltet sind. Darauf aufbauend werden dann logische Verbindungen geschaltet. Die Verbindungsart bzw. die Beschreibung des Verbindungsziels hat dabei Einfluss auf die Adresse und die Übertragung.
Unicast
Bei Unicast sind zwei Stationen miteinander verbunden. Sie können direkt oder über ein Netzwerk miteinander kommunizieren. Die Verbindung kann sowohl unidirektional als auch bidirektional sein.
Beim Unicasting steigt die notwendige Bandbreite bei jedem zusätzlichen Host im Netzwerk an. Dabei kann die Netzlast soweit steigen, dass die Informationen bei keinem Host mehr in ausreichender Geschwindigkeit ankommt. So kommt es beim Audio- und Video-Streaming zu Aussetzern beim Abspielen.
Multicast
Bei Multicast gibt es einen Sender, der zu einer definierten Gruppe von Empfängern Signale, Daten und Informationen überträgt. Hier spielt es keine Rolle, wie viele Empfänger die Daten empfangen. Die Bandbreite wird nur für einen Teilnehmer verbraucht. Die letzte Verteilstelle (Router) ist dann für die Verteilung an die einzelnen Empfänger verantwortlich. Die Daten werden beim letzten Router dupliziert.
Broadcast
Der Broadcast ist ein Datenpaket, dass an einem Punkt ins Netzwerk eingespeist und von dort an alle Hosts übertragen wird. Dabei empfängt jeder Host die Daten, ob er will oder nicht. Es handelt sich dabei um das klassische Gießkannenprinzip bei der Verteilung von Informationen, wie es zum Beispiel beim Rundfunk (UKW/DAB) oder Fernsehen (Satellit, Kabel, Funk) gemacht wird.
Anycast
Bei Anycast geht die Nachricht an einen Empfänger aus einer Gruppe von Empfängern. An wen aus der Gruppe ist hierbei egal. Hinter Anycast steckt das Verständnis, dass es eine Adresse mehrfach gibt bzw. geben kann (Anycast-Adresse). Das bedeutet dann aber, dass kein wechselseitiger Dialog möglich ist, weil nicht sicher ist, ob man immer mit der selben Maschine verbunden ist.
Anycast wird bspw. für Root-Nameserver benutzt. Hier gibt es nicht nur einen Root-Server, sondern in der Regel ganz viele davon, die auf der ganzen Welt verteilt sind. Aber alle haben die selbe Adresse. Ein Router kennt die Route zu einem von diesen Root-Servern und reicht das Anycast-Paket an diesen weiter.
WLAN-Authentifizierung
IEEE 802.1X
IEEE 802.1x ist ein sicheres Authentifizierungsverfahren für Zugangskontrollen in lokalen Netzwerken (LAN). Im Zusammenhang mit IEEE 802.1x werden auch häufig EAP und RADIUS genannt.
Der Standard definiert drei grundlegende Funktionskomponenten. Diese sind:
- der Antragsteller (Supplicant): zum Beispiel ein Rechner in einem LAN oder WLAN
- der Unterhändler (Authenticator): zum Beispiel ein LAN-Switch oder WLAN-Accesspoint
- der Authentifizierungsserver (Authentication Server): zum Beispiel ein RADIUS-Server
Ein Client, der Zugang zu einem LAN oder WLAN benötigt, wendet sich zunächst an den Unterhändler. Er sendet seine Anmeldedaten an einen Authenticator (zum Beispiel Switch oder WLAN-Accesspoint). Der Informationsaustausch findet per Extensible Authentication Protocol (EAP) statt. Der Authenticator nimmt die Anfrage entgegen und leitet die Anmeldeinformationen an den Authentication Server (zum Beispiel einen separaten RADIUS-Server) weiter. Der Authentication Server ist für die Benutzerverwaltung und -authentifizierung zuständig. Er prüft die erhaltenen Anmeldeinformationen und teilt das Ergebnis dem Authenticator mit. Dieser schaltet abhängig von der Prüfung der Anmeldedaten den logischen oder physischen Zugang zum lokalen Netzwerk (zum Beispiel einen Switch-Port) frei oder verweigert den Zugang.
Funktionen von .1x
- Zugangskontrolle
- Authentifizierung, Autorisierung und Accounting (AAA)
- Bandbreitenzuweisung (QoS)
- Single Sign-on (SSO)
AAA-Server (Authentifizierung, Autorisierung und Accounting)
„Authentication Authorization Accounting“, kurz AAA, steht für ein Sicherheitskonzept in dem die drei Hauptaufgaben Authentifizierung, Autorisierung und Accounting zusammengefasst sind. Mit AAA kann man die Zugangskontrolle in einem Netzwerk organisieren.