2. Abschlussprüfung
- ITS
- Subnetting
- Aufbau / Planung WLAN-Netzwerk
- Routing
- VPN (E2E, E2S, S2S)
- IT-Security
- Backupstrategien
- DMZ
- Proxy
- Zertifikate
- Symmetrisch / Asymmetrische Leitungen
- RAID-Level
- IPv6
- Strukturierte Verkabelung
- NAT/PAT
- Firewall
- Verschlüsselung
- Bootloader & Partitionstabellen
- Gängige Ports im Internet
- Logische Operatoren
- Berechnungshilfe
- VLAN
- Unicast, Multicast, Broadcast und Anycast
- WLAN-Authentifizierung
- SAE
- HTML
- Struktogramme
- Datenbanken
- Pseudocode
- Python
- Web Requests
- Sortieralgorithmen
- Polymorphismus & Überladen
- Programmierparadigmen
- CSS - Cascading Style Sheet
- Entity-Relationship-Modell
- BWL
- Angebotsvergleich
- Handelskalkulation
- Break-Even-Point / Gewinnschwelle
- EPK's
- Bilanzen
- Einfacher Buchungssatz
- Lineare Abschreibungen
- Bestellverfahren
- Projektmanagement - Magisches Dreieck und Methoden
- WI
- 1 - Die Rolle des Mitarbeiters in der Arbeitswelt aktiv ausüben
- 2 - Als Konsument rechtliche Bestimmungen in Alltagssituationen anwenden
- 3 - Wirtschaftliches Handeln in der Sozialen Marktwirtschaft beurteilen
- 4 - Entscheidungen im Rahmen einer beruflichen Selbstständigkeit treffen
- Drei-Säulen-Modell (Nachhaltigkeit)
- Unternehmenszusammenschlüsse
ITS
Abschlussprüfung Teil 2
Subnetting
Beim Subnetting geht es darum, den IP-Adressraum in kleinere Teile zu zerschneiden.
Dies wird aus verschiedenen Gründen gemacht:
- Sicherheit: Zwischen den Subnetzen kann der Traffic von einer Firewall/Router mithilfe von Paketfiltern kontrolliert werden. Im Falle eines Sicherheitsvorfalls sind Geräte in anderen Subnetzen geschützt. Bei der Verwendung von Subnetzen ohne andere Schutzmechanismen (z.B. VLANs) ist aber Vorsicht geboten. Eine IP-Adresse kann einfach auf Client-Seite geändert werden.
- Broadcasts als Performancekiller: Viele Protokolle (DHCP, ARP etc) nutzen Broadcasts. Da Broadcasts an alle Geräte im Netzwerk geschickt werden, steigt bei großen Netzwerken mit vielen Hosts die Anzahl der Pakete und damit die Last im Netzwerk.
- Verwaltbarkeit: Mit Subnetzen kann eine logische Struktur im Netzwerk geschaffen, welche die Übersicht und damit die Verwaltung erleichtert. Zum Beispiel verschiedene Subnetze pro Firmenstandort oder Netze für Server, Clients etc.
IPv4 Subnetting
Subnetzmaske
Zu jeder IP-Adresse wird die Subnetzmaske angegeben.
IPv4: 192.168.178.10/24
Subnetzmaske: 255.255.255.0Die Subnetzmaske gibt an, wie viele der 32 Bits einer IP-Adresse die Netzadresse darstellen. Die Bits des Netzanteils werden binär mit 1 und die Bits des Hostanteils mit 0 angegeben. Nach einer 0 darf keine 1 mehr folgen. Die Anzahl der möglichen Subnetze/Hosts erhält man, indem man 2^(Anzahl Bits) rechnet.
Die Subnetzmaske 255.255.255.0 entspricht binär 11111111 11111111 11111111 00000000. Folglich stellen die ersten 24 Bit den Netzanteil und die verbleibenden 8 Bit den Hostanteil dar.
Die Subnetzmaske kann auf zwei Arten aufgeschrieben werden. In der alten Schreibweise werden die 32 Bit, welche die Subnetzmaske hat, in 4 Blöcke zu je 8 Bit aufgeteilt und anschließend in Dezimalzahlen umgerechnet und mit Punkt getrennt aufgeschrieben werden, z.B. 255.255.255.0. Mittlerweile hat sich eine andere Darstellung etabliert. Bei dieser wird die Anzahl der Bits, welche zum Netzanteil gehören, mit einem "/" hinter die IP-Adresse geschrieben, z.B. 192.168.178.10/24, was der oben genannten Subnetzmaske 255.255.255.0 entspricht.
Um von CIDR in die herkömmliche Notation zu kommen, muss man lediglich die die 32 Bit einer IP Adresse aufschreiben und von links nach rechts die Anzahl der Bits auf 1 setzen, die in CIDR angegeben ist, und anschließend den 8er-Block in dezimal umrechnen, in dem nicht alles 1 oder 0 ist. Blöcke in denen alles 1 ist sind 255, Blöcke in denen alles 0 ist sind 0.
Bei allen Subnetzmasken, die mit 255 enden (in CIDR vielfache von 8 sind), kann man sich die Dotted-Dezimal-Schreibweise der IP-Adresse zu nutze machen, denn in dem Fall ist die Grenze zwischen Netzanteil und Hostanteil genau auf einem Punkt und damit sehr einfach abzulesen.
| Subnetzmaske CIDR |
Subnetzmaske Dotted-Dezimal |
Format (X = Netzanteil, Y = Hostanteil) |
| /8 |
255.0.0.0 |
X.Y.Y.Y |
| /16 |
255.255.0.0 |
X.X.Y.Y |
| /24 |
255.255.255.0 |
X.X.X.Y |
Gibt es in der Subnetzmaske einen Block, welcher nicht 255 oder 0 ist, lassen sich Netz-und Hostanteil nur bestimmen, indem der Block binär betrachtet wird.
Beispiel
Subnetzmaske: 255.255.224.0Die Blöcke 1, 2 und 4 sind uninteressant. Block 1 und 2 gehören fest zum Netzanteil, Block 4 gehört fest zum Hostanteil. Im 3. Block befindet sich die Grenze zwischen Netz-und Hostanteil. Die 224 ist binär 1110 0000, folglich gehören die ersten 3 Bit des Blocks zum Netzanteil und die weiteren 5 Bit zum Hostanteil. Über die gesamten 32 Bit betrachtet sind die ersten 19 Bit dem Netzanteil und die restlichen 13 Bit dem Hostanteil zugehörig. Folglich wäre die Subnetzmaske als "/19" darzustellen.
Anzahl Subnetze und Anzahl Hosts in einem Subnetz
Um die Anzahl der möglichen Subnetze und möglichen Hosts in einem Subnetz muss man lediglich 2^(Anzahl der Bit) rechnen. Beim Hostanteil gibt es die Besonderheit, dass die erste (alle Bit des Hostanteils auf 0) und die letzte (alle Bit des Hostanteils auf 1) mögliche IP nicht für Hosts nutzbar sind, da sie für Netzadresse und directed Broadcast reserviert sind. Bei der Bildung von Subnetzen muss dies beachtet werden, denn man braucht immer 2 Adressen mehr als man Hosts in dem Netz haben möchte. Bei 4 Hosts müssen 3 Bit verwendet werden, da 6 Adressen benötigt werden. 2 Bit reichen nicht.
Bei einer Subnetzmaske von 255.255.255.0 oder CIDR "/24" sind 2^24 Subnetze möglich mit jeweils 2^8 - 2 (Netz-und Broadcast-Adresse) Hosts pro Subnetz.
Berechnen der Netz-Adresse
Anhand einer IP-Adresse und der zugehörigen Subnetzmaske kann die Netz-Adresse berechnet werden. Dazu muss man zunächst IP-Adresse und Subnetzmaske in die binäre Schreibweise bringen und diese anschließend mit einem logischen UND miteinander verknüpfen.
| IP-Adresse |
192.168.178.10 |
11000000 10101000 10110010 00001010 |
| Subnetzmaske |
255.255.255.0 |
11111111 11111111 11111111 00000000 |
| logisches UND | ||
| Netz-Adresse | 192.168.178.0 |
11000000 10101000 10110010 00000000 |
Subnetze bilden
gegeben:
IP: 10.0.23.192/25
Subnetzmaske: 255.255.255.128
Aufgabe:
- 4 Subnetze erstellen
- 4 Hosts (Subnetz 1), 12 Hosts (Subnetz 2), 31 Hosts (Subnetz 3), 6 Hosts (Subnetz 4)
- keine LückenIm ersten Schritt wird notiert, wie viele Hosts in dem Subnetz benötigt werden, wie viele Host-Bits dafür nötig sind, mit wie vielen Bit die Subnetzmaske erweitert wird (zusätzliche Netz-Bits) und wie die Subnetzmaske des Subnetzes aussieht. Es ist sinnvoll, die zu erstellenden Subnetze bereits hier nach Größe vom größten zum kleinsten zu sortieren.
Erinnerung: Da die erste und letzte Adresse eines Subnetzes reserviert sind, werden immer 2 Adressen mehr benötigt als Hosts in dem Netzwerk sind.
| Subnetz |
Anzahl Hosts |
Anzahl nötiger Host-Bits |
Anzahl zusätzlicher Netz-Bits |
CIDR |
Subnetzmaske |
| 3 |
31 + 2 |
6 (max. 64 Hosts) |
1 |
/26 |
255.255.255.224 |
| 2 |
12 + 2 |
4 (max. 16 Hosts) |
3 |
/28 |
255.255.255.240 |
|
1 |
4 + 2 |
3 (max. 8 Hosts) |
4 |
/29 |
255.255.255.248 |
| 4 |
6 + 2 |
3 (max. 8 Hosts) |
4 |
/29 |
255.255.255.248 |
Anschließend muss zunächst die Netzadresse des Bereichs gefunden werden, in dem die Subnetze gebildet werden. Hierfür wird die gegebene IP-Adresse und Subnetzmaske mit einem logischen UND verknüpft. Es muss nur der Block betrachtet werden, der nicht 255 und 0 ist, d.h. der Block mit der 128.
| 10.0.23.192 |
1100 0000 |
|
| 255.255.255.128 |
1000 0000 | |
| UND |
10.0.23.128 |
1000 0000 |
Der Bereich, der für die Bildung der Subnetze zur Verfügung steht, ist der Bereich zwischen 10.0.23.128 und 10.0.23.255.
Anschließend fängt man mit der ausgerechneten Netzadresse an und bildet die Subnetze (die Subnetzmaske hat man ja bereits herausgefunden).
Die Netzadresse des 1. Subnetzes ist identisch mit der Netzadresse des gesamten gegebenen Netzbereichs (die Subnetzmaske aber nicht). Anhand der Anzahl der Host-Bits kann man die Anzahl der möglichen Adressen des Subnetzes berechnen. Dies hilft bei der Errechnung der Netzadressen, da man einfach auf die Netzadresse des vorigen Netzwerks die Anzahl der Adressen dazuaddieren kann, um auf die Netzadresse des Folgenetzes zu kommen.
| Subnetz |
Netzadresse |
erster Host |
letzter Host |
Broadcast |
Subnetzmaske |
| 3 |
10.0.23.128 |
10.0.23.129 |
10.0.23.190 |
10.0.23.191 |
255.255.255.224 bzw. /26 |
| 2 |
10.0.23.192 | 10.0.23.193 |
10.0.23.206 |
10.0.23.207 |
255.255.255.240 bzw. /28 |
| 1 |
10.0.23.208 |
10.0.23.209 |
10.0.23.214 |
10.0.23.215 |
255.255.255.248 bzw. /29 |
| 4 | 10.0.23.216 |
10.0.23.217 |
10.0.23.222 |
10.0.23.223 |
255.255.255.248 bzw. /29 |
IPv6 Subnetting
Bei IPv6 wurde das Subnetting deutlich erleichtert. Während bei IPv4 Host-und Netzanteil variabel sind und mithilfe der Subnetzmaske nach Belieben verändert werden können, sind Netzanteil und Hostanteil fix jeweils 64 Bit lang, was bedeutet, dass es 2^64 verschiedene Netze und pro Netz 2^64 Hosts geben kann. Die Subnetzmaske ist nicht mehr nötig bzw. ist sie bei einem Client immer /64, da die ersten 64 Bit der Adresse immer das Netz angeben. Bei IPv6 werden die Subnetze im Bereich zwischen Präfix und Anfang des Hostanteils gebildet. Hier kommt es darauf an, welche Länge das IPv6-Präfix hat, welches einem vom Provider zugewiesen wurde. Das Präfix wird wie die Subnetzmaske in CIDR-Notation angegeben, z.B. "/48". Bei einem Präfix mit einer Länge von 48 Bit (CIDR: /48) hat man also 16 Bit, mit denen man Subnetze bilden kann.
Privatkunden bekommen in der Regel ein /64 Prefix zugeteilt, d.h. es können keine Subnetze gebildet werden.
Zwischen dem Ende des zugeteilten Präfix und dem Ende des Netzanteils der IPv6-Adresse (die ersten 64 Bit), können Subnetze gebildet werden. Bei Präfixlängen, welche durch 4 teilbar sind, liegt die Grenze zwischen Präfix und Teil für Subnetting auf zwischen 2 Stellen, d.h. die Subnetze können durch simples hexadezimales Hochzählen (0-9, A-F) gebildet werden. Ist dies nicht der Fall, muss die Stelle, in der die Grenze verläuft, binär betrachtet werden.
Der Hostanteil ist bei IPv6 fest 64 Bit lang, d.h. der Denksport wie bei IPv4 entfällt vollständig.
Beispiel 1
gegebenes Präfix: 2001:db8:db8:b008/62Zwischen Präfix und sind 2 Bit, d.h. es können 2^2 (4) Subnetze gebildet werden. Eine Stelle wird bei einer IPv6 Adresse als Hexadezimal-Ziffer geschrieben. Jede Hexadezimal-Ziffer kann durch 4 Bit repräsentiert werden. Da 62 nicht ohne Rest durch 4 teilbar ist, verläuft die Grenze zwischen Präfix und Subnetzteil nicht zwischen 2 Stellen, sondern innerhalb einer Stelle (hier vor den letzten 2 Bit der letzten Stelle). Diese muss daher binär betrachtet werden. Man zählt binär innerhalb der Bit hoch, in welchem die Subnetze gebildet werden, die anderen Bit bleiben stehen.
| Subnetz |
Netz-Präfix |
hex |
Netzadresse |
| 1 |
2001:db8:db8:b00[1000]/64 |
8 |
2001:db8:db8:b008/64 |
| 2 |
2001:db8:db8:b00[1001]/64 | 9 |
2001:db8:db8:b009/64 |
| 3 |
2001:db8:db8:b00[1010]/64 | a |
2001:db8:db8:b00a/64 |
| 4 |
2001:db8:db8:b00[1011]/64 | b |
2001:db8:db8:b00b/64 |
Beispiel 2
gegebenes Präfix: 2001:db8:db8:b000/56Bei der Präfixlänge 60 sind 8 Bit für Subnetze übrig, d.h. es können 2^8 (256) Subnetze gebildet werden. Da 56 durch 4 teilbar ist, verläuft die Grenze zwischen Präfixanteil und Subnetzteil zwischen 2 Stellen (im Beispiel vor der vorletzten Stelle des Netzanteils), d.h. Subnetze können durch simples hexadezimales Hochzählen gebildet werden.
| Subnetz |
Netzadresse |
| 0 |
2001:db8:db8:b000/64 |
| 1 |
2001:db8:db8:b001/64 |
| 2 |
2001:db8:db8:b002/64 |
| 3 |
2001:db8:db8:b003/64 |
| ... |
... |
| 10 | 2001:db8:db8:b00a/64 |
| ... |
... |
| 15 |
2001:db8:db8:b00f/64 |
| 16 |
2001:db8:db8:b010/64 |
| ... |
... |
| 31 |
2001:db8:db8:b01f/64 |
| 32 |
2001:db8:db8:b020/64 |
| ... |
... |
| 47 |
2001:db8:db8:b02f/64 |
| ... |
... |
| 63 |
2001:db8:db8:b03f/64 |
| ... |
... |
| 79 |
2001:db8:db8:b04f7/64 |
| ... |
... |
| 95 |
2001:db8:db8:b05f/64 |
| ... |
... |
| 255 |
2001:db8:db8:b0ff/64 |
Aufbau / Planung WLAN-Netzwerk
Festlegen von Anforderungen
Es empfiehlt sich, die Anforderungen und Ziele an ein WLAN-Netzwerk zu bestimmen. Dies ist ein wichtiger Schritt, denn manche Ziele stehen im Widerspruch zueinander. Zum Beispiel könnte ein Unternehmen Wert auf eine große Umgebung legen, um viele Videoclients zu unterstützen, die alle auf der 2,4-GHz-Frequenz arbeiten. Diese beiden Anforderungen wären aufgrund der geringeren Bandbreite der Frequenz nicht miteinander vereinbar.
Eine gründliche Bewertung vor der Installation kann den Teams helfen, Konflikte zu vermeiden und die
Geschäftsanforderungen zu erfüllen.
Durchführen von Standortanalysen vor der Installation
In diesem Prozess gilt es unter anderem, die Grundrisse zu berücksichtigen, die Wanddämpfung zu prüfen und die Ausbreitung der Funkfrequenzen zu messen. Im Wesentlichen lässt sich mit Standortanalysen herausfinden, wo die besten Standorte für die Montage von Access Points (AP) sind, um eine optimale Abdeckung zu erreichen. Standortanalysen können auch Problembereiche bei bestehenden Designs aufzeigen.
Eine weitere Möglichkeit, WLAN-Probleme zu beurteilen, besteht darin, mit Mitarbeitende zu sprechen, die in der Nähe der Abdeckungsbereiche arbeiten. Sie werden höchstwahrscheinlich in der Lage sein, Stellen mit schlechtem Empfang, Signalausfällen und Signalverlusten präzise zu lokalisieren.
Auch ein wichtiger Punkt bei der Wahl des Standortes ist die Verfügbarkeit bzw. Machbarkeit von PoE. Mit „Power over Ethernet“ ist die Stromversorgung von verschiedenen netzwerkfähigen Geräten über das LAN-Kabel gemeint. Dabei übernimmt das Kabel sozusagen nicht nur die Versorgung mit Daten, sondern auch mit Energie. Der Vorteil dieser Technik liegt auf der Hand: Man kann das Stromkabel einsparen. Das wiederum vermeidet Kabelsalat, spart auf engem Raum Platz und meist auch Installationskosten.
Erkunden der Umgebung
Eine der einfachsten Möglichkeiten, ein Gefühl für die Situation in den Versorgungsgebieten zu bekommen, ist eine Umgebungsbegehung. Teams können sehen, wie die Racks und Kabel organisiert sind, prüfen, ob die APs richtig beschriftet wurden, und kontrollieren, in welchem Zustand sich das Data Center befindet.
Das IT-Team sollte darauf zu achten, wo und wie die APs angebracht sind. Einige der Faktoren, die es zu überprüfen gilt:
- APs für die Deckenmontage, die an Wänden installiert sind.
- Falsch ausgerichtete Richt- oder Patch-Antennen.
- LED-Anzeigen an APs.
- AP-Ausbreitungsmuster.
- Interferenzen, wenn zwei APs versuchen, dieselbe Frequenz zu nutzen.
In diesem Zusammenhang können die IT-Teams auch Umgebungsfaktoren wie Metallregale, Weihnachtsbäume, Mikrowellengeräte und ungünstige AP-Standorte berücksichtigen. Es ist ebenfalls wichtig, den physischen Zugang zu den IT-Bereichen ordnungsgemäß zu sichern, damit niemand einfach hereinspazieren und auf das Netzwerk zugreifen kann.
Potenzielle AP-Upgrades beobachten
Eine weitere Best Practice besteht darin, die Hardwareversionen und Software-Updates der verschiedenen drahtlosen Geräte zu kontrollieren. Überwachen Sie deren Alter, beachten Sie Meldungen über Sicherheitslücken. Vergessen Sie nicht das Patchen, das eine wichtige Sicherheitsmaßnahme ist, um Ransomware-Angriffe zu verhindern.
In einigen Fällen kann für IT-Teams ein Upgrade der Geräte kostengünstiger sein als eine Umgestaltung des WLAN-Netzwerks. Neuere APs verfügen über erweiterte Fähigkeiten und bieten mehr Reichweite, bessere Funktionen und Kontrolle.
Management-Tools
Per Event Reporting, wie Syslog- und SNMP-Traps (Simple Network Management Protocol), können die Geräte auftretende Probleme an das Netzwerkmanagementsystem melden. Die IT-Abteilung kann dann diese Ereignisse überwachen und die Probleme beheben.
Digital Experience Monitoring (DEM) ist eine weitere Option, die Endpoint Monitoring, Real User Monitoring und Synthetic Transaction Monitoring vereint. Mit dieser Kombination kann DEM die Application Experience eines Endpunkts überwachen und Probleme bei Clients, Anwendungen und im Netzwerk erkennen.
Standortanalysen nach der Installation
Zu guter Letzt sollte die IT-Abteilung eine Standortanalyse nach der Installation durchführen, um festzustellen, ob sich die erwartete Abdeckung erreichen lässt.
WPA2 und WPA3
2,4 GHz und 5 GHz
Routing
Routing dient dazu, den Pfad eines Pakets über ein oder mehrere Netze zu bestimmen.
MAC-und IP-Adressen beim Routing
Das folgende Bild zeigt ein ICMP Paket im Netz des Senders (grün = IP + MAC des Quell-Rechners; blau = MAC/IP-Adresse des Ziel-Rechners; gelb = TTL; schwarz = Prüfsumme; rot = MAC des Gateways im Subnetz):
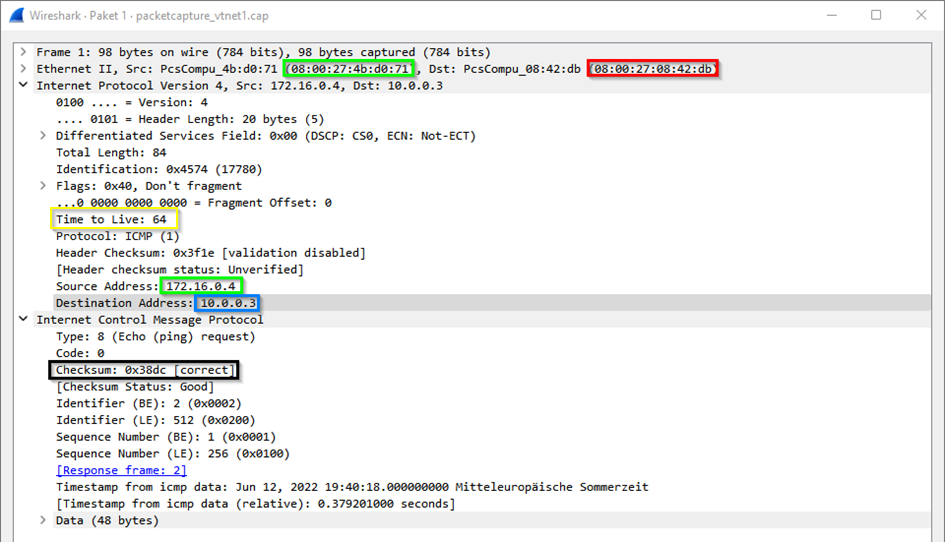
Im Subnetz des Ziels sieht das Paket so aus:
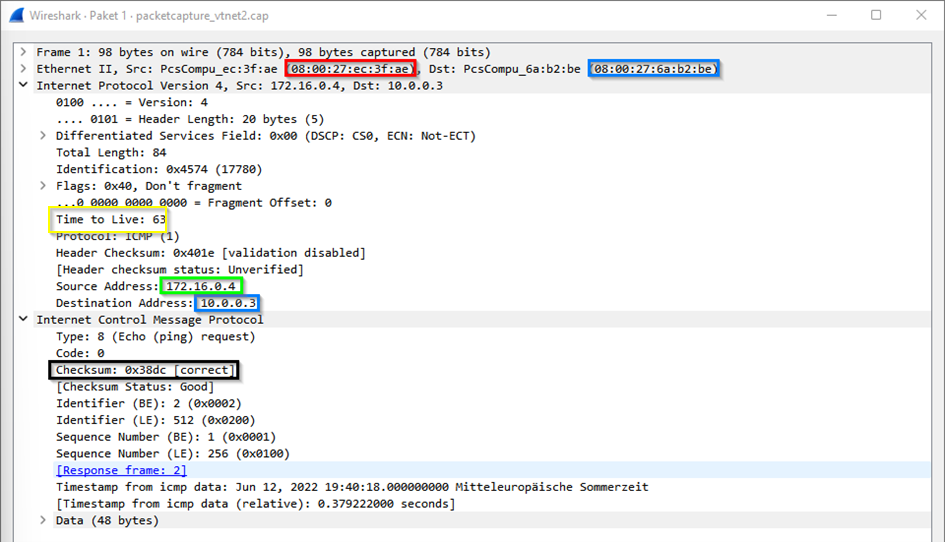
Die Prüfsumme zeigt, dass es sich um dasselbe Paket handelt. Die IP-Adressen haben sich nicht geändert. Geändert haben sich die MAC-Adressen und die TTL (time to live) des Pakets.
Innerhalb eines Subnetzes wird ausschließlich über MAC-Adressen mit anderen Geräten kommuniziert. Zur Auflösung von IP-Adressen in MAC-Adressen wird das Address Resolution Protocol (ARP) verwendet. Befindet sich der Empfänger in einem anderen Subnetz, ändern Router Quell-und Ziel-MAC-Adresse, um das Paket weiterzuleiten.
Die TTL ist eine Zahl, welche von jedem Router, über den das Paket wandert, um 1 reduziert wird. Sie soll verhindern, dass Pakete ziellos im Netzwerk umherwandern. Erreicht sie 0, wird das Paket vom nächsten Router verworfen, den es erreicht. Bei ungünstigen Routen kann es unter Umständen sein, dass Pakete ihr Ziel nicht erreichen können, weil zwischen Sender und Empfänger zu viele Hops (Router) liegen.
Routingtabellen
Anhand ihrer Routingtabellen entscheiden Router und Clients, wohin sie ihre Pakete schicken, damit diese am Ziel ankommen. In der Routingtabelle stehen also folglich alle Ziele und wie diese erreicht werden können.
Ein Client mit Windows/Linux/Mac routet in der Standardeinstellung nicht, d.h. er leitet keine Pakete anhand seiner Routingtabelle weiter, die er erhält, auch wenn er den Weg zum Ziel kennt. Dafür benötigt man eine Routing-Software oder einen Router in Hardware.
Ein Eintrag in einer Routingtabelle besteht aus folgenden Angaben:
| Ziel | Adresse des zu erreichenden Empfängers (dies kann die Adresse eines Subnetzes oder eines Hosts sein) |
| Netzwerkmaske |
Subnetzmaske des Ziels 0.0.0.0 (CIDR /0) ist keine Netzmaske 255.255.255.255 (CIDR /32) schließt nur die IP des Ziels ein |
| Gateway bzw. next hop | Adresse, an welche ein Paket für den Empfänger geschickt werden soll |
| Schnittstelle | über welches Interface soll das Paket geschickt werden |
| Metrik | Kann das Ziel über 2 Routen erreicht werden, bestimmt die Metrik, welche Route genommen wird. Die Metrik einer Route kann anhand von verschiedenen Parametern bestimmt werden, z.B. der Anzahl der Hops zum Ziel oder der Geschwindgkeit der Route. Die Route mit der geringeren Metrik wird bevorzugt. |
Einsehen und Ändern der Routingtabelle
Unter Windows gibt es den Befehl "route" zum Einsehen und Ändern der Routingtabelle. Dessen grundlegende Syntax sieht folgendermaßen aus:
route [<command> [<destination>] [mask <netmask>] [<gateway>] [metric <metric>] [if <interface>]]Der Befehl kennt folgende "commands":
| gibt einen (bei Angabe eines Ziels), ansonsten alle Einträge der Routingtabelle aus | |
| add | Hinzufügen einer statischen Route (Angabe des Ziels ist notwendig) |
| delete | Löscht eine Route in der Routingtabelle (Angabe des Ziels ist notwendig) |
| change | Ändert einen Eintrag in der Routingtabelle (Angabe des Ziels ist notwendig) |
Besondere Ziele
Default-Route
Das Ziel 0.0.0.0/0 in einer Routingtabelle steht für die Default-Route. Ist kein passender Eintrag für ein Paket vorhanden, wird die IP-Adresse des Gateways dieses Eintrags mittels ARP-Protokoll aufgelöst und als Empfänger die ermittelte MAC-Adresse in das Ethernet-Frame eingetragen. Es können mehrere Default-Routen definiert sein, um den Ausfall eines Gateways zu kompensieren.
Loopback
Das Netz 127.0.0.0/8 bzw. 127.0.0.0 mit Subnetzmaske 255.0.0.0, also die IP-Adressen 127.0.0.1 bis 127.255.255.255, ist für Loopback-Traffic reserviert. Dieser verlässt das Interface nicht, sondern wird intern an es zurückgeschickt.
Limited Broadcast
Die IP-Adresse 255.255.255.255 mit der Subnetzmaske 255.255.255.255 (CIDR: /32) ist eine spezielle IP-Adresse, welche zum Limited Broadcast gehört. Ein Paket, welches an diese IP-Adresse geschickt wird, wird an alle Geräte im Subnetz geschickt. Es verlässt das aktuelle Subnetz nicht und kann nicht geroutet werden. Jedes Netz, mit dem das Gerät verbunden ist, hat einen Eintrag mit der Limited Broadcast Adresse.
Multicast
Das Netz 224.0.0.0 mit der Subnetzmaske 240.0.0.0 bzw. 240.0.0.0/4 (CIDR) ist für Multicast reserviert, d.h. für Traffic, welche an eine Gruppe von Systemen gerichtet ist, z.B. an alle Router oder alle DHCP-Server in einem Netz. Jedes Netz hat einen Eintrag für das Multicast-Netz.
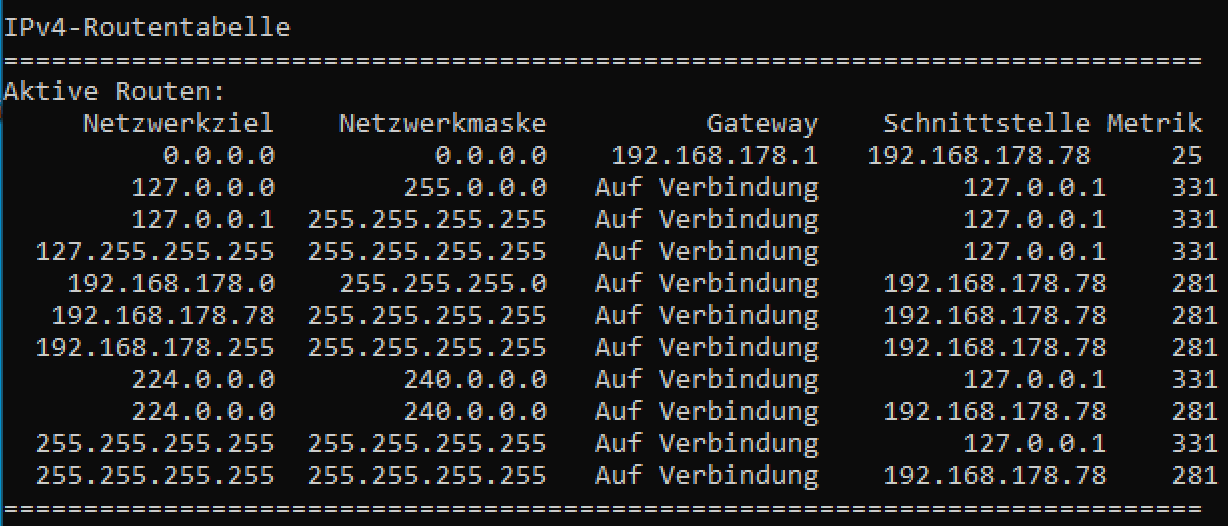
Lesen einer Routing Tabelle anhand eines Beispiels
Die Einträge der Routingtabelle aus der oberen Abbildung haben die folgenden Bedeutungen.
| Ziel |
Netzwerkmaske | Gateway/Next Hop | Schnittstelle |
Metrik |
Bedeutung |
| 0.0.0.0 | 0.0.0.0 | 192.168.178.1 | 192.168.178.78 |
25 |
Pakete ohne expliziten Eintrag werden an 192.168.178.1 über das Interface mit der IP 192.168.178.78 gesendet (Default Route) |
| 127.0.0.0 | 255.0.0.0 |
- | 127.0.0.1 |
331 |
Pakete an das Loopback-Netz werden über das Interface mit der IP 127.0.0.1 gesendet |
| 127.0.0.1 | 255.255.255.255 | - | 127.0.0.1 |
331 |
Pakete an die Loopback-Adresse 127.0.0.1 werden über das Interface mit der IP 127.0.0.1 gesendet |
| 127.255.255.255 | 255.255.255.255 |
- | 127.0.0.1 |
331 |
Pakete an die Broadcast-Adresse des Loopback-Netzes werden über das Interface mit der IP 127.0.0.1 gesendet (directed broadcast) |
| 192.168.178.0 | 255.255.255.0 | - |
192.168.178.78 |
281 |
Pakete an das Netz 192.168.178.X werden über das Interface mit der IP 192.168.178.78 gesendet |
| 192.168.178.78 | 255.255.255.255 | - | 127.0.0.1 |
281 | Pakete an die eigene IP 192.168.178.78 werden über das Interface mit der IP 127.0.0.1 gesendet |
| 192.168.178.255 |
255.255.255.255 | - |
192.168.178.78 |
281 |
Pakete an die Broadcast-Adresse des Netzes 192.168.178.X werden über das Interface mit der IP 192.168.178.78 gesendet |
| 224.0.0.0 | 240.0.0.0 | - |
127.0.0.1 |
331 |
Pakete an das Multicast-Netz werden über das Interface mit der IP 127.0.0.1 gesendet |
| 224.0.0.0 | 240.0.0.0 | - | 192.168.178.78 |
281 |
Pakete an das Multicast-Netz werden bevorzugt (Metrik 281 vs 331) über das Interface mit der IP 192.168.178.78 gesendet |
| 255.255.255.255 | 255.255.255.255 | - | 127.0.0.1 |
331 |
Pakete an die Limited Broadcast IP werden über das Interface mit der IP 127.0.0.1 gesendet |
| 255.255.255.255 |
255.255.255.255 |
- |
192.168.178.78 |
281 |
Pakete an die Limited Broadcast IP werden bevorzugt (Metrik 281 vs 331) über das Interface mit der IP 192.168.178.78 gesendet |
Wie kommen Routen in die Routing-Tabelle
Direkt angeschlossene Netze
Wird einem Interface eine IP mit Subnetzmaske zugewiesen, werden für dieses Netzwerk automatisch Einträge in der Routingtabelle generiert.
Statisches Routing
Routen können manuell in die Routingtabelle eingetragen werden. Unter Windows geschieht dies unter anderem mit dem oben erklärten "route" Befehl.
Dynamisches Routing
Bei weit verzweigten Netzwerken wie dem Internet ist das manuelle Pflegen der Routingtabellen äußerst aufwändig und fehleranfällig. Stattdessen gibt es Protokolle (BGP Border Gateway Protocol, OSPF Open Shortest Path First, RIP Router Information Protocol, IGRP Interior Gateway Routing Protocol), welche es Routern erlauben, ihre Routingtabellen durch den Austausch von Informationen mit anderen Routern dynamisch aufzubauen. Beim dynamischen Routing kommen im Wesentlichen 2 Algorithmen zum Einsatz:
Beim Distance Vector Algortihmus sendet jeder Router seine Routingtabelle regelmäßig via Broadcast an alle anderen Router im Netz, welche mit diesen Informationen ihre eigene Routingtabelle ergänzen. Da dies recht ineffizient ist und zu einem hohen Paketaufkommen innerhalb eines Netzwerks sorgt (Broadcastlawine), wurden einige Erweiterungen implementiert.
Beim Link State Algorithmus verursacht eine Änderung eines Routingeintrags ein Link State Announcement, welches an alle benachbarten Router geschickt wird. Diese ergänzen dadurch ihre Routintabelle. Da bei diesem Algorithmus nur bei Veränderungen Informationen ausgetauscht werden, ist dieser Algorithmus sehr effizient. Er ist die Implementierung des Djikstra-Algorithmus.
VPN (E2E, E2S, S2S)
VPN bedeutet Virtuelles Privates Netzwerk (aus dem Englischen „Virtual Private Network“). Eine VPN-Verbindung bietet die Möglichkeit, von außen auf ein bestehendes Netzwerk zuzugreifen. Dabei kann es sich um ein Unternehmens- aber auch um ein privates Netzwerk handeln.
Grundsätzlich gibt es drei Arten von VPNs, die in verschiedenen Szenarien zum Einsatz kommen.
End-to-End-VPN
Bei einem End-to-End-VPN werden zwei Clients miteinander verbunden. Dabei befindet sich ein Client innerhalb eines Netzwerks, der andere hingegen außerhalb. Diese Art von VPN ermöglicht beispielsweise den direkten Zugang zu einem Server im Netzwerk.
Um einen solchen VPN-Tunnel herzustellen, ist jedoch auf beiden Clients eine VPN-Software erforderlich. Die Verbindung wird allerdings nicht direkt hergestellt. Stattdessen geht man den Umweg über ein Gateway, mit dem sich beide Clients verbinden. Das Gateway sorgt dann dafür, dass die zwei aufgebauten Verbindungen zusammengeschaltet werden und eine direkte Kommunikation erfolgen kann.
End-to-Site-VPN
Über ein End-to-Site-VPN wird ein einzelner Client außerhalb eines Netzwerkes mit einem Unternehmensnetzwerk verbunden. Auch hier bedient man sich wiederum der öffentlichen Internetverbindung, um sich in das Unternehmensnetzwerk einzuwählen.
Verwendet wird diese Art von VPN beispielsweise für Heimarbeiter oder mobile Außendienstmitarbeiter, die sich von zuhause oder vom Kundentermin aus per Remote Access mit dem Unternehmensnetzwerk verbinden. Sie können es dann so nutzen als würden sie gerade im Betrieb sitzen.
Site-to-Site-VPN
Bei einem Site-to-Site-VPN werden mehrere lokale Netzwerke zusammengeschlossen. Im Gegensatz zur herkömmlichen Standleitung, die eine physikalische Verbindung zwischen den zwei Netzwerken herstellt, wird beim Site-to-Site-VPN eine Internetverbindung herangezogen. Dadurch können die hohen Kosten eingespart werden, die eine Standleitung mit sich bringt. Auf diese Weise können beispielsweise die lokalen Netzwerke eines Unternehmens mit mehreren Filialen oder Betrieben miteinander kommunizieren.
MPLS-VPN
Es handelt sich um ein in sich geschlossenes, privates IP-Netz, das vom Anbieter zur Verfügung gestellt und komplett gemanagt wird. MPLS (Multiprotocol Label Switching) ist eine Kombination von Switching und Routing. Bei MPLS ist der Transportweg von Datenpaketen im Unterschied zur „normalen“ Internet-Übertragung vorgegeben. Es handelt sich somit um eine Lösung, die die verbindungsorientierte Übertragung von Datenpaketen in einem eigentlich verbindungslosen Netz ermöglicht. So werden unnötige Umwege oder falsche Paketreihenfolgen bei der Datenübertragung beispielsweise zwischen Unternehmensstandorten verhindert. Auf diese Weise entstehen vordefinierte Pfade, da Pakete mit dem gleichen Label immer den gleichen Weg nehmen.
Vor- und Nachteile eines MPLS-VPN:
| + Stabile Qualität | – Höhere Kosten |
| + Gesicherte Bandbreite | – Weniger Flexibilität |
| + Geringer betrieblicher Aufwand |
Vorteile von VPN
- Kosteneinsparung durch Verzicht auf eine physikalische Standleitung
- Hohe Verfügbarkeit durch gute Netzabdeckung
- Höhere Abhörsicherheit
- Verschlüsselte Datenübertragung
- Bedienerfreundlichkeit
Neben diesen Vorteilen haben VPN außerdem den großen Vorteil, dass sie ohne großen Aufwand eingesetzt werden können. Es bedarf lediglich eines entsprechenden Clients, um sichere Verbindungen herzustellen.
Nachteile von VPN
- Geschwindigkeitseinbußen
- Webseiten-Blockaden
- Dubiose Anbieter
Transport vs Tunnel Mode
Im Transport Mode kommunizieren zwei Hosts direkt via Internet miteinander. In diesem Szenario lässt sich IPsec zum einen dazu nutzen, die Authentizität und Integrität der zu gewährleisten. Man kann also nicht nur sicher sein, mit wem man da gerade kommuniziert, sondern sich auch darauf verlassen, dass die Pakete nicht unterwegs verändert wurden. Per optionaler Verschlüsselung kann man zudem verhindern, dass Unbefugte die transportierten Inhalte mitlesen. Da hier zwei Rechner direkt über ein frei zugängliches Netz miteinander Daten austauschen, lassen sich jedoch Ursprung und Ziel des Datenstroms nicht verschleiern.
Der Tunnel Mode kommt stets dann zum Einsatz, wenn zumindest einer der beteiligten Rechner nicht direkt angesprochen, sondern als Security Gateway genutzt wird. In diesem Fall bleibt zumindest einer der Kommunikationspartner - der hinter dem Gateway - anonym. Tauschen gar zwei Netze über ihre Security Gateways Daten aus, dann lässt sich von außen gar nicht mehr bestimmen, welche Rechner hier tatsächlich miteinander sprechen. Auch im Tunnel Mode lassen sich natürlich Authentifizierung, Integritätskontrolle und Verschlüsselung einsetzen.
IT-Security
IT-Sicherheit reicht vom Schutz einzelner Dateien bis hin zur Absicherung von Rechenzentren und Cloud-Diensten. IT-Security gehört zu jeder Planung und Maßnahme in der IT und ist grundlegend für die Compliance im Unternehmen.
Unter IT-Sicherheit versteht man alle Planungen, Maßnahmen und Kontrollen, die dem Schutz der IT dienen. Der Schutz der IT hat drei klassische Ziele: Die Vertraulichkeit der Informationen, die Integrität der Informationen und Systeme und die Verfügbarkeit der Informationen und Systeme. Der Schutz der IT-Systeme vor Ausfall und die notwendige Belastbarkeit der IT-Systeme ist grundlegend für die Aufrechterhaltung des Geschäftsbetriebs, für die „Business Continuity“.
Im Gegensatz zur Datensicherheit geht es in der IT-Sicherheit nicht nur um personenbezogene Daten, für die der rechtlich geforderte Datenschutz Sicherheitsmaßnahmen verlangt. Es geht vielmehr um alle Arten von Informationen, die es zu schützen gilt.
Informationssicherheit
In der Informationssicherheit geht es allgemein um den Schutz von Informationen. Diese können auch in nicht-technischen Systemen vorliegen, zum Beispiel auf Papier. Die Schutzziele der Informationssicherheit bestehen darin, die Vertraulichkeit, Integrität und Verfügbarkeit von Informationen sicherzustellen.
In Deutschland gilt der IT-Grundschutz des Bundesamts für Sicherheit in der Informationstechnik (BSI) als Leitlinie für die Informationssicherheit.
Im Anhang A der ISO 27001 gibt es eine Liste von 114 Sicherheitsmaßnahmen zur Überprüfung des Sicherheitsniveaus in Unternehmen, sogenannte Controls. Zum Schutz des geistigen Eigentums können wir diese hier nicht einfach auflisten. Die 14 Abschnitte des Anhang A mit kurzer Erklärung:
- A.5 Informationssicherheitspolitik – Kontrollen, wie die Politik geschrieben und überprüft ist
- A.6 Organisation der Informationssicherheit – Kontrollen, wie die Verantwortlichkeiten zugewiesen sind, enthält auch die Kontrollen für Mobilgeräte und Telearbeit
- A.7 Personalsicherheit – Kontrollen vor, während und nach der Anstellung
- A.8 Asset Management – Kontrollen in Bezug auf das Asset-Verzeichnis und akzeptable Nutzung sowie auch für Informationsklassifizierung und Medien-Handhabung
- A.9 Zugriffskontrolle – Kontrollen für die Zugriffskontrollen-Richtlinie, die Benutzerzugriffsverwaltung, System- und Applikations-Zugriffskontrolle sowie Anwenderverantwortlichkeiten
- A.10 Kryptografie – Kontrollen in Bezug auf Verschlüsselung und Schlüsselverwaltung
- A.11 Physische und Umgebungssicherheit – Kontrollen, die Sicherheitsbereiche, Zutrittskontrollen, Schutz gegen Bedrohungen, Gerätesicherheit, sichere Entsorgung, Clear Desk- und Clear Screen-Richtlinie usw. definieren
- A.12 Betriebssicherheit – eine Menge an Kontrollen im Zusammenhang mit dem Management der IT-Produktion: Change Management, Capacity Management, Malware, Backup, Protokollierung, Überwachung, Installation, Schwachstellen usw.
- A.13 Kommunikationssicherheit – Kontrollen in Bezug auf Netzwerksicherheit, Segregation, Netzwerk-Services, Informationstransfer, Nachrichtenübermittlung etc.
- A.14 Systemerwerb, Entwicklung und Wartung – Kontrollen, die Sicherheitsanforderungen und die Sicherheit in Entwicklungs- und Support-Prozessen definieren
- A.15 Lieferantenbeziehungen – Kontrollen, was in Vereinbarungen zu inkludieren ist und wie die Lieferanten zu überwachen sind
- A.16 Informationssicherheits-Störfallmanagement – Kontrollen für die Meldung von Vorfällen und Gebrechen, welche die Verantwortlichkeiten, Sofortmaßnahmen und Sammlung von Beweisen definieren
- A.17 Informationssicherheitsaspekte des betrieblichen Kontinuitätsmanagements – Kontrollen, welche die Planung von Betriebskontinuität, Verfahren, Verifizierung und Überprüfung sowie der IT-Redundanz verlangen
- A.18 Compliance/Konformität – Kontrollen, welche die Identifizierung anwendbarer Gesetze und Bestimmungen, des Schutzes geistigen Eigentums, des Schutzes persönlicher Daten und die Überprüfung der Informationssicherheit verlangen
Datensicherheit
Datensicherheit hat das Ziel, die Vertraulichkeit, Integrität und Verfügbarkeit von Daten sicherzustellen. Im Unterschied zum Datenschutz beschränkt sie sich nicht auf personenbezogene Daten, sondern erstreckt sich auf alle Daten. Vertraulichkeit bedeutet, dass nur befugte Personen auf die Daten zugreifen können. Integrität heißt: Die Daten wurden nicht manipuliert oder beschädigt. Die Verfügbarkeit bezieht sich darauf, dass Daten verwendet werden können, wenn man sie benötigt. Um Datensicherheit zu etablieren, sind verschiedene technische und organisatorische Maßnahmen nötig, zum Beispiel Zugriffskontrollen, Kryptografie oder redundante Speichersysteme.
Um Datensicherheit zu etablieren, sind verschiedene technische und organisatorische Maßnahmen nötig, zum Beispiel Zugriffskontrollen, Kryptografie oder redundante Speichersysteme.
Information Security Management System (ISMS)
Ein Informationssicherheits-Management-System, auf Englisch „Information Security Management System (ISMS)“, ist kein technisches System, sondern definiert Regeln und Methoden, um die Informationssicherheit zu gewährleisten, zu überprüfen und kontinuierlich zu verbessern. Das umfasst unter anderem die Ermittlung und Bewertung von Risiken, die Festlegung von Sicherheitszielen sowie eine klare Definition und Dokumentation von Verantwortlichkeiten, Kommunikationswegen und Abläufen.
Cyber-Resilienz
Unter Cyber-Resilienz versteht man die Fähigkeit eines Unternehmens oder einer Organisation, ihre Geschäftsprozesse trotz widriger Cyber-Umstände aufrechtzuerhalten. Das können Cyber-Angriffe sein, aber auch unbeabsichtigte Hindernisse wie ein fehlgeschlagenes Software-Update oder menschliches Versagen. Cyber-Resilienz ist ein umfassendes Konzept, das über die IT-Sicherheit hinausgeht. Es vereint die Bereiche Informationssicherheit, Business-Kontinuität und organisatorische Resilienz. Um einen Zustand der Cyber-Resilienz zu erreichen, ist es wichtig, Schwachstellen frühzeitig zu erkennen, sie wirtschaftlich zu priorisieren und zu beseitigen.
Authentisierung, Authentifizierung und Autorisierung
Die Authentisierung stellt den Nachweis einer Person dar, dass sie tatsächlich diejenige Person ist, die sie vorgibt zu sein. Eine Person legt also Nachweise vor, die ihre Identität bestätigen sollen.
Die Authentifizierung stellt eine Prüfung der behaupteten Authentisierung dar. Bei der Authentifizierung ist nun der Prüfer an der Reihe. Er überprüft die Angaben auf ihre Echtheit. Zeitlich betrachtet findet eine „Authentifizierung“ also nach einer „Authentisierung“ statt.
Die Autorisierung ist die Einräumung von speziellen Rechten. War die Identifizierung einer Person erfolgreich, heißt es noch nicht automatisch, dass diese Person bereitgestellte Dienste und Leistungen nutzen darf. Darüber entscheidet die Autorisierung.
Schutzbedarfsstufen
| normal | hoch | sehr hoch |
|---|---|---|
| Die Schadensauswirkungen sind begrenzt und überschaubar. | Die Schadensauswirkungen können beträchtlich sein. | Die Schadensauswirkungen können ein existenziell bedrohliches, katastrophales Ausmaß erreichen. |
Beispiele für Sicherheitstests / Penetrationstest / Eindringungstest / Juckts im Schritt?
- Überprüfung der vom Kunden zur Verfügung gestellten Daten auf Korrektheit
- Identifizierung von Betriebssystemen und erreichbaren Diensten
- Test der erkannten Dienste mit Schwachstellenscannern
- Überprüfung der Ergebnisse, Verifizierung von erkannten Sicherheitslücken
- Einsatz von Werkzeugen, die Gebiete abdecken, die von Schwachstellenscannern nicht berücksichtigt werden
- Manuelle Prüfungen
- Nachweis von DoS-Potenzialen nach Absprache mit dem Kunden
Backupstrategien
Allgemeines
Bevor man über eine Backupstrategie nachdenkt, sollte grundsätzlich immer zunächst einmal analysiert werden, wie hoch der Schutzbedarf der Daten ist und welche gesichert werden sollten. Sobald dies getan ist, sollten Überlegungen angestellt werden, wie wichtig die Integrität der Daten ist und wie hoch der Kostenfaktor des Backups sein sollte / darf. Danach kann sich für eine bestimmte Art Backup entschieden werden und sich eine für sich passende Strategie überlegt werden.
Backuparten
Es gibt im Wesentlichen drei verschiedene Arten von Backups. Diese unterscheiden sich jeweils in der Zugriffsgeschwindigkeit und dem Speicherbedarf.
| Bezeichnung |
Funktionsweise |
Speicherbedarf |
Geschwindigkeit |
Schutz |
| Full Backup |
Hierbei werden immer alle Daten gesichert, egal ob sie sich verändert haben oder nicht. Da einfach der komplette Datenbestand kopiert wird, handelt es sich hierbei um ein nicht sonderlich komplexes Backup. |
Ist bei dieser Variante sehr hoch. |
Sehr langsam, da immer alle Daten aufs neue kopiert werden. |
Hoher Schutzfaktor vor Datenverlust, da eine hohe Redundanz vorhanden ist. |
| Differenzielles Backup |
Hierbei wird zunächst ein Full Backup zugrunde gelegt. Danach werden dann immer nur die Änderungen gespeichert. Sollte es mehrere solcher Backups geben, sind diese unabhängig voneinander. |
Ist deutlich weniger als bei Full Backups. |
Deutlich schneller als ein Full Backup. |
Nicht ganz so gut wie bei einem Full Backup, da es hier zu Problemen kommen kann, wenn das Initialbackup beschädigt ist. |
| Inkrementelles Backup |
Hierbei handelt es sich um viele kleine Backups, die immer wieder aufeinander aufbauen. Dieser „Kette“ liegt gewöhnlich ein Full Backup zugrunde. |
Sehr gering. |
Sehr schnell, da nur kleine Datenmengen. | Leider ist dieser hier sehr gering, da die Backups aufeinander aufbauen. Sollte eines in der Kette beschädigt sein, sind alle folgenden auch nicht zu gebrauchen. |
Backupsysteme
Es gibt die verschiedensten Arten von Backups, die je nach Schutzbedarf und Kostenfaktor kombiniert werden können / sollten.
Hierbei sind grundsätzlich Langzeit und Kurzzeit Backups voneinander zu unterscheiden.
Bei den Langzeitbackups ist es meist nicht wichtig, dass schnell auf die Daten zugegriffen werden kann. Daher kommen hier meistens Techniken wie z. B. Bänder zum Einsatz. Es gibt allerdings auch Langzeitbackups auf Festplatten.
Sollen Daten jedoch nur kurze Zeit gespeichert werden, werden die Backups vorwiegend auf Festplatten vorgenommen, da hier ein schneller Zugriff auf die Daten möglich ist.
Des Weiteren ist es in Betracht zu ziehen, dass das gesamte Gebäude abbrennen oder anderweitig zerstört werden könnte. Hier kann nur ein sogenanntes Offsitebackup Abhilfe schaffen. Dieses sollte sich idealerweise weit genug entfernt befinden, um bei Naturkatastrophen nicht auch betroffen zu sein. Des Weiteren ist hier meist ein externer Datenzugriff nicht auszuschließen. Daher sollte man sich bei einem Offsitebackup auch davor schützen.
Zusätzlich kann ein Backup nicht nur vor Datenverlust schützen, sondern auch vor Datenänderung. Hierzu sollte ein Speichermedium genutzt werden, das sich nicht mehr oder erst nach einer bestimmten Zeit wieder überschreiben lässt. Dies ist sowohl bei Bändern als auch bei Festplatten (durch Software) möglich. Möchte man noch eine Stufe weiter gehen, so ist es auch möglich Daten, die gesichert werden sollen, vor der Sicherung auf Schadsoftware und unbefugte Änderung zu prüfen.
Backupstrategie
Eine universelle ideale Backupstrategie gibt es nicht. Jede Backupstrategie muss individuell aus den verschiedenen Backuparten und Backupsystemen zusammengestellt werden. Hierbei spielen Faktoren wie Sicherheit, Zeit, Wiederanlaufzeit, Speicherbedarf, Kosten oder auch die Internetgeschwindigkeit eine große Rolle. Des weiteren ist zu beachten, dass Raid kein Backup ist!
Eine Häufig angewendete Strategie ist die sogenannte 3-2-1 Regel.
Hierbei werden von allen wichtigen Daten 3 Kopien angefertigt. Diese sollten auf mindestens 2 unterschiedlichen Speichermedien gemacht werden. Eines der drei Medien wird dann an einen anderen Ort gesendet, um ein Offsite Backup zu realisieren.
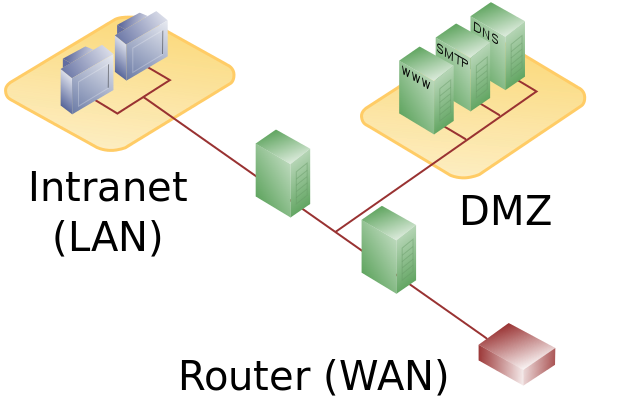
DMZ
Eine demilitarisierte Zone bezeichnet ein Computernetz mit sicherheitstechnisch kontrollierten Zugriffsmöglichkeiten auf die daran angeschlossenen Server.
Die in der DMZ aufgestellten Systeme werden durch eine oder mehrere Firewalls gegen andere Netze (z. B. Internet, LAN) abgeschirmt. Durch diese Trennung kann der Zugriff auf öffentlich erreichbare Dienste gestattet und gleichzeitig das interne Netz (LAN) vor unberechtigten Zugriffen von außen geschützt werden.
Der Sinn besteht darin, auf möglichst sicherer Basis Dienste des Rechnerverbundes sowohl dem WAN (Internet) als auch dem LAN (Intranet) zur Verfügung zu stellen.
Ihre Schutzwirkung entfaltet eine DMZ durch die Isolation eines Systems gegenüber zwei oder mehr Netzen.
- DMZ = Demilitarisierte Zone
- Bezeichnung für ein Computernetzwerk mit kontrollierten Zugriffsmöglichkeiten auf die daran angeschlossenen Server
- Abgrenzung gegenüber anderen Netzen mithilfe von Firewalls
- Ermöglicht den Zugriff auf die gleichen Server sowohl aus dem Internet (WAN) als auch dem Intranet (LAN)
- Verbindungsaufbau sollte immer aus dem internen Netz in die DMZ erfolgen und nicht umgekehrt
|
DMZ mit einstufigem Firewall-Konzept |
DMZ mit zweistufigem Firewall-Konzept |
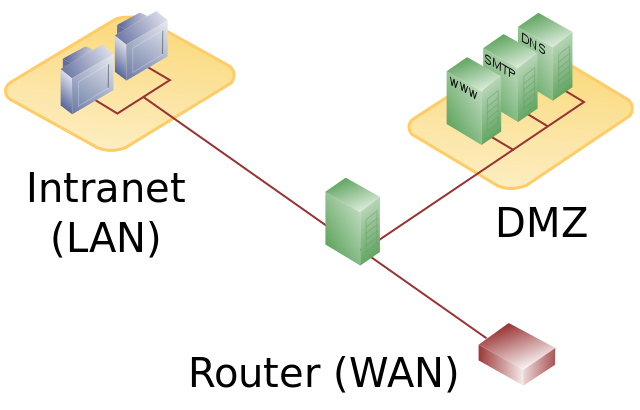 |
 |
Proxy
Proxy bedeutet Stellvertreter. Ein Proxy-Server tritt anstelle eines anderen Systems in Erscheinung. Ein Proxy kann allen Traffic oder nur bestimmten Traffic weiterleiten, z.B. nur HTTP/HTTPS-Traffic (Web-Proxy).
Proxy-Server

Ein normaler Proxy-Server wird Clients vorgeschaltet. Ein Client sendet seinen Traffic an den Proxy-Server, welcher den Traffic seinerseits mit seiner eigenen IP-Adresse weiterleitet. Der Empfänger, z. B. ein Web-Server, erhält die Anfrage und schickt seine Antwort an den Proxy-Server. Dieser ersetzt im Paket seine IP-Adresse durch die des Clients und schickt das Paket an diesen zurück.
Durch einen solchen Proxy-Server wird die IP-Adresse des Clients vor dem Empfänger des Pakets verborgen, was ein Nachverfolgen einer Anfrage erschwert. Proxy-Server können aber auch noch andere Funktionalität bereitstellen, z. B. kann der Web-Proxy Squid als Cache-Server für Webseiten fungieren, was zumindest die Anzahl der Anfragen auf das Internet reduziert und zumindest theoretisch das Netzwerk entlastet. Auch Funktionen zur Kontrolle von Traffic (Access Control, Routing) sind über einen Proxy-Server implementierbar.
Reverse Proxy-Server

Die andere Art eines Proxy-Servers sind sogenannte Reverse Proxy-Server. Reverse Proxy-Server werden Servern vorgeschaltet. Der Client schickt seine Anfrage nicht direkt an das Backend (hier Web-Server), sondern an den Reverse Proxy-Server. Dieser leitet die Anfragen an das Backend weiter, z. B. den Web-Server, und liefert anschließend die Antwort an den Client zurück.
Durch einen Reverse Proxy werden die IP-Adressen des Backends vor dem Client verborgen, was die Sicherheit erhöht. Ein Reverse Proxy kann außerdem Funktionen zur Lastverteilung (dadurch High Availability), DoS Protection etc. implementieren.
Squid kann sowohl als Proxy-Server als auch als Reverse Proxy konfiguriert werden. Wikipedia nutzt Squid als Reverse Proxy mit aktiviertem HTTP/HTTPS-Cache und reduziert so die Anfragen auf die Web-Server, da eine Seite im Cache nicht von den Web-Servern bezogen werden muss.
Es ist auch möglich, Proxy-Server und Reverse Proxy-Server zu verketten. (kaskadierender Proxy)
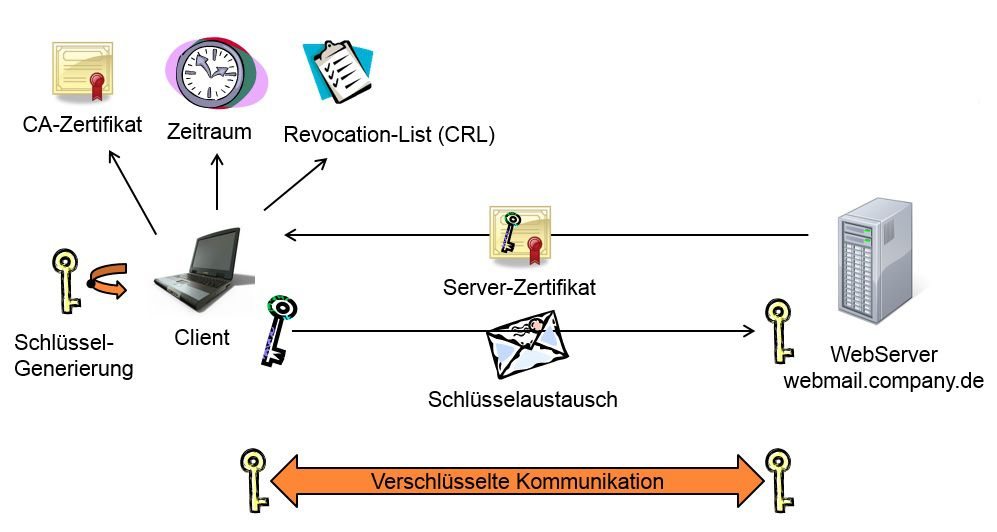
Zertifikate
Einsatzzweck
Zertifikate werden im Allgemeinen verwendet, um die Echtheit von Daten zu beweisen. Daten können hierbei E-Mails, Dokumente, Software / Updates, Webdaten oder gar ganze Verbindungen wie z. B. bei einem VPN sein.
Funktionsweise
Damit Zertifikate funktionieren, sind in der Regel zwei Dinge notwendig. Zum einen wird eine Zertifizierungsstelle (Certification Authority oder auch CA) benötigt. Diese vergibt die Zertifikate und stellt sicher, dass derjenige der das Zertifikat beantragt auch der ist, der zu dem Zertifikat hinterlegt ist. Hierbei gibt es verschiedenste Stufen der Überprüfung, denn nicht jedes Zertifikat ist gleich vertrauenswürdig.
Des Weiteren ist, um die Zertifikate überprüfen zu können, eine sogenannte Public Key Infrastruktur, kurz PKI notwendig. Sie vereinfacht den Austausch von Zertifikaten dahingehend, dass es ein Root Zertifikat gibt, dem vertraut wird. Alle Zertifikate, die mit diesem signiert wurden, können als vertrauenswürdig betrachtet werden, da bei der Signierung der Zertifikate die Ansprüche der Root CA zu erfüllen sind.
Das gesamte System der Zertifikate basiert auf der asymmetrischen Verschlüsselung, wobei das Zertifikat immer nur den Public Key enthält. Der jeweilige Private Key bleibt bei den signierenden Parteien.
Der Ablauf einer mit Zertifikaten signierten Verbindung ist folgender Grafik zu entnehmen.
Symmetrisch / Asymmetrische Leitungen
Upstream
- Datenfluss vom Verbraucher zur Quelle
- zum Upload zur Verfügung stehende Bandbreite
- Anfragen, die von einem Client an einen Server gestellt werden
Downstream
- Datenfluss von der Quelle zum Verbraucher
- zum Download zur Verfügung stehende Bandbreite
- Antwort des Servers auf eine Anfrage des Clients
Asymmetrisch
- Upload und Download sind nicht gleich groß. Zur Verfügung stehende Bandbreite wird in ungleiche Bestandteile aufgeteilt.
- Beispiel: DSL, VDSL
- je nach zu erwartendem Datenverkehr wird Upload oder Download bevorzugt
- Beispiel:
- Haushaltsanschlüsse haben oft einen hohen Download und einen niedrigen Upload
- Streamingdienste brauchen einen deutlich höheren Upload
Symmetrisch
- Upload und Download sind gleich groß
- Bandbreite ist nicht aufgeteilt und in beide Richtungen konstant
- Beispiele: Glasfaseranschlüsse
RAID-Level
Definition
Ein RAID (Redundant Array of Independent Disks) ist ein Verbund zwei oder mehr verschiedenen Speichermedien zu einem einzelnen logischen Laufwerk. Die konkrete Funktion bestimmen die jeweiligen Festplatten-Setups, die man auch als RAID-Level bezeichnet.
Das primäre Ziel von einem RAID ist es, die Sicherheit gespeicherter Daten zu erhöhen. Ausfälle einzelner Festplatten sollen auf diese Weise kompensiert werden und nicht zu Datenverlust führen. Hierfür setzen die einzelnen RAID-Level verschiedene Techniken ein, um Dateien redundant zu speichern. Das klassische Verfahren ist beispielsweise die Spiegelung aller Daten. Alternativ setzen andere RAID-Level auf Paritätsinformationen, die gemeinsam mit den Nutzdaten auf den eingebundenen Datenträgern gespeichert werden und – im Falle eines defekten Speichermediums – die schnelle und einfache Wiederherstellung der Daten ermöglichen.
Ein RAID ist kein Backup-Ersatz: Die räumlich und zeitlich getrennte Speicherung von Dateien, die klassische Backups auszeichnen, ist in RAID-Verbunden nicht gegeben!
RAID: 0, 1,5, 6, 01, & 10 von Sunny Classroom
Spiegelung aller Daten
Alle Schreibzugriffe erfolgen parallel auf zwei Laufwerke, sodass jede Platte quasi ein Spiegelbild der anderen darstellt. Alle Daten stehen also doppelt zur Verfügung. Auch wenn eines der beiden Laufwerke komplett ausfällt, bleiben alle Nutzdaten erhalten. Allerdings steht bei RAID 1 nur die Hälfte der gesamten Plattenkapazität für die Speicherung zur Verfügung. Die Kosten der Datenhaltung verdoppeln sich also.
Paritätsinformationen
Ein Paritätsbit ist ein Prüfbit, das zur Fehlererkennung in der Paritätsprüfung eingesetzt wird. Dies wird sendeseitig zu den Datenbits hinzugefügt, wodurch die Bitsumme gerade oder ungerade wird. Empfangsseitig wird die Bitsumme überprüft. Entspricht die empfangene Bitsumme nicht der vorgegebenen Parität, - die beispielsweise gerade sein muss - dann liegt ein Übertragungsfehler vor. Eine gerade Parität ist dann gegeben, wenn durch das hinzugefügte Bit die Gesamtzahl der Einsen in einer Dateneinheit geradzahlig wird.
Ein RAID-Verbund nutzt erweiterte Versionen von Paritätschecks. Manche RAID-Level, etwa RAID 4 oder RAID 5, legen die Paritätsinformationen auf einem oder mehreren Laufwerken ab und können so das RAID wiederherstellen, wenn ein Laufwerk ausfällt. Wenn Daten auf ein RAID geschrieben werden, haben diese immer die korrekte Parität, da sie zuvor diverse Fehlerkorrekturchecks durchlaufen. Fällt ein Laufwerk in einem RAID-Verbund aus, kann das System die verlorenen Daten aus den auf den verbliebenen Laufwerken gespeicherten Informationen und den Paritätsinformationen rekonstruieren und auf ein Spare-Laufwerk schreiben.
Beispiel eine RAID 4/5/6 Parität
Paritätsinformationen in Fett und Rot (0111)
- Berechnen der Paritätsinformationen mittels eines XOR aus den Eingangsdaten von HDD 1 und HDD 2
- Ausfall der HDD 2
- Wiederherstellung der Informationen von HDD 2 aus Daten von HDD 1 und HDD 3 mittels XOR
| Schritt | HDD 1 | HDD 2 | HDD 3 |
| 1 | 1010 | 1101 | 0111 |
| 2 | 1010 | XXXX | 0111 |
| 3 | 1010 | 1101 | 0111 |
RAID-Level
| RAID 0 | RAID 1 | RAID 5 | RAID 6 | RAID 10 (1+0) | |
| Mindestanzahl an Festplatten | 2 | 2 | 3 | 4 | 4 |
| Verwendete Verfahren | Striping | Spiegelung (Mirroring) | Striping und Parität | Striping und doppelte Parität auf unterschiedlichenPlatten | Striping gespiegelter Daten |
| Ausfallsicherheit | niedrig | sehr hoch; Ausfall eines Laufwerks möglich | mittel; Ausfall eines Laufwerks möglich | hoch; Ausfall von zwei Laufwerken möglich | sehr hoch; Ausfall eines Laufwerks pro Sub-Array möglich |
| Speicherkapazität | 100 % | 50 % | 67 % (steigt mit jeder weiteren Platte) | 50 % (steigt mit jeder weiteren Platte) | 50 % |
| Geschwindigkeit beim Schreiben | sehr hoch | niedrig | mittel | niedrig | mittel |
| Geschwindigkeit beim Lesen | sehr hoch | mittel | hoch | hoch | sehr hoch |
| Kostenfaktor | niedrig | sehr hoch | mittel | hoch | sehr hoch |
IPv6
Was ist IPv6 und warum brauchen wir es?
IPv6 (Internet Protocol Version 6) ist ein auf Layer 3 stattfindendes Protokoll für die Übertragung und Vermittlung von Datenpaketen in einem paketorientiert arbeitenden Netzwerk wie dem Internet. Es soll das bisher verwendete IP-Protokoll Version 4 (IPv4) ablösen.
Das Internetprotokoll der Version 4 ist in vielen Bereichen veraltet und kann die Anforderungen moderner Netzwerke und netzwerkfähiger Applikationen nicht mehr im gewünschten Maß erfüllen. Es vereinfacht die Einrichtung und den Betrieb und ist direkt nach dem Start eines netzwerktauglichen Gerätes verfügbar. Zustands behaftete Verfahren zur Adressvergabe wie DHCP, die bei IP der Version 4 zum Einsatz kommen, werden überflüssig.
Im Vergleich zu den IP-Adressen der Version 4 mit 32 Bit Länge sind IPv6-Adressen 128 Bit lang. Sie bieten damit einen wesentlich größeren Adressraum und eine Lösung für die Adressknappheit von IPv4-Adressen im Internet.
Beispiel einer IPv6 Adresse
2001:0000:0000:0000:0080:ACDE:02CE:1234
- Acht Gruppen mit je 16 Bit, separiert mit Doppelpunkten
- Jede Gruppe hat vier Hexadezimalzeichen zu je 4 Bit
Jede in einer Gruppe vorausführende Null kann weggelassen werden
Somit würde die IPv6 Adresse wie folgt aussehen:
2001:0:0:0:80:ACDE:2CE:1234
Gruppen aus Nullen können wiederum durch zwei Doppelpunkte dargestellt werden. Dies darf aber nur ein mal angewendet werden. Es können also keine doppelten Paare aus Doppelpunkten verwendet werden!
Schlussendlich sieht unsere IPv6 Adresse dann wie folgt aus:
2001::80:ACDE:2CE:1234
Unterteilung der Gruppen
2001:0000:0000:0000:0080:ACDE:02CE:1234
| 2001:0000:0000:0000 | Network Prefix (Präfix oder Netz-ID) – Wobei dieses Modell weiter unterteilt werden kann. So können die letzten 8 Bits der Network Prefix die Subnet Prefix angeben. |
| 0080:ACDE:02CE:1234 | Interface Identifier (Suffix, IID oder EUI) |
Segmentierung: Präfix und Präfixlänge
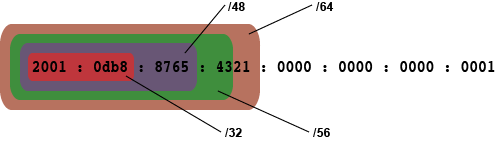
Die von IPv4 bekannte Netzmaske bzw. Subnetzmaske fällt bei IPv6 ersatzlos weg. Um trotzdem eine Segmentierung und Aufteilung von Adressbereichen bzw. Subnetzen vornehmen zu können, wird die Präfixlänge definiert und mit einem / an die eigentliche IPv6-Adresse angehängt. Der hierarchische Aufbau des Präfixes soll das Routing mit IPv6 vereinfachen.
Standardmäßig ist /64 die Präfixlänge. Es gibt jedoch weitere typische Präfixe, die 32, 48 und 56 Bit lang sind.
IPv6-Address-Scopes (Gültigkeitsbereiche)
| Unicast | Link-Local-Adressen (Verbindungslokale Unicast-Adressen) sind nur innerhalb von geschlossenen Netzsegmenten gültig. Router dürfen Datenpakete mit Link-Local Adressen als Quelle oder Ziel nicht an andere Links weiterleiten. Präfix: fe80::/10 |
| Multicast-Adressen | Eine Multicast-Adresse ist ein Identifier für eine Gruppe von Geräten. Jedes Gerät kann zu beliebig vielen Multicast-Gruppen gehören. Präfix: ff00::/8 |
| Anycast-Adressen | Im IPv6 wurde ein neuer Adresstyp "Anycast" definiert. Dieser Adresstyp erlaubt es, dass Datenpakete zu einem oder mehreren Geräten mit gleicher Adresse geroutet werden. Anycast-Adressen können einem oder mehreren, typischerweise an unterschiedlichen Geräten befindlichen, Netzwerk-Interfaces zugewiesen werden. Die Routing-Protokolle liefern jedes Paket zum nächsten Interface. |
SLAAC und DAD
Stateless Address Autoconfiguration (SLAAC) ist ein Verfahren zur zustandslosen und automatischen Konfiguration von IPv6-Adressen an einem Netzwerk-Interface. Mit „stateless“ bzw. „zustandslos“ ist gemeint, dass die jeweilige IPv6-Adresse nicht zentral vergeben und gespeichert wird. Demnach erzeugt sich der Host seine IPv6-Adresse unter Zuhilfenahme zusätzlicher Informationen selbst.
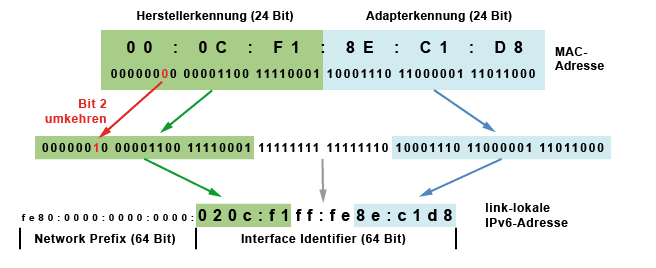
Eine link-lokale IPv6-Adresse wird aus einem Präfix (64 Bit) und einem Suffix (64 Bit) gebildet. Der Präfix für alle link-lokalen IPv6-Adressen ist immer "fe80:0000:0000:0000". Das Suffix (Interface Identifier) ist der EUI-64-Identifier oder IEEE-Identifier, der aus der MAC-Adresse (Hardware-Adresse des Netzwerkadapters) gebildet wird.
In der Mitte der 48-Bit-MAC-Adresse (zwischen dem dritten und dem vierten Byte) werden mit "ff:fe" zwei feste Bytes eingefügt, damit es 64 Bit werden. Zusätzlich wird noch das zweite Bit im ersten Byte der MAC-Adresse invertiert. Das heißt, aus "1" wird "0" und aus "0" wird "1".
Auf diese Weise wird zum Beispiel die MAC-Adresse "00:0C:F1:8E:C1:D8" zum Interface Identifier "020c:f1ff:fe8e:c1d8". Und der Host bildet sich so die link-lokale Adresse "fe80:0000:0000:0000:020c:f1ff:fe8e:c1d8".
Um Adresskollisionen zu vermeiden sollte der Host bei einer neu generierten IPv6-Adresse eine Duplicate Address Detection (DAD) durchführen.
- Neighbor Solicitation: Dazu schickt der Host eine Anfrage an die generierte Adresse ins lokale Netz. Als Antwort-Adresse dient eine Multicast-Adresse.
- Neighbor Advertisement: Falls eine andere Station die IPv6-Adresse bereits nutzt, kommt eine Antwort zurück.
Erst wenn keine Antwort von dieser Adresse zurückkommt, bindet sich das Interface an diese Adresse und kann sie für die Kommunikation nutzen.
Weil es keine Pflicht gibt eine DAD durchzuführen, sind Adresskollisionen durchaus möglich. Aufgrund des sehr großzügigen Adressraums und der weltweit eindeutigen MAC-Adressen aber eher unwahrscheinlich.
Sollte es doch einmal zu einer Kollision kommen und die IPv6-Adresse tatsächlich schon existieren, dann muss die IPv6-Adresse vom Anwender manuell geändert werden.
Dann sollte man gleich das ganze Netzwerk überprüfen. Es könnte dann sein, dass jemand eine MAC-Adresse gekapert hat und per MAC-Spoofing ins Netzwerk eingedrungen ist.
Strukturierte Verkabelung
Eine strukturierte Verkabelung oder universelle Gebäudeverkabelung (UGV) ist ein einheitlicher Aufbauplan für eine zukunftsorientierte und anwendungsunabhängige Netzwerkinfrastruktur, auf der unterschiedliche Dienste (Sprache oder Daten) übertragen werden. Damit sollen teure Fehlinstallationen und Erweiterungen vermieden und die Installation neuer Netzwerkkomponenten erleichtert werden.
Bestandteile einer strukturierten Verkabelung
- standardisierte Komponenten, wie Leitungen und Steckverbindungen
- hierarchische Netzwerk-Topologie (Stern, Baum, …)
- Empfehlungen für Verlegung und Installation
- standardisierte Mess-, Prüf- und Dokumentationsverfahren
Ziele einer strukturierten Verkabelung
- Unterstützung aller aktuellen und zukünftigen Kommunikationssysteme, strukturierte anwendungsneutrale Verkabelung
- Kapazitätsreserve hinsichtlich der Grenzfrequenz
- das Netz muss sich gegenüber dem Übertragungsprotokoll und den Endgeräten neutral verhalten. Es ist egal, wie wir das Gerät verbinden, das Netzwerk sollte am Ende einfach funktionieren
- flexible Erweiterbarkeit
- Ausfallsicherheit durch vermaschte und/oder eine baumstrukturierte Verkabelung
- Datenschutz und Datensicherheit müssen realisierbar sein
- Einhaltung existierender Standards
Primärverkabelung - Geländeverkabelung
Der Primärbereich wird als Campusverkabelung oder Geländeverkabelung bezeichnet. Er sieht die Verkabelung von einzelnen Gebäuden untereinander vor. Der Primärbereich umfasst meist große Entfernungen, hohe Datenübertragungsraten, sowie eine geringe Anzahl von Stationen.
Sekundärverkabelung - Gebäudeverkabelung
Der Sekundärbereich wird als Gebäudeverkabelung oder Steigbereichsverkabelung bezeichnet. Er sieht die Verkabelung von einzelnen Etagen und Stockwerken untereinander innerhalb eines Gebäudes vor.
Tertiärverkabelung - Etagenverkabelung
Der Tertiärbereich wird als Etagenverkabelung bezeichnet. Er sieht die Verkabelung von Etagen- oder Stockwerksverteilern zu den Anschlussdosen vor. Während sich im Stockwerksverteiler ein Netzwerkschrank mit Patchfeld befindet, mündet das Kabel am Arbeitsplatz des Anwenders in einer Anschlussdose in der Wand, in einem Kabelkanal oder in einem Bodentank mit Auslass.
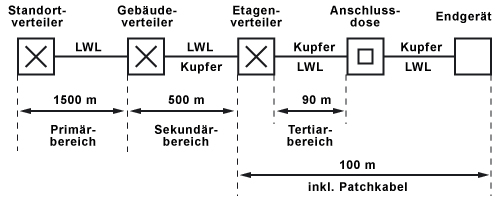
NAT/PAT
NAT = Network Address Translation
PAT = Port Address Translation
Der IPv4-Adressraum ist auf rund 4,3 Milliarden Adressen begrenzt (2^32). Es wurde relativ schnell klar, dass diese 4,3 Milliarden IP-Adressen nicht ausreichen würden. Um dieses Problem zu adressieren, wurden Teile des IPv4-Raums als privat deklariert.
| Netzadressebereich |
CIDR - Notation |
Anzahl Adressen |
| 10.0.0.0 bis 10.255.255.255 |
10.0.0.0/8 |
2^24 = 16.777.216 |
| 172.16.0.0 bis 172.31.255.255 |
172.16.0.0/12 |
2^20 = 1.048.576 |
| 192.168.0.0 bis 192.168.255.255 |
192.168.0.0/16 |
2^16 = 65.536 |
Diese IP-Adressen werden im Internet nicht geroutet und können daher nicht verwendet werden. Stattdessen werden diese Adressen für die lokalen Netzwerke beim Endkunden verwendet. Der Endkunde erhält von seinem Provider eine (teilweise auch mehrere) öffentliche IP-Adressen. Gleichzeitig spannt der Router des Endkunden intern ein neues Netzwerk innerhalb des privaten IPv4-Adressraums auf, aus welchem er den Clients IP-Adressen vergibt.
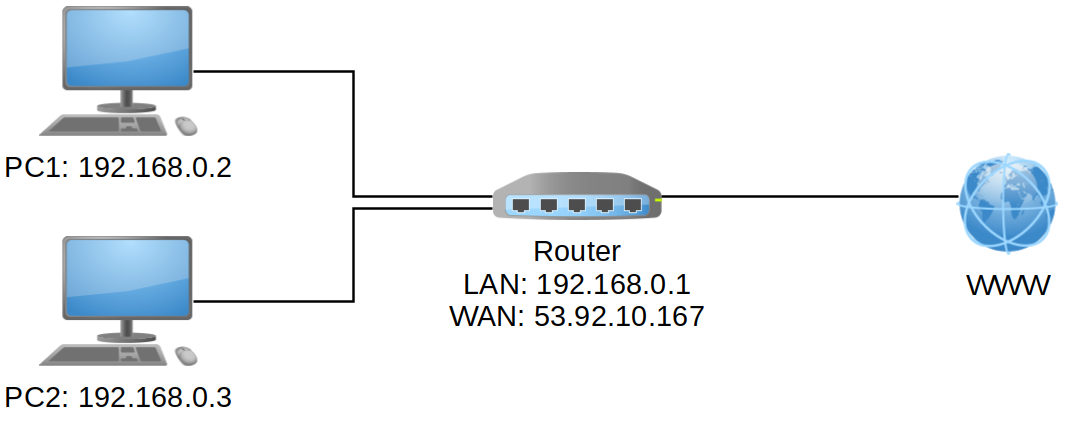
Im Gegensatz zum Routing wird bei NAT/PAT tatsächlich die IP-Adresse ausgetauscht
Um die Kommunikation zwischen den privaten und öffentlichen IP-Adressbereichen zu ermöglichen wurden mehrere Verfahren entwickelt:
Source NAT/PAT
- Beim Verbindungsaufbau durch einen internen Client wird die interne Quell-IP-Adresse durch die öffentliche IP-Adresse ersetzt
- Zusätzlich wird der Quellport des Clients durch eine freien Port des Routers ersetzt
- Die Zuordnung merkt sich der Router in einer Tabelle (NAT-Table)
- Beispiel:
Quelle Ziel Quelle Ziel 192.168.0.2:49701 170.0.0.1:80
Router 205.0.0.2:49701 170.0.0.1:80
192.168.0.3:50387 170.0.0.1:80
===========>
205.0.0.2:50387 170.0.0.1:80
lokales Netz NAT
öffentliches Netz
Destination NAT/PAT
- Bei jedem Verbindungsaufbau durch den Client wird die Ziel-IP-Adresse durch die des eigentlichen Empfängers in LAN ersetzt
- Router hat also ins WAN eine IP-Adresse und je nach Anfrage wird passende interne IP-Adresse eingesetzt
- Beispiel:
Quelle Ziel Quelle Ziel 170.0.0.1:1001
171.4.2.1:80
Router 170.0.0.1:1001 192.168.0.2:80
170.0.0.1:1001
171.4.2.1:22
===========>
170.0.0.1:1001 192.168.0.3:22
öffentliches Netz
NAT
lokales Netz
Firewall
Bei einer Firewall handelt es sich um ein System, das in der Lage ist, Datenverkehr zu analysieren. Sie schützt IT-Systeme vor Angriffen oder unbefugten Zugriffen. Die Firewall kann als dedizierte Hardware oder als Softwarekomponente ausgeführt sein.
Jede Firewall besteht aus einer Softwarekomponente, die Netzwerkpakete lesen und auswerten kann. Innerhalb dieser Software lassen sich die Regeln, welche Datenpakete durchgelassen werden und welche zu blockieren sind, definieren.
Häufig sind Firewalls an Netzwerkgrenzen zwischen einem internen und einem externen Netzwerk platziert. An dieser zentralen Stelle kontrollieren Sie den ein- und ausgehenden Datenverkehr.
Wichtigsten Funktionskomponenten
Um die Schutzfunktion zu erfüllen, besitzen klassische Firewalls verschiedene Funktionskomponenten. Die Anzahl und der Featureumfang der einzelnen Komponenten kann sich je nach Leistungsfähigkeit von Firewall- zu Firewalllösung unterscheiden. Wesentliche in Firewalls implementierte Funktionen sind häufig diese:
| Paketfilter | Kann IP-Pakete anhand von Merkmalen wie IP-Absenderadressen, IP-Zieladressen und Ports filtern. |
| Network Address Translation | Setzt dynamisch eine öffentliche IP-Adresse auf mehrere private IP-Adressen um. Jede ausgehende Verbindung wird mit IP-Adresse und Portnummer festgehalten. Anhand der Portnummer kann NAT eingehende Datenpakete einer lokalen Station zuordnen. |
| URL-Filter | Hiermit wird eingeschränkt, auf welche Webinhalte Benutzer zugreifen können. Dazu wird das Laden bestimmter URLs blockiert. |
| Content-Filter | Bezeichnet die Nutzung eines Programms zum Screenen und/oder Unterbinden von Zugriff auf als unzulässig betrachtete Webinhalten oder E-Mails. |
| Proxyserver | Ist ein Vermittler in einem Netzwerk, der Anfragen entgegennimmt und sie stellvertretend weiterleitet. Mithilfe des Proxyservers lässt sich die Kommunikation zwischen einem lokalen Client und einem Webserver absichern, verschleiern oder beschleunigen. |
| Virtual Private Networks (VPN) | Eine VPN-Verbindung bietet die Möglichkeit, von außen auf ein bestehendes Netzwerk zuzugreifen. |
| Stateful Packet Inspection | Ist eine dynamische Paketfiltertechnik für Firewalls, die im Gegensatz zu statischen Filtertechniken den Zustand einer Datenverbindung in die Überprüfung der Pakete einbezieht und entscheidet, ob ein Datenpaket zugelassen oder blockiert wird. |
| Stateless Packet Filtering | Stateless Firewalls sind für den Schutz von Netzwerken auf der Grundlage statischer Informationen wie Quelle und Ziel konzipiert. Während Stateful Firewalls Pakete auf der Grundlage des gesamten Kontexts einer bestimmten Netzwerkverbindung filtern, filtern Stateless Firewalls Pakete auf der Grundlage der einzelnen Pakete selbst. |
| Deep Packet Inspection | In einem Netzwerk übertragene Datenpakete lassen sich bis auf Anwendungsebene des ISO/OSI-Schichtenmodells inspizieren und filtern. Im Gegensatz zur Stateful Packet Inspection (SPI) werden nicht nur die Daten-Header, sondern auch die Nutzlast eines Datenpakets analysiert. |
| Routing | Routing sorgt dafür, dass Datenpakete über Netzgrenzen hinweg einen Weg zu anderen Hosts finden. Es kann die Daten über jede Art von physikalischer Verbindung oder Übertragungssystem vermitteln. |
Verschlüsselung
Grundsätzlich
- Die von einem Schlüssel abhängige Umwandlung von Klartext in Geheimtext, so das der Klartext aus dem Geheimtext nur mit Hilfe des Schlüssels wieder gewonnen werden kann

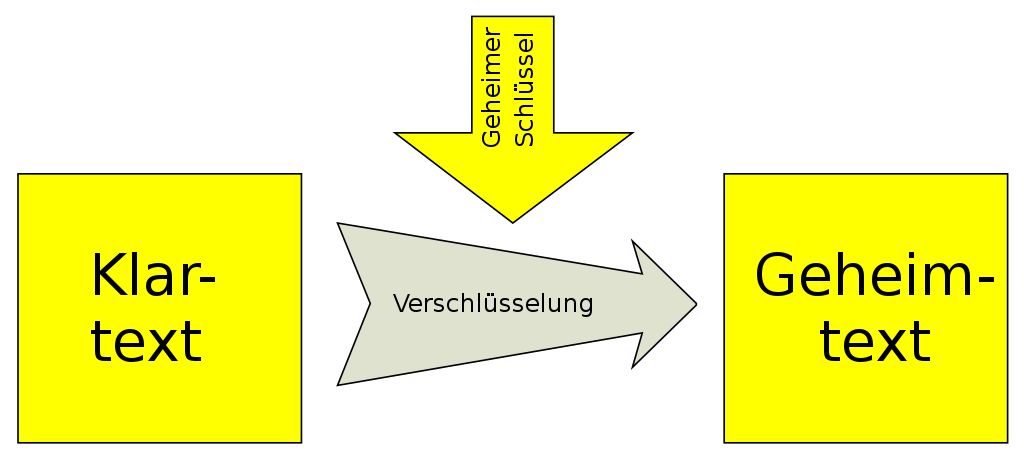
symmetrische Verschlüsselung
- beide Teilnehmer verwenden den gleichen Schlüssel
- Vorteil: Verschlüsselung und Entschlüsselung sehr schnell
- Nachteil: Der Schlüssel muss über einen gesicherten Kanal ausgetauscht werden
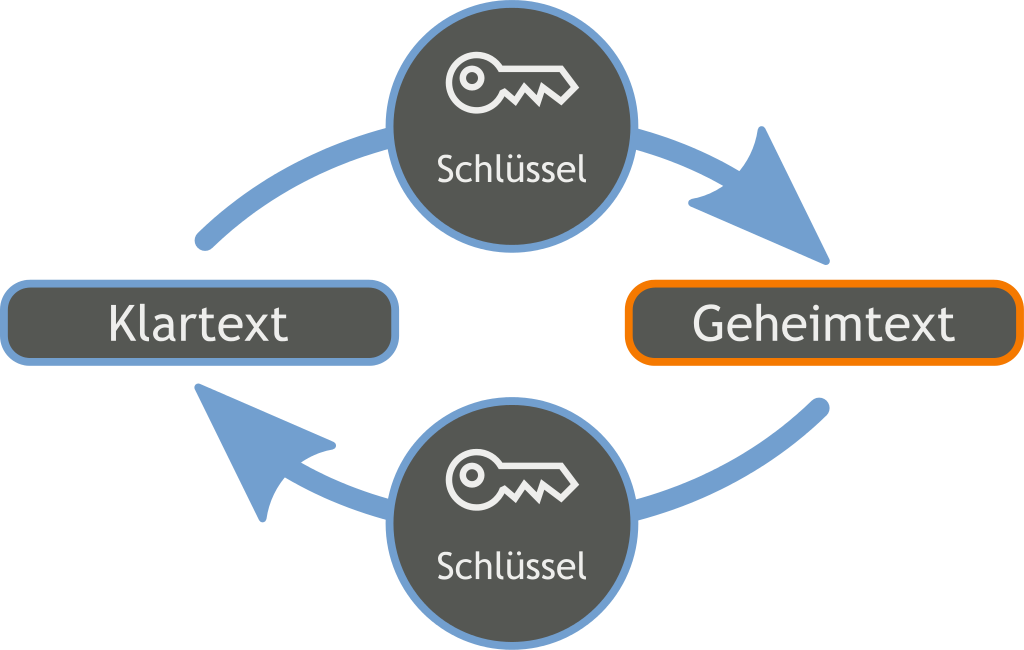
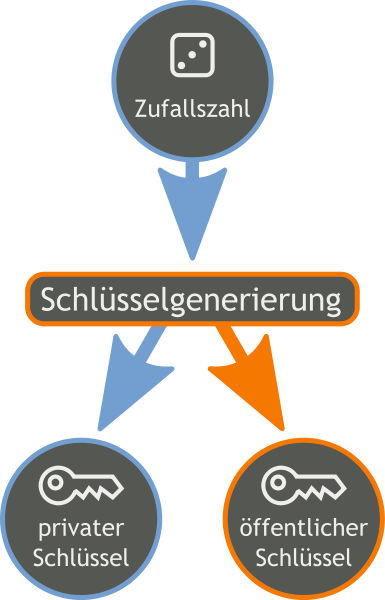
asymmetrische Verschlüsselung
- Aufteilung in einen privaten und einen öffentlichen Schlüssel
- Der private Schlüssel wird mit niemanden geteilt und von niemandem eingesehen
- Der öffentliche Schlüssel kann frei zugängig gemacht werden
- Nachrichten werden mit Hilfe des öffentlichen Schlüssels des Gegenüber verschlüsselt und können nur mit Hilfe des privaten Schlüssels entschlüsselt werden
- Vorteil: Der Datenaustausch ist sehr sicher
- Nachteil: Schlüssel-Infrastruktur notwendig und Kommunikations nicht mehr so schnell
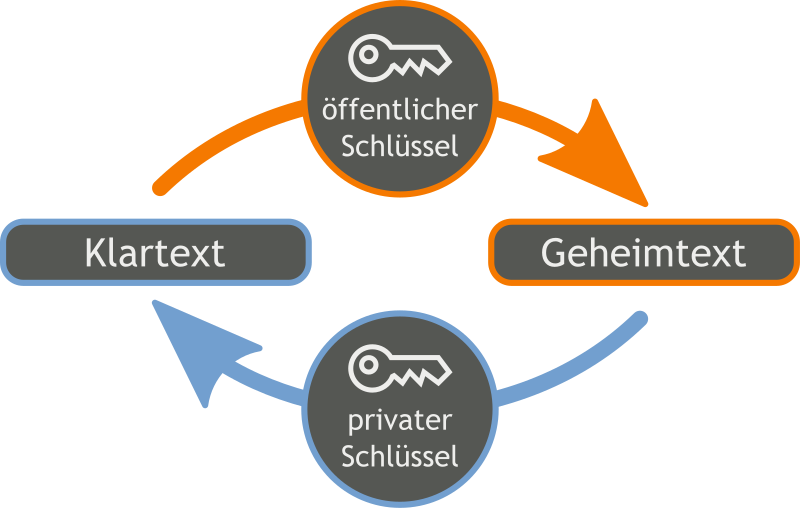
- Lösung: Kombination beider Verfahren
- Nach dem Verbindungsaufbau wird mit Hilfe von privaten und öffentlichen Schlüsseln ein gemeinsamer Schlüssel ausgehandelt. Damit ist die Kommunikation zu Beginn kurz langsamer, man kann sich aber sicher sein, dass der gemeinsame Schlüssel geheim ist.
- Aufbau: handelt mit Hilfe des asymmetrischen Schlüssels einen symmetrischen Schlüssel aus
- Austausch: Daten werden mit Hilfe des symmetrischen Schlüssels ausgetauscht
- Abbau: Verbindung wird beendetk
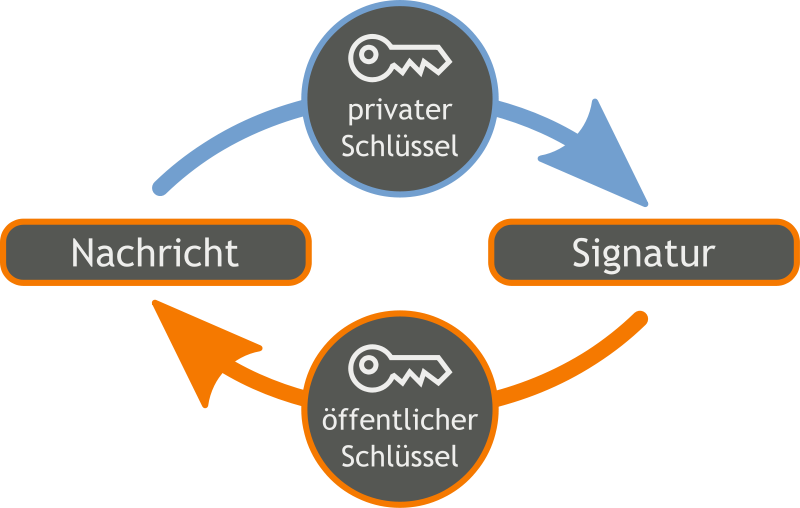
Signatur
- Authentizität: Stammen die Informationen wirklich vom Absender
- Integrität: Sind die Informationen nicht verändert worden
- Lösung:
- erstellen einer Prüfsumme
- Signieren der Prüfsumme mit Hilfe des privaten Schlüssels
- Kontrolle der Authentizität durch Entschlüsseln der Signatur mit Hilfe des öffentlichen Schlüssels
- Kontrolle der Integriät durch eigene Berechnung der Prüfsumme und Vergleich mit gesendeter, signierter Prüfsumme
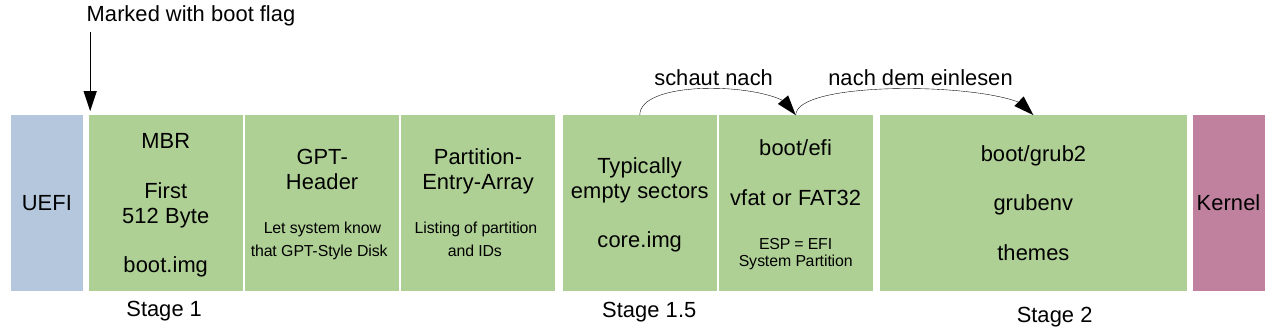
Bootloader & Partitionstabellen
Bootloader
Bootloader sorgen dafür, dass alle relevanten Daten des Betriebssystems bereits mit Gerätestart in den Arbeitsspeicher geladen werden. Während des Boot-Prozesses übermittelt die Firmware die hierfür erforderlichen Informationen.
Ein Bootloader oder auch Bootmanager verwaltet in erster Linie die Boot-Sequenz eines Computers und führt diese aus. Dieser wird in der Regel gestartet, nachdem der Computer oder das BIOS die anfänglichen Strom- und Hardwareprüfungen sowie Tests abgeschlossen hat. Er holt den Betriebssystem-Kernel von der Festplatte oder einem bestimmten Boot-Gerät innerhalb der Boot-Sequenz (Reihenfolge der zu startenden Systeme) in den Hauptspeicher.
Windows als Beispiel nutzt den Bootloader Bootmgr. Mit diesem lassen sich mehrere parallel installierte Windows-Betriebssysteme oder auch zusätzliche Linux-Systeme starten. Ein Beispiel für ein Linux-Bootloader wäre GRUB (Grand Unified Bootloader). Dieser kann ebenfalls eine Vielzahl an Betriebssystemen flexibler starten und wird auch unter anderen Unix-artigen Betriebssystemen eingesetzt.
Wo sich der Bootloader auf dem veränderlichen Datenspeicher zu befinden hat und wie er geladen wird, ist je nach Rechnerarchitektur und Plattform unterschiedlich. Auf moderneren Architekturen liegt er meist als Datei auf einem von der Firmware unterstützten Dateisystem auf einer bestimmten Partition und wird direkt geladen und ausgeführt. Das ist beispielsweise bei Open Firmware und bei UEFI der Fall, wobei die verwendeten Partitionstabellen und Dateisysteme unterschiedlich sein können.
Partitionstabellen
Als Partitionstabelle, auch Partitionsschema, bezeichnet man genormte Datenstrukturen, welche Informationen über die Aufteilung eines Datenspeichers in separate Bereiche beinhalten. Diese Bereiche werden als Partitionen bezeichnet und sind mehrere voneinander unabhängig benutzbare Teile auf normalerweise einem Speichermedium.
Wenn die Partitionstabelle der Festplatte verloren geht, können Benutzer die Daten auf der Festplatte nicht lesen und keine neuen Daten darauf schreiben.
MBR-Partitionstabelle
Der Master Boot Record (kurz MBR) enthält ein Startprogramm für BIOS-basierte Computer und eine Partitionstabelle. Er befindet sich im ersten Sektor eines in Partitionen aufteilbaren Speichermediums, wie beispielsweise einer Festplatte.
Das Startprogramm befindet sich auf den ersten 446 Bytes des MBR. Die nicht sehr umfangreiche Software wird beim Hochfahren des PCs aktiv und initiiert auf operativer Ebene den Bootvorgang. Eine umfangreichere Routine mit standardisierten Verarbeitungsschritten wird in Gang gesetzt, die mit einem einsatzbereiten Betriebssystem (z. B. Windows) endet.
Über die Datenträger- oder Disk-Signatur identifizieren Windows-Rechner (ab Windows 2000) einen Datenträger mit Partitionstabelle.
Die Partitionstabelle dokumentiert die Aufteilung eines Datenspeichers in separate Speichersektionen. Dafür verwendet sie vier Einträge à 16 Byte, die Auskunft über die Lage und die Größe jeder Partition geben. So wird angegeben, wo eine C:\-Partition oder eine D:\-Partition anfängt und endet. Die Tabelle enthält zudem Informationen über den Typ des Datenträgers.
Die MBR- oder Boot-Signatur enthält in zwei Bytes die Zeichenfolgen „55“ und „AA“. Durch die charakteristische Kodierung, die immer am Ende des MBR-Sektors zu finden ist, wird ein Master Boot Record als solcher eindeutig erkannt. Fehlt diese Information, wird der Master Boot Sektor nicht identifiziert und der Bootvorgang wird mit einer Fehlermeldung abgebrochen.
GPT-Partitionstabelle
GUID Partition Table (GPT), zu Deutsch GUID-Partitionstabelle, ist ein Standard zur Formatierung von Partitionstabellen für Speichermedien, insbesondere für Festplatten. GPT ist Bestandteil von UEFI (Unified Extensible Firmware Interface), einer Schnittstellen-Spezifikation, die den Austausch zwischen Firmware und Betriebssystemen während des Bootvorgangs regelt und im Jahr 2000 als BIOS-Nachfolger entwickelt und veröffentlicht worden ist.
Der Aufbau eines Datenträgers mit GUID-Partition-Table-Schema bestehen im Wesentlichen aus diesen vier Teilen:
- Protective Master Boot Record: An erster Stelle steht der bereits erwähnte Protective-MBR, der für die Abwärtskompatibilität des Partitionierungsstils sorgt
- Primäre GUID-Partitionstabelle: GPT-Header und Partitionseinträge
- Partitionen: Auf den Header und die Partitionseinträge folgen die jeweiligen Einheiten des aufgeteilten Speicherplatzes, also die verschiedenen Partitionen
- Sekundäre GUID-Partitionstabelle: Backup von GPT-Header und Partitionseinträgen in gespiegelter Reihenfolge
MBR oder GPT
Das MBR-Format wird seit Anfang der 80er Jahre verwendet und wird weitgehend unterstützt, ist aber auf maximal vier primäre Partitionen mit bis zu 2 Terabyte (TB) beschränkt.
Das GPT-Format ist eine neuere Technologie, die es erlaubt, deutlich größere Festplatten zu verwenden: bis zu einer theoretischen Grenze von 9,4 Zettabyte (ZB) oder fast 10 Milliarden Terabyte. Es wird geschätzt (Stand 2013), dass das gesamte World Wide Web etwa 4 ZB einnimmt. Windows begrenzt GPT-Partitionen derzeit auf 256 TB.
Mit GPT können bis zu 128 Partitionen erstellt werden. Ein weiterer Vorteil von GPT gegenüber MBR ist, dass zwei Kopien des GPT-Headers gespeichert werden, eine am Anfang der Festplatte und eine am Ende. Damit sind die Daten besser vor Beschädigung geschützt als beim MBR-Format, das nur eine einzige Partitionstabelle speichert.
Bootvorgang unter Linux
Grub bzw. Grub Legacy
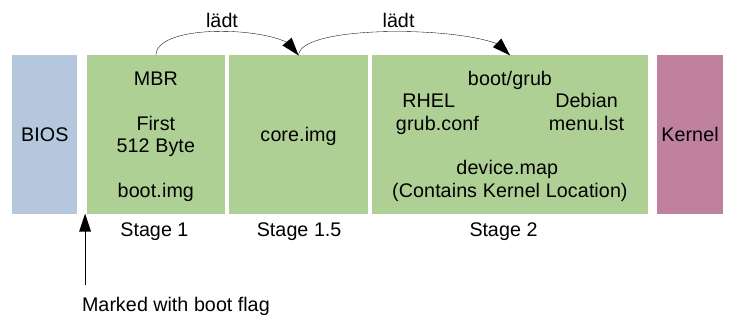
Grub2
Gängige Ports im Internet
| Port |
TCP |
UDP |
Beschreibung |
| 22 | x |
x |
SSH - Secure Shell |
| 25 |
x |
SMTP - Simple Mail Transfer Protocol |
|
| 53 |
x |
x |
DNS - Domain Name System |
| 67 |
x |
DHCP - Dynamic Host Configuration Protocol - Server |
|
| 68 |
x |
DHCP - Dynamic Host Configuration Protocol - Client |
|
| 80 |
x |
HTTP - Hypertext Transfer Protocol |
|
| 110 |
x |
POP3 - Post Office Protocol v3 |
|
| 123 |
x |
x |
NTP - Network Time Protocol |
| 443 |
x |
HTTPS - Hypertext Transfer Protocol over TLS |
|
| 993 |
x |
IMAPS - Internet Message Accesss Protocol over TLS |
Logische Operatoren
Wahrheitstabelle
| A |
B |
A AND B |
A NAND B |
A OR B |
A NOR B |
A XOR B |
A XNOR B |
NOT A |
||||
| 0 |
0 |
0 |
1 |
0 |
1 |
0 |
1 |
1 |
||||
| 1 |
0 |
0 |
1 |
1 |
0 |
1 |
0 |
0 |
||||
| 0 |
1 |
0 |
1 |
1 |
0 |
1 |
0 |
1 |
||||
| 1 |
1 |
1 |
0 |
1 |
0 |
0 |
1 |
0 |
Mathematische und Technische Symbolik
| Operator |
Formel |
Schaltsymbolik |
Relaislogik |
| AND |
|
 |
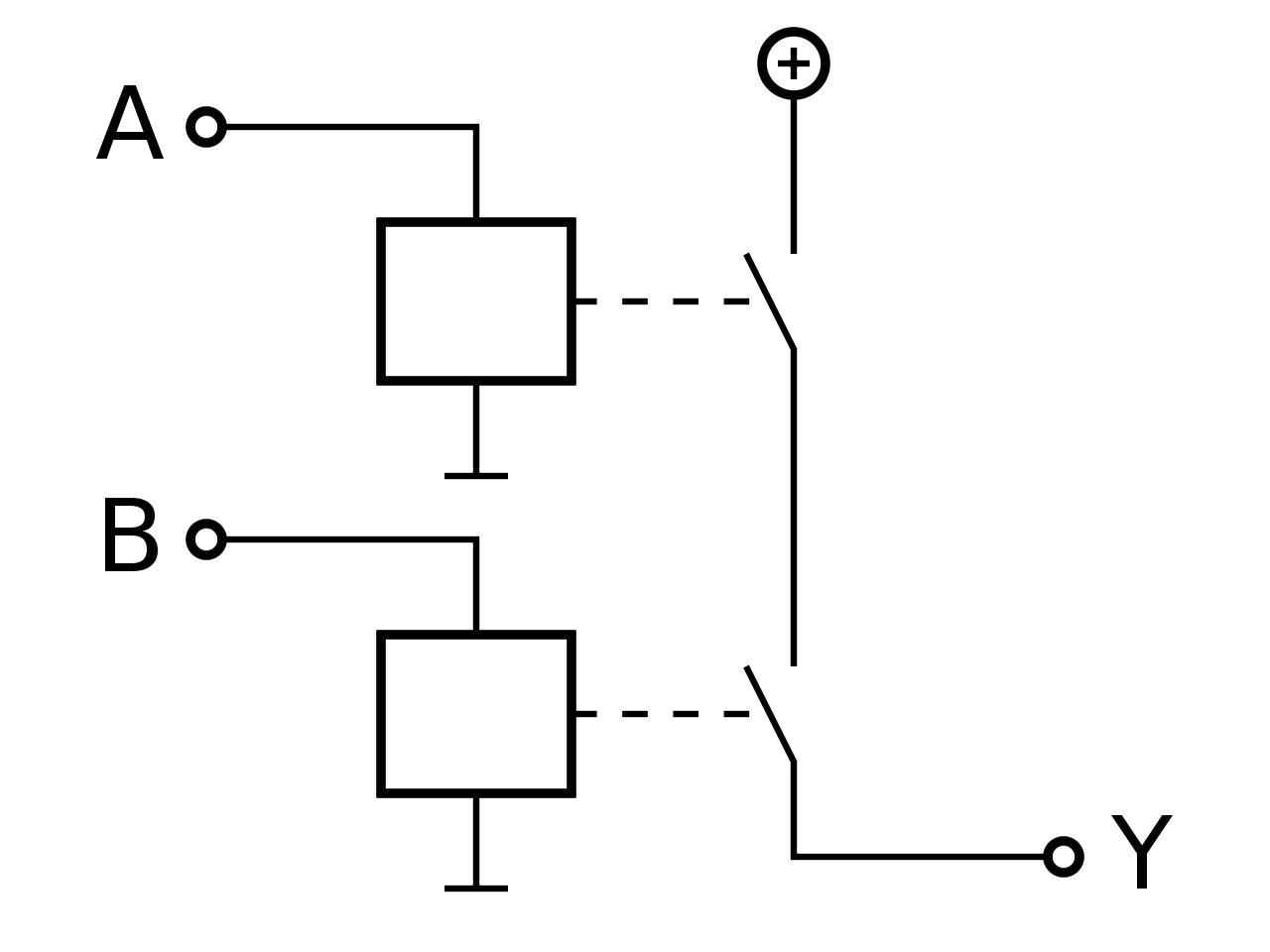 |
| NAND |
 |
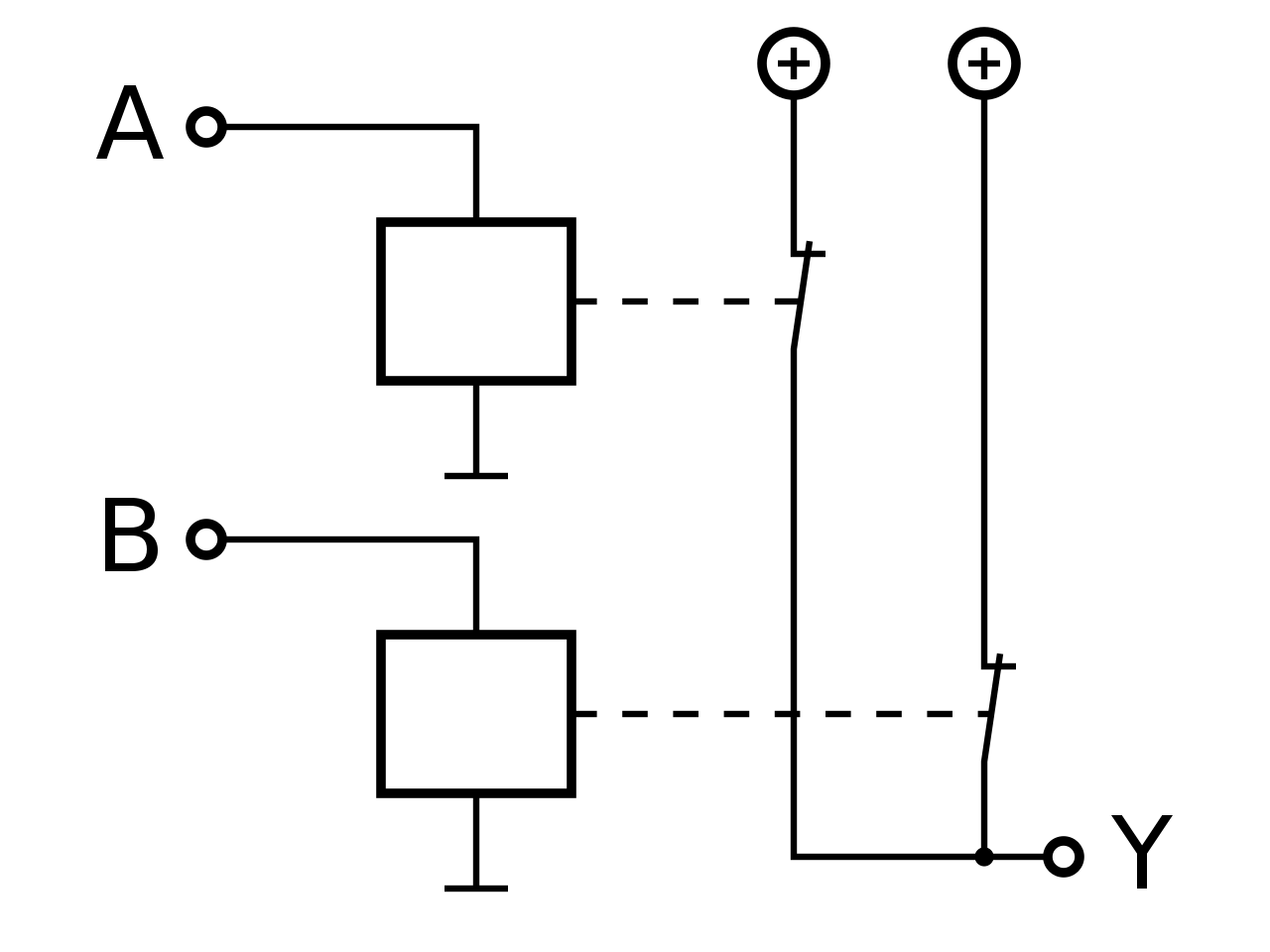 |
|
| OR |
 |
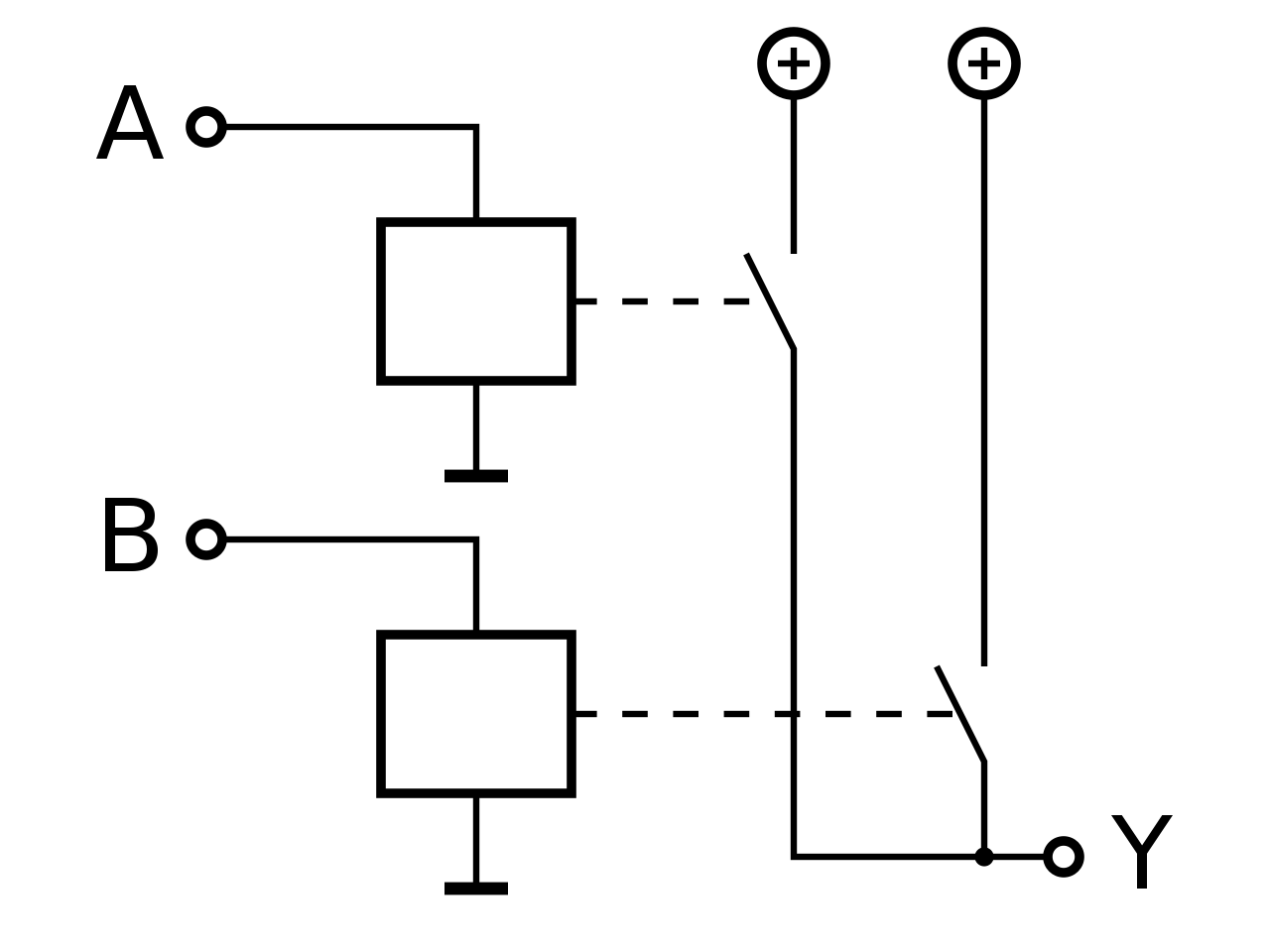 |
|
| NOR |
 |
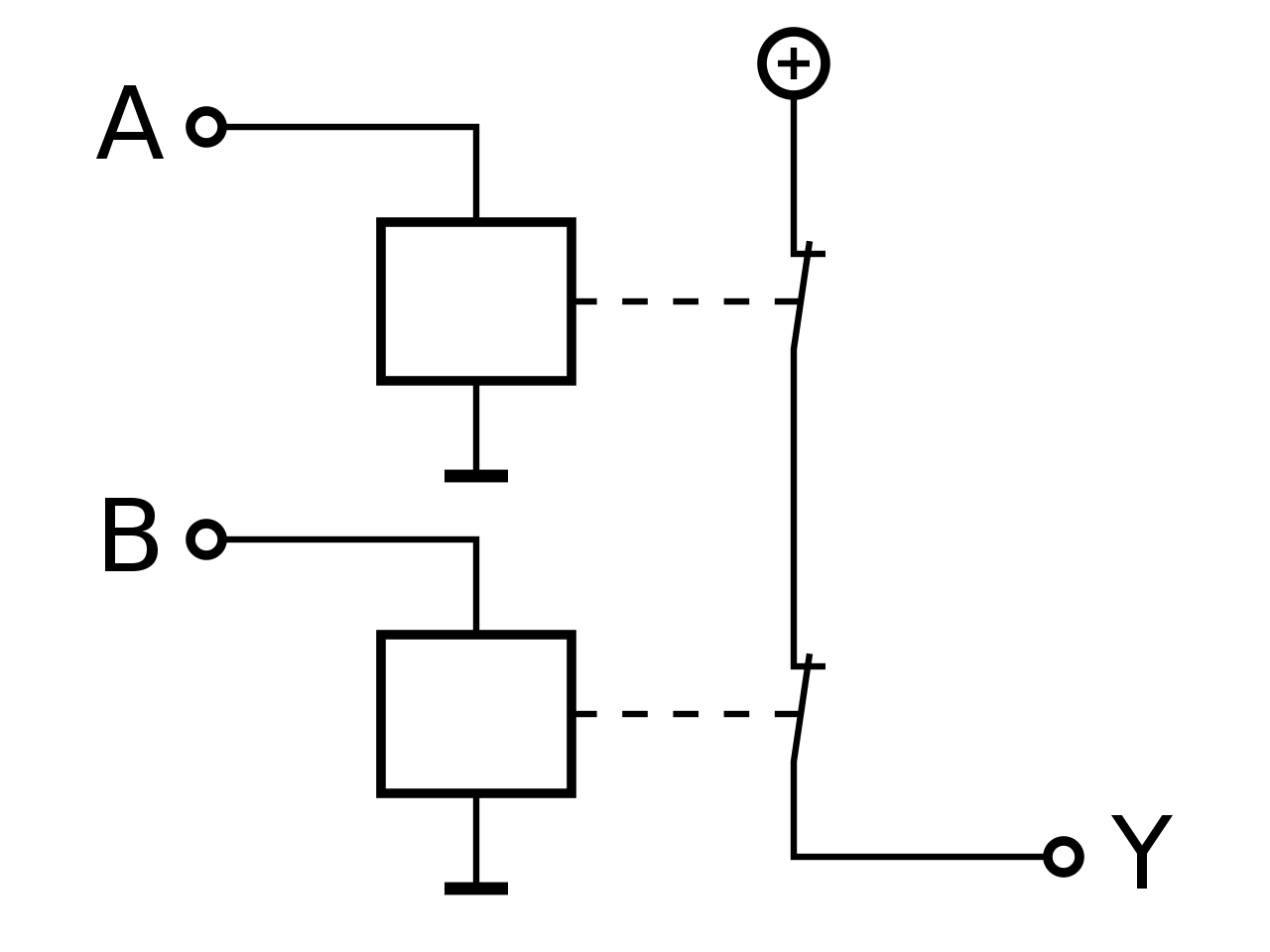 |
|
| XOR |
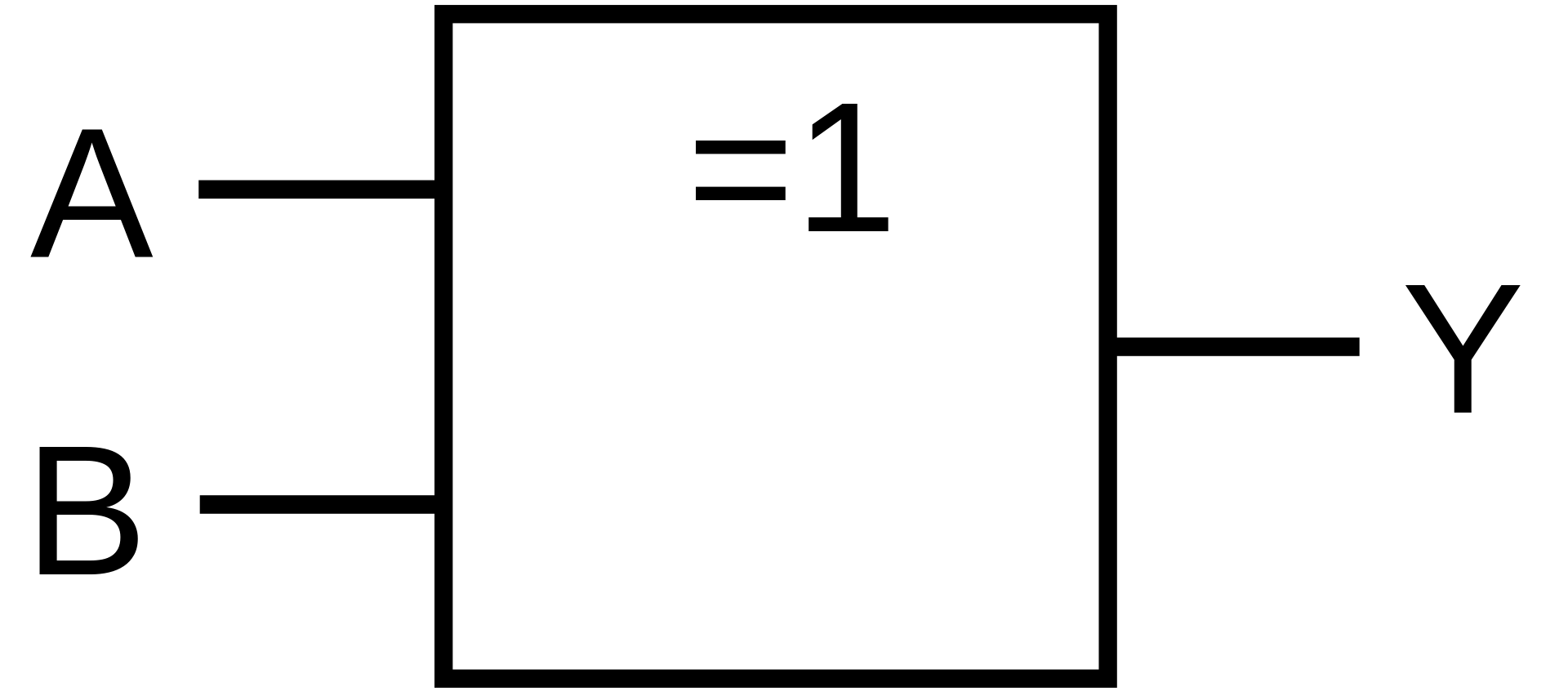 |
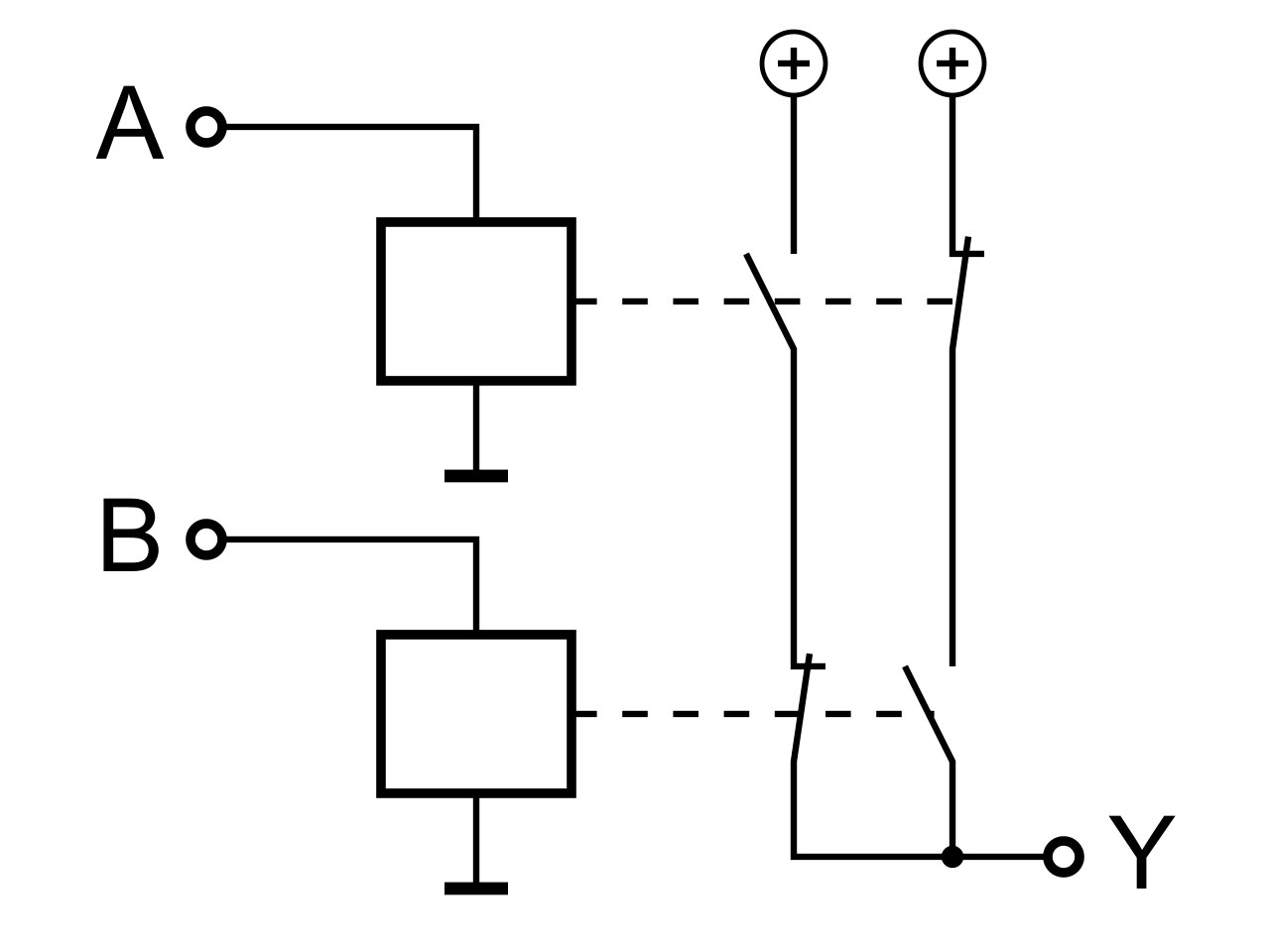 |
|
| XNOR |
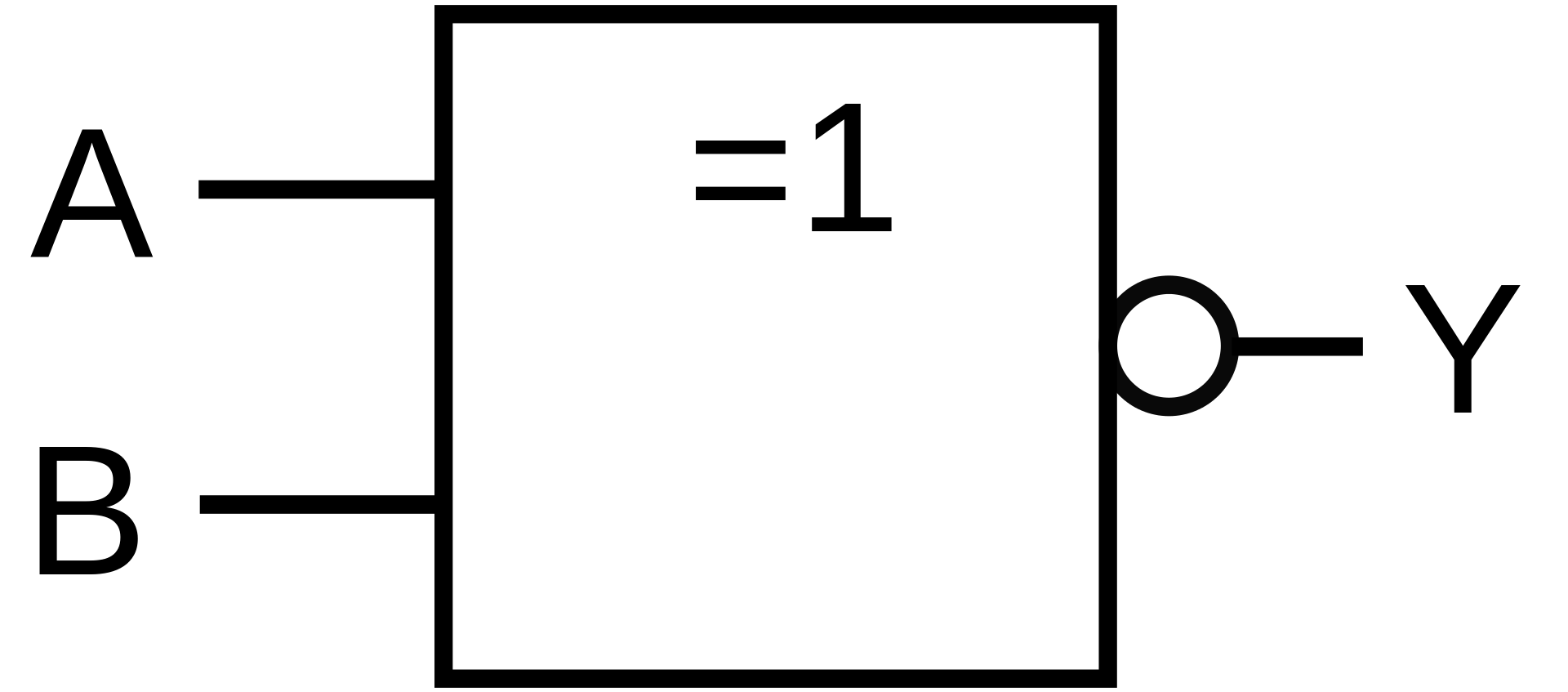 |
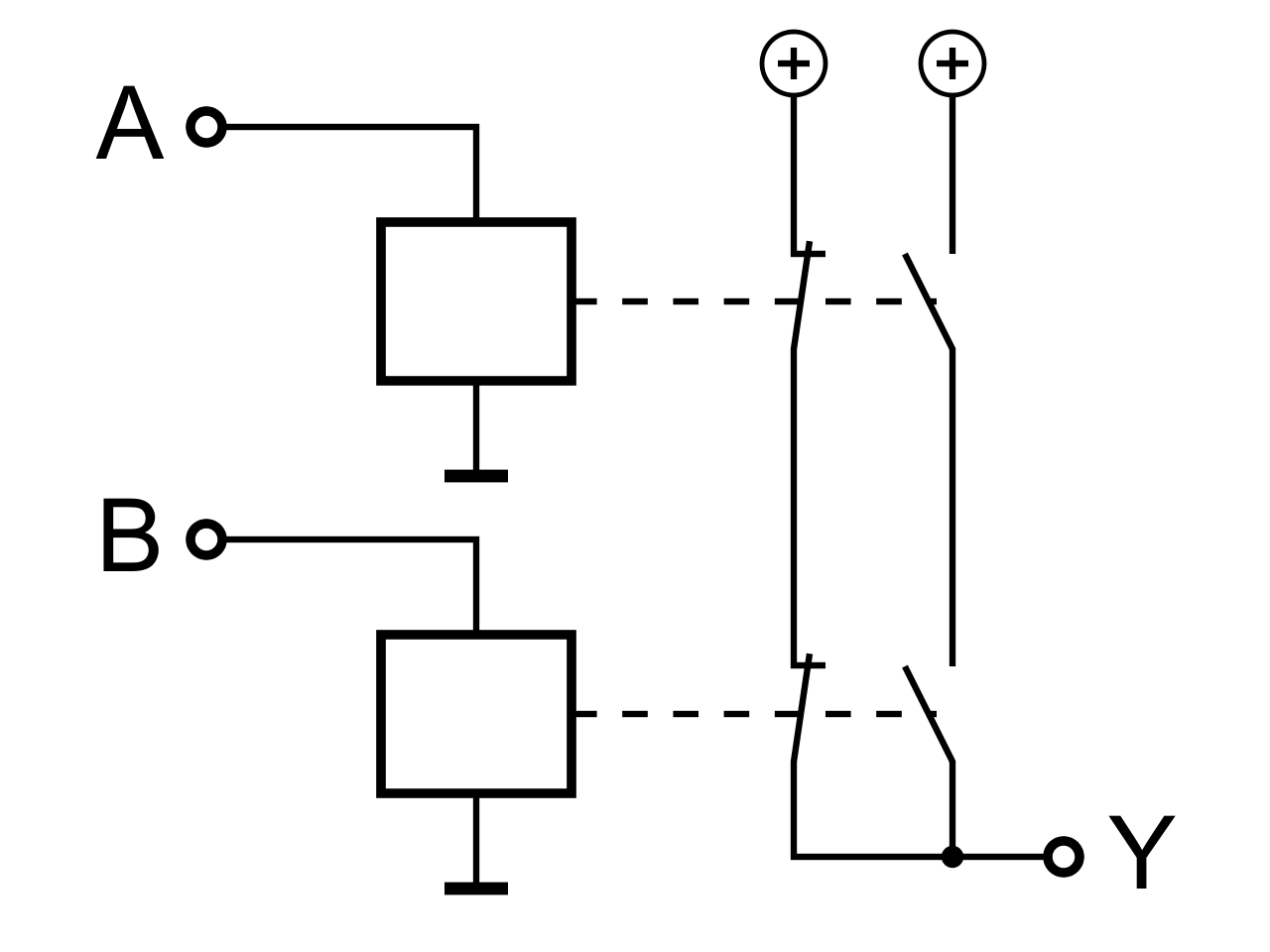 |
|
| NOT |
 |
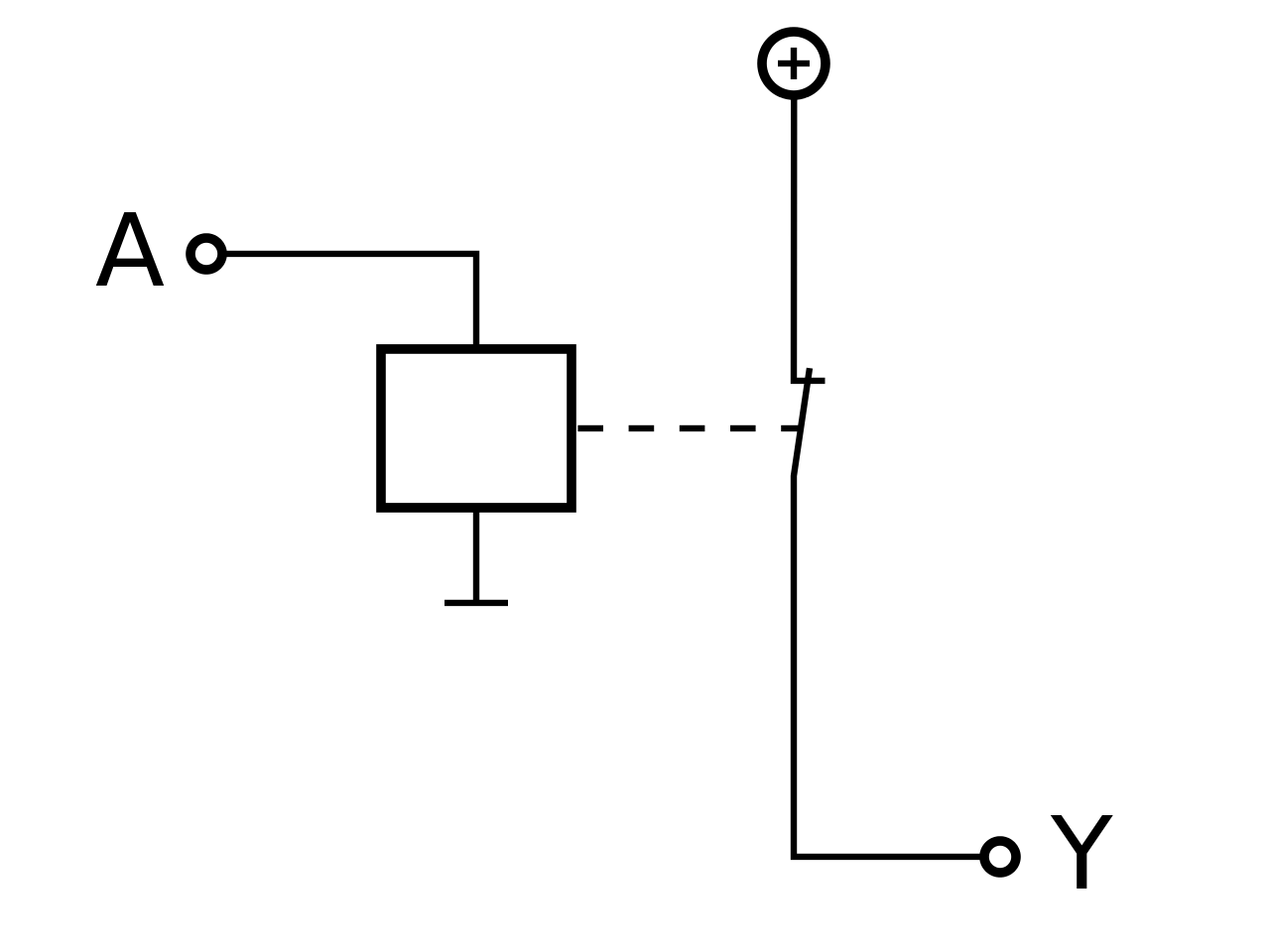 |







Berechnungshilfe
Binär |
Dezimal |
Hexadezimal |
|||
| 0 |
0 |
0 |
0 |
0 |
0 |
| 0 |
0 |
0 |
1 |
1 |
1 |
| 0 |
0 |
1 |
0 |
2 |
2 |
| 0 |
0 |
1 |
1 |
3 |
3 |
| 0 |
1 |
0 |
0 |
4 |
4 |
| 0 |
1 |
0 |
1 |
5 |
5 |
| 0 |
1 |
1 |
0 |
6 |
6 |
| 0 |
1 |
1 |
1 |
7 |
7 |
| 1 |
0 |
0 |
0 |
8 |
8 |
| 1 |
0 |
0 |
1 |
9 |
9 |
| 1 |
0 |
1 |
0 |
10 |
a |
| 1 |
0 |
1 |
1 |
11 |
b |
| 1 |
1 |
0 |
0 |
12 |
c |
| 1 |
1 |
0 |
1 |
13 |
d |
| 1 |
1 |
1 |
0 |
14 |
e |
| 1 |
1 |
1 |
1 |
15 |
f |
Mit Hilfe dieser Tabelle kann man sehr leicht jede dezimal Zahl in eine hexadezimale Zahl umrechnen. Dabei geht man den Umweg über die binären Zahlen. Der Rückweg ist ebenfalls möglich.
Umrechnung am Beispeil von 999
| Dividend |
Divisor |
Quotient |
Rest |
||
| 999 | / |
2 |
= |
499 | 1 |
| 499 | / |
2 |
= |
249 | 1 |
| 249 | / |
2 |
= |
124 | 1 |
| 124 | / |
2 |
= |
62 | 0 |
| 62 | / |
2 |
= |
31 | 0 |
| 31 | / |
2 |
= |
15 | 1 |
| 15 | / |
2 |
= |
7 | 1 |
| 7 | / |
2 |
= |
3 | 1 |
| 3 |
/ |
2 |
= |
1 |
1 |
| 1 |
/ |
2 |
= |
0 |
1 |
- Es ergibt sich die binäre Zahl (von unten nach oben gelesen):
1111100111 - Diese wird von rechts nach links in vierer Blöcke unterteilt:
11 | 1110 | 0111 - sollte der Block ganz links nicht aus vier Bit bestehen wird mit Null aufgefüllt:
0011 | 1110 | 0111 - jeder Block kann mit Hilfe der Tabelle in eine hexadezimale Zahl umgewandelt werden:
3 | e | 7 -> 0x 3e7
VLAN
Ein VLAN ist eine Struktur, in welcher Netzwerkswitche in mehrere „logische Switche“ aufgeteilt und voneinander isoliert werden.
Jedes VLAN bildet ein eigenes Netz. Jedes LAN bildet eine Broadcastdomäne. Broadcasts bleiben somit im eigenen VLAN und gelangen nicht in andere. Damit zwei Rechner in unterschiedlichen VLANs miteinander kommunizieren können, müssen diese über einen Router verbunden werden.
VLAN Typen
Uplinks einzelner logischer Switche, werden physikalisch zu einem Link zusammengefasst. Damit die Datenframes der einzelnen logischen virtuellen Netzwerke dem jeweiligen VLAN zugeordnet werden können, müssen die Frames mit VLAN-Tags modifiziert werden. Die Zugehörigkeit zum virtuellen Netzwerk muss zusätzlich im Frame (Layer-2, Ethernet-Frame) transportiert werden.
Tagged und Untagged VLANs
Der PC schickt einen normalen Datenframe heraus. Der Switch macht die Zuordnung zum virtuell LAN und erweitert den Frame mit dem Tag. Das so gekennzeichnete Ethernet-Frame wird wie gewohnt durch das Netzwerk transportiert. Der letzte Switch entfernt diesen VLAN-Tag wieder, bevor er die Daten an den Zielrechner schickt.
Untagged VLAN bedeutet, dass der komplette Switchport dem VLAN angehört. Egal welches Gerät angeschlossen wird, wird automatisch im definierten VLAN landen. Untagged VLAN ist auch als portbasierten VLAN bekannt.
VLAN-Trunking
Mit VLAN-Trunking lassen sich Switches so verschalten, dass sie mehrere verschiedene VLANs untereinander zu Netzwerken verbinden. VLAN-Trunking ist in der Lage, die Informationen mehrerer virtueller LANs über eine einzige Leitung zu übertragen. Es lassen sich einzelne oder gebündelte Ports für das Trunking verwenden.
Bei portbasierten VLANs (d. h. bei Paketen, die kein Tag besitzen) wird zum Weiterleiten eines Datenpakets über einen Trunk hinweg üblicherweise vor dem Einspeisen in den Trunk ein VLAN-Tag hinzugefügt, welches kennzeichnet, zu welchem VLAN das Paket gehört. Der Switch auf Empfängerseite muss dieses wieder entfernen. Bei tagged VLANs (nach IEEE 802.1Q) hingegen werden die Pakete entweder vom Endgerät (z. B. Tagging-fähigem Server) oder vom Switch am Einspeiseport mit dem Tag versehen. Daher kann ein Switch ein Paket ohne jegliche Änderung in einen Trunk einspeisen.
Kollisions- und Broadcastdomäne
Kollisionsdomäne: alle Stationen auf einem gemeinsamen Medium
Teilen sich mehrerer Endgeräte ein Medium (Netzwerkkabel, WLAN, etc.), spricht man von einem shared medium. Zusammen bilden sie eine Kollisionsdomäne. Senden zwei oder mehrere Endgeräte gleichzeitig, so kommt es zu Kollisionen auf dem Medium. Steigt die Anzahl der Endgeräte, so steigt auch die Anzahl der Kollisionen. Sind zu viele Stationen vorhanden, dann ist gar keine Kommunikation mehr möglich und das Medium ist dauernd (durch Kollisionen) belegt.
Broadcastdomäne: alle Stationen eines Netzes
Eine Broadcast-Meldung ist eine Rundsendung an alle Netzwerkteilnehmer. Die Menge der Stationen, die eine Broadcastmeldung empfangen, bildet eine Broadcastdomäne.
Durch VLANs verringert sich der Traffic auf einer Kollisionsdomäne durch Reduzierung der Broadcastmeldungen, da VLANs die Broadcastdomäne verkleinern.
Unicast, Multicast, Broadcast und Anycast
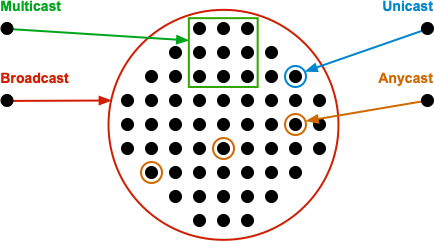
Netzwerk-Topologien beschreiben, wie die Teilnehmer eines Netzwerks physikalisch zusammengeschaltet sind. Darauf aufbauend werden dann logische Verbindungen geschaltet. Die Verbindungsart bzw. die Beschreibung des Verbindungsziels hat dabei Einfluss auf die Adresse und die Übertragung.
Unicast
Bei Unicast sind zwei Stationen miteinander verbunden. Sie können direkt oder über ein Netzwerk miteinander kommunizieren. Die Verbindung kann sowohl unidirektional als auch bidirektional sein.
Beim Unicasting steigt die notwendige Bandbreite bei jedem zusätzlichen Host im Netzwerk an. Dabei kann die Netzlast soweit steigen, dass die Informationen bei keinem Host mehr in ausreichender Geschwindigkeit ankommt. So kommt es beim Audio- und Video-Streaming zu Aussetzern beim Abspielen.
Multicast
Bei Multicast gibt es einen Sender, der zu einer definierten Gruppe von Empfängern Signale, Daten und Informationen überträgt. Hier spielt es keine Rolle, wie viele Empfänger die Daten empfangen. Die Bandbreite wird nur für einen Teilnehmer verbraucht. Die letzte Verteilstelle (Router) ist dann für die Verteilung an die einzelnen Empfänger verantwortlich. Die Daten werden beim letzten Router dupliziert.
Broadcast
Der Broadcast ist ein Datenpaket, dass an einem Punkt ins Netzwerk eingespeist und von dort an alle Hosts übertragen wird. Dabei empfängt jeder Host die Daten, ob er will oder nicht. Es handelt sich dabei um das klassische Gießkannenprinzip bei der Verteilung von Informationen, wie es zum Beispiel beim Rundfunk (UKW/DAB) oder Fernsehen (Satellit, Kabel, Funk) gemacht wird.
Anycast
Bei Anycast geht die Nachricht an einen Empfänger aus einer Gruppe von Empfängern. An wen aus der Gruppe ist hierbei egal. Hinter Anycast steckt das Verständnis, dass es eine Adresse mehrfach gibt bzw. geben kann (Anycast-Adresse). Das bedeutet dann aber, dass kein wechselseitiger Dialog möglich ist, weil nicht sicher ist, ob man immer mit der selben Maschine verbunden ist.
Anycast wird bspw. für Root-Nameserver benutzt. Hier gibt es nicht nur einen Root-Server, sondern in der Regel ganz viele davon, die auf der ganzen Welt verteilt sind. Aber alle haben die selbe Adresse. Ein Router kennt die Route zu einem von diesen Root-Servern und reicht das Anycast-Paket an diesen weiter.
WLAN-Authentifizierung
IEEE 802.1X
IEEE 802.1x ist ein sicheres Authentifizierungsverfahren für Zugangskontrollen in lokalen Netzwerken (LAN). Im Zusammenhang mit IEEE 802.1x werden auch häufig EAP und RADIUS genannt.
Der Standard definiert drei grundlegende Funktionskomponenten. Diese sind:
- der Antragsteller (Supplicant): zum Beispiel ein Rechner in einem LAN oder WLAN
- der Unterhändler (Authenticator): zum Beispiel ein LAN-Switch oder WLAN-Accesspoint
- der Authentifizierungsserver (Authentication Server): zum Beispiel ein RADIUS-Server
Ein Client, der Zugang zu einem LAN oder WLAN benötigt, wendet sich zunächst an den Unterhändler. Er sendet seine Anmeldedaten an einen Authenticator (zum Beispiel Switch oder WLAN-Accesspoint). Der Informationsaustausch findet per Extensible Authentication Protocol (EAP) statt. Der Authenticator nimmt die Anfrage entgegen und leitet die Anmeldeinformationen an den Authentication Server (zum Beispiel einen separaten RADIUS-Server) weiter. Der Authentication Server ist für die Benutzerverwaltung und -authentifizierung zuständig. Er prüft die erhaltenen Anmeldeinformationen und teilt das Ergebnis dem Authenticator mit. Dieser schaltet abhängig von der Prüfung der Anmeldedaten den logischen oder physischen Zugang zum lokalen Netzwerk (zum Beispiel einen Switch-Port) frei oder verweigert den Zugang.
Funktionen von .1x
- Zugangskontrolle
- Authentifizierung, Autorisierung und Accounting (AAA)
- Bandbreitenzuweisung (QoS)
- Single Sign-on (SSO)
AAA-Server (Authentifizierung, Autorisierung und Accounting)
„Authentication Authorization Accounting“, kurz AAA, steht für ein Sicherheitskonzept in dem die drei Hauptaufgaben Authentifizierung, Autorisierung und Accounting zusammengefasst sind. Mit AAA kann man die Zugangskontrolle in einem Netzwerk organisieren.
SAE
Abschlussprüfung Teil 2
HTML
Einführung:
Bei HTML handelt es sich NICHT um eine Programmiersprache sondern um eine Beschreibungssprache. HTML steht für "Hypertext Markup Language". Diese zeichnet sich dadurch aus, dass optimalerweise jeder Bereich in sogenannte Tags gefasst wird.
Jedes HTML Dokument besteht aus folgendem Grundgerüst:
<!doctype html>
<html lang="de">
<head>
<!-- Hier kommen alle Metadaten hin -->
<meta charset="utf-8"/>
<meta name="viewport" content="width=device-width, initial-scale=1.0"/>
<title>Hierhin gehört der Seitentitel</title>
</head>
<body>
<!-- Hier kommt der gesamte Inhalt rein -->
<h1> Überschrift </h1>
</body>
</html> Ein HTML Dokument dient zwar offiziell nur für den Inhalt und das Grundgerüst einer Website. Dennoch ist es in einem gewissen Rahmen auch möglich, das Aussehen einer Website zu bearbeiten. Die zugehörigen Tags können folgender Tabelle entnommen werden:
Textdesign
| Überschriften |
<h1>Überschrift</h1> kann von 1 bis 6 verwendet werden |
| Paragraph |
<p>Textparagraph</p> |
| Fett |
<b>Fett</b> |
| Kursiv |
<em>Kursiv</em> |
| Markiert |
<mark>Markiert</mark> |
| Klein |
<small>Klein</small> |
| Unterstrichen |
<ins>Unterstrichen</ins> |
| Durchgestrichen |
<del>Durchgestrichen</del> |
| Hochgestellt |
<sup>Hochgestellt</sup> |
| Tiefgestellt |
<sub>Tiefgestellt</sub> |
| Abkürzungen |
<p><abbr title="World Health Organization">WHO</abbr> </p>
|
| Anführungszeichen |
<q>Quotes</q> |
Es gibt in HTML zwei verschiedene Arten von Elementen. Es gibt zum einen die Block Elemente, die immer in einer neuen Zeile beginnen, zum anderen gibt es die Inline Elemente, die im Fliesstext stattfinden.
Style Attribute?
Tabellen und Listen
<table>
<tr> <!-- Neue Zeile -->
<th colspan="2">Name</th> <!-- Tabellenüberschrift, die sich über 2 Spalten streckt -->
<th>Age</th> <!-- Zelleninhalt -->
</tr>
<tr>
<td>Jill</td>
<td>Smith</td>
<td>43</td>
</tr>
<tr>
<th rowspan="2">Phone</th> <!-- Zeilenbeschriftung, die sich über 2 Zeilen streckt -->
<td>555-1234</td>
<td>xyz</td>
</tr>
<tr>
<td>Eve</td>
<td>Jackson</td>
</tr>
</table>Listen
<!-- Geordnete Listen -->
<ol>
<li>Coffee</li>
<li>Tea
<ol type="a">
<li>Black tea</li>
<li>Green tea</li>
</ol>
</li>
<li>Energy
<ol type="A">
<li>Red Bull</li>
<li>Monster</li>
</ol>
</li>
<li>Milk</li>
</ol>
<!-- Ungeordnete Listen -->
<ul>
<li>Coffee</li>
<li>Tea
<ul>
<li>Black tea</li>
<li>Green tea</li>
</ul>
</li>
<li>Milk</li>
</ul>
<!-- Sonstige Listen -->
<dl>
<dt>Coffee</dt>
<dd>- black hot drink</dd>
<dt>Milk</dt>
<dd>- white cold drink</dd>
</dl>Klassen
Auch in HTML gibt es Klassen. Allerdings definieren diese hier nur, dass alles innerhalb eines Bereichs zu einer Klasse gehört. Auf diese Klassen können dann mit CSS oder JavaScript Veränderungen angewendet werden. Die Zuweisung geschieht wie in folgendem Code gezeigt:
<div class="city">
<h2>London</h2>
<p>London is the capital of England.</p>
</div>Des weiteren kann jedem Element ein einzigartiger Identifyer zugewiesen werden. Dies geschieht mittels dem id Element.
<h1 id="myHeader">My Header</h1>Links
Links auf andere Websites können in HTML wie folgt eingebunden werden. Dabei ist zu beachten, dass der Linktext nicht zwingend gleich dem eigentlichen Link sein muss.
<a href="https://doku.stnd.io">This is a link</a> Struktogramme
- auch als Nassi-Shneiderman-Diagramme bekannt
- Ziel: Darstellung eines Programms unabhängig von der Programmiersprache
- Symbole
- mit Hilfe dieser Symbole lässt sich der Ablauf eines Programms beschreiben
- fast alle Symbole lassen sich beliebig ineinander verschachteln
- Prozess Symbol / Process Symbol: Anweisungen werden nacheinander von oben nach unten durchlaufen

# Anweisungen in Python
a = input("Zahl eingaben") # Anweisung 1
b = 5 * a # Anweisung 2
print(b) # Anweisung 3 - Verzweigung / Decision Symbol: Bedingung wird geprüft, wenn Sie zu trifft wird "ja" ausgeführt, andernfalls "nein". Kann verschachtelt sein.

# Verzweigung in Python
if (a == 5): # Prüfung der Variablen a -> Ergebnis True oder False
print("a ist fünf") # Wenn Prüfung True, wird dieser Block ausgeführt
else:
print("a ist nicht fünf") # Wenn Prüfung False, wird dieser Block ausgeführt

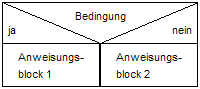
-
-
- Sonderfall: Case-Statement: Inhalt der Variablen wird geprüft und entsprechender Fall wird ausgeführt. Manche Programmiersprachen haben "Switch" ansonsten mit "if - else if - else" auflösbar.

// Mit Switch in C aufgelöst
case (a) { // Angabe welche Variable geprüft werden soll
1: printf("a hat den Wert eins"); // Auswahl entsprechend der Prüfung
2: printf("a hat den Wert zwei");
3: printf("a hat den Wert drei");
default: print("a ist größer drei"); // Sollte keine Prüfung zutreffen wird dieser Fall ausgeführt
};
// Mit if - else if - else aufgelöst
if (a == 1) { // Prüfung der Variable a -> Ergebnis True / False
printf("a hat den Wert eins"); // Block der True als Ergebnis hat wird ausgeführt
} else if (a == 2) {
printf("a hat den Wert zwei");
} else if (a == 3) {
printf("a hat den Wert drei");
} else {
printf("a ist größer drei"); // Wird ausgeführt sollte kein Block True sein
};
- Sonderfall: Case-Statement: Inhalt der Variablen wird geprüft und entsprechender Fall wird ausgeführt. Manche Programmiersprachen haben "Switch" ansonsten mit "if - else if - else" auflösbar.
- Schleifen oder Wiederholungsstruktur: Struktur die solange durchlaufen wird, bis Endbedingung erfüllt ist
- Kopfgesteuerte - Schleifen (z.B. while und for): Bedingung wird vor ersten durchlauf geprüft und nur dann betretten, wenn Bedingung zutrifft. Kann also auch nicht durchlaufen werden, wenn Endbedingung direkt zutrifft.

// Kopfgesteuerte while-Schleife
while (i <= 10) { // Die Variable i wird geprüft, sollte sie bereits größer 10 sein, wird Schleife nicht ausgeführt
printf("%i\n", i); // Wird ausgeführt sollte i kleiner oder gleich 10 sein
i++;
}
// Kopfgesteuerte for-Schleife
for (i = 0; i <= 10; i++) { // Sonderfall i läuft von 0 bis 10
printf("%i\n", i);
} - Fußgesteuerte - Schleife (z.B. do-while): Endbedingung wird nach dem ersten Durchlauf geprüft und wenn diese Zutrifft, wird die Schleife beendet. Sollte sie nicht zu treffen, wird die Schleife solange durchlaufen bis die Bedingung zutrifft.

// Fussgesteuerte-Schleife
do { // Schleife wird betretten
printf("%i\n", a); // Schleife wird ausgeführt
a++;
} while (a <= 10); // Prüfung und sollte a größer 10 sein, wird Schleife beendet. Ansonsten wird Schleife erneut ausgeführt
- Kopfgesteuerte - Schleifen (z.B. while und for): Bedingung wird vor ersten durchlauf geprüft und nur dann betretten, wenn Bedingung zutrifft. Kann also auch nicht durchlaufen werden, wenn Endbedingung direkt zutrifft.
- Funktion und Funktionsaufruf: Um nicht mehrfach den gleichen Code schreiben zu müssen, kann man Funktionen schreiben die man immer wieder aufrufen kann. Dazu muss man zwei Dinge beachten.
Zum Einen muss die Funktion aufgerufen werden ggf. Parameter übergeben werden. Zum Anderen wird die Funktion als eigenes Struktogram geschrieben und am Anfang die möglichen Übergabeparamet genannt.
Sollte die Funktion Rückgabeparameter haben sind diese mit Rückgabe zu markieren (nicht Ausgabe).- Funktionsaufruf

// Möglicher Funktionsaufruf in C
// Funktionsdefinition
int berechne(int zahl1, int zahl2) { // Funktion bekommt zwei Integer übergeben und gibt einen Integer zurück
int ergebnis; // lokale Variable
ergebnis = zahl1 + zahl2; // Berechnung von ergebnis
return ergebnis; // Rückgabewert
}
//Hauptfunktion
void main(void) {
int a; // Deklaration von Variablen
int b;
int c;
a = 4; // Zuweisung von Wert an Variable
b = 5;
c = ergebnis(a, b); // Aufruf von Funktion "berechne" Übergabeparameter sind Werte von a, b. Rückgabe von Funktion wird zugewiesen
printf("%i\n", c); // Ausgabe von c
} - Beispiel Code als Struktogramme dargestellt. Hauptfunktion (main) und aufgerufene Funktion (berechne)


- Funktionsaufruf
-
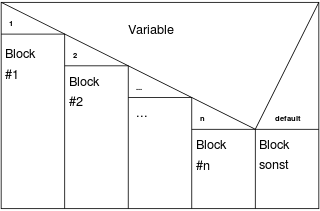




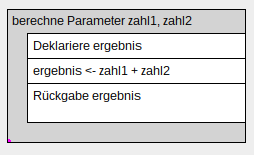
Datenbanken
Normalisierung von Datenbanken
Unter Normalisierung einer relationalen Datenbank versteht man die Aufteilung von Attributen in mehrere Relationen (Tabellen) mit Hilfe der Normalisierungsregeln. Insgesamt gibt es fünf Normalformen, aber im Alltag reicht eine Normalisierung bis zur dritten Normalform vollkommen aus. Die vierte und fünfte Normalform sind für Spezialfälle wie Atomkraftwerke usw. notwendig.
Die einzelnen Normalformen bauen aufeinander auf, d.h. die dritte Normalform ist nur erfüllt wenn auch die zweite Normalform erfüllt ist und die zweite Normalform ist nur erfüllt, wenn auch die erste Normalform erfüllt ist.
Ziel der Normalisierung:
- Beseitigung von Redundanzen
- Vermeidung von Anomalien
- Erstellen eines klar strukturierten Datenbankmodells
Erste Normalform (1NF)
Die erste Normalform ist dann erfüllt, wenn alle Informatione einer Tabelle atomar vorliegen. Atomar bedeutet, dass jede Information eine eigene Spalte bekommt.
Beispiel:
- nicht normalisierte Form
| R-Nr |
Datum |
Name |
Straße |
Ort | Artikel | Anzahl |
Preis |
| 187 |
01.01.2022 |
Max Mustermann |
Musterweg.1 |
12345 Musterstadt |
Bleistift |
5 |
1.00€ |
- erste Normalform
| R-Nr |
Datum |
Name |
Vorname |
Straße |
Hnr |
PLZ |
Ort |
Artikel |
Preis |
Währung |
| 187 |
01.01.2022 |
Mustermann |
Max |
Musterstr. |
1 |
12345 |
Musterstadt |
5 |
1.00 |
Euro |
Zweite Normalform (2NF)
Die zweite Normalform ist dann erfüllt, wenn jedes nicht-Schlüsselattribut voll funktional vom Schlüssel abhängig ist.
Beispiel:
- zweite Normalform
| Rechnung | ||
| R-Nr |
Datum |
Knr |
| 187 |
01.01.2022 |
007 |
| Kunde | ||||||
| Knr |
Name |
Vorname |
Straße |
Hnr |
PLZ |
Ort |
| 007 |
Mustermann |
Max |
Musterstr. |
1 |
12345 |
Musterstadt |
| Rechnungsposition | |||
| R-P-NR |
R-Nr |
Art-Nr |
Anzahl |
| 1 |
187 |
69 |
5 |
| Artikel | ||
| Art-Nr |
Artikel |
Preis |
| 69 |
Bleistift |
1.00 |
Dritte Normalform (3NF)
Die dritte Normalform ist dann erfüllt, wenn kein Nichtschlüsselattribut transitiv von einem Kandidatenschlüssel abhängt. Einfacher gesagt, es gibt immer nur einen möglichen Primärschlüssel und kein Attribut die auch Primärschlüssel sein können werden zusätzliche Tabellen ausgelagert und als Fremdschlüssel eingebunden.
Beispiel:
- dritte Normalform
| Kunde | |||||
| Knr |
Name |
Vorname |
Straße |
Hnr |
PLZ |
| 007 |
Mustermann |
Max |
Musterstr. |
1 |
12345 |
| Postleitzahl |
|
| PLZ |
Ort |
| 12345 |
Musterstadt |
Manipulation von Datenbanken
Eine Datenbank ist eine organisierte Sammlung von strukturierten Informationen oder Daten, die elektronisch in einem Computer gespeichert werden. Eine Datenbank wird in der Regel von einem Datenbankmanagementsystem (DBMS) gesteuert. Die Daten und das DBMS werden zusammen mit den damit verbundenen Anwendungen als Datenbanksystem bezeichnet, oft auch nur als Datenbank.
Die Daten in den heute gebräuchlichsten Arten von Datenbanken werden in der Regel in Zeilen und Spalten in einer Reihe von Tabellen dargestellt, um eine effiziente Verarbeitung und Datenabfrage zu ermöglichen. Die Daten können dann leicht abgerufen, verwaltet, geändert, aktualisiert, kontrolliert und organisiert werden. Die meisten Datenbanken verwenden eine strukturierte Abfragesprache (SQL) zum Schreiben und Abfragen von Daten.
|
Die Es gibt zwei Varianten:
|
|
Die DELETE Anweisung wird verwendet, um Datensätze (Zeilen) in einer Tabelle zu löschen. Die WHERE Anweisung gibt an, welcher Datensatz oder welche Datensätze gelöscht werden sollen. Wenn WHERE weggelassen wird, werden alle Datensätze gelöscht. |
|
Die UPDATE Anweisung wird verwendet, um Datensätze (Zeilen) in einer Tabelle zu bearbeiten. Sie enthält eine SET Anweisung, die die zu bearbeitende Spalte angibt, und eine WHERE Anweisung, die den oder die Datensätze spezifiziert. |
|
Datenbank Abfragen
Mit dem AND Operator können mehrere Bedingungen kombiniert werden. Die Datensätze müssen beiden Bedingungen entsprechen, die mit AND verknüpft sind, um in die Ergebnisse aufgenommen zu werden. Die angegebene Abfrage zeigt alle Autos an, die blau sind und nach 2014 hergestellt wurden. |
|
Mit dem OR Operator können mehrere Bedingungen kombiniert werden. Datensätze, die einer der beiden Bedingungen entsprechen, die durch das OR verbunden sind, werden in die Ergebnisse aufgenommen. Die angegebene Abfrage findet Kunden, deren Staat entweder „CA“ oder „NY“ ist. |
|
WHERE wird verwendet, um Datensätze (Zeilen) zu filtern, die eine bestimmte Bedingung erfüllen. Die angegebene Abfrage wählt alle Datensätze aus, bei denen das pub_year gleich 2017 ist. |
|
Mit LIKE kann innerhalb einer WHERE ein bestimmtes Muster abgefragt werden. Die angegebene Abfrage findet jeden Film, dessen Titel mit „Star“ beginnt. |
|
Der Platzhalter % kann mit LIKE verwendet werden, um keine oder mehrere nicht spezifizierte Zeichen zu finden. Die angegebene Abfrage findet jeden Film, der mit „The“ beginnt, gefolgt von keinem oder mehreren beliebigen Zeichen. |
|
Der Platzhalter _ kann mit LIKE verwendet werden, um ein beliebiges einzelnes, nicht spezifiziertes Zeichen zu finden. Die angegebene Abfrage findet jeden Film, der mit einem einzelnen Zeichen beginnt, gefolgt von „ove“. |
|
Die SELECT * Anweisung gibt alle Spalten aus der angegebenen Tabelle in der Trefferliste zurück. Die angegebene Abfrage holt alle Spalten und Datensätze (Zeilen) aus der Tabelle „Filme“. |
|
|
|
|
Der Operator BETWEEN kann zum Filtern nach einem Wertebereich verwendet werden. Bei dem Wertebereich kann es sich um Text, Zahlen oder Datumsdaten handeln. Die angegebene Abfrage findet alle Filme, die zwischen den Jahren 1980 und 1990 gedreht wurden. |
|
Die Bedingung LIMIT wird verwendet, um die Ergebnisse auf eine bestimmte Anzahl von Zeilen zu begrenzen. Die angegebene Abfrage begrenzt die Ergebnismenge auf 5 Zeilen. |
|
Spalteninhalte können NULL sein oder keinen Wert haben. Diese Datensätze können mit den Operatoren IS NULL und IS NOT NULL in Kombination mit WHERE abgeglichen werden. Die angegebene Abfrage wird alle Adressen anzeigen, bei denen die Adresse einen Wert hat oder nicht NULL ist. |
|
Erstellen von Tabellen
|
Nach |
|
Foreign Key
Ein Fremdschlüssel ist ein Verweis von Datensätzen einer Tabelle auf den Primärschlüssel einer anderen Tabelle. Um mehrere Datensätze für eine bestimmte Zeile zu erhalten, spielt die Verwendung von Fremdschlüsseln eine wichtige Rolle. Um z. B. alle Bestellungen eines bestimmten Kunden zu verfolgen, kann die Tabelle Bestellung (unten im Bild) einen Fremdschlüssel enthalten. 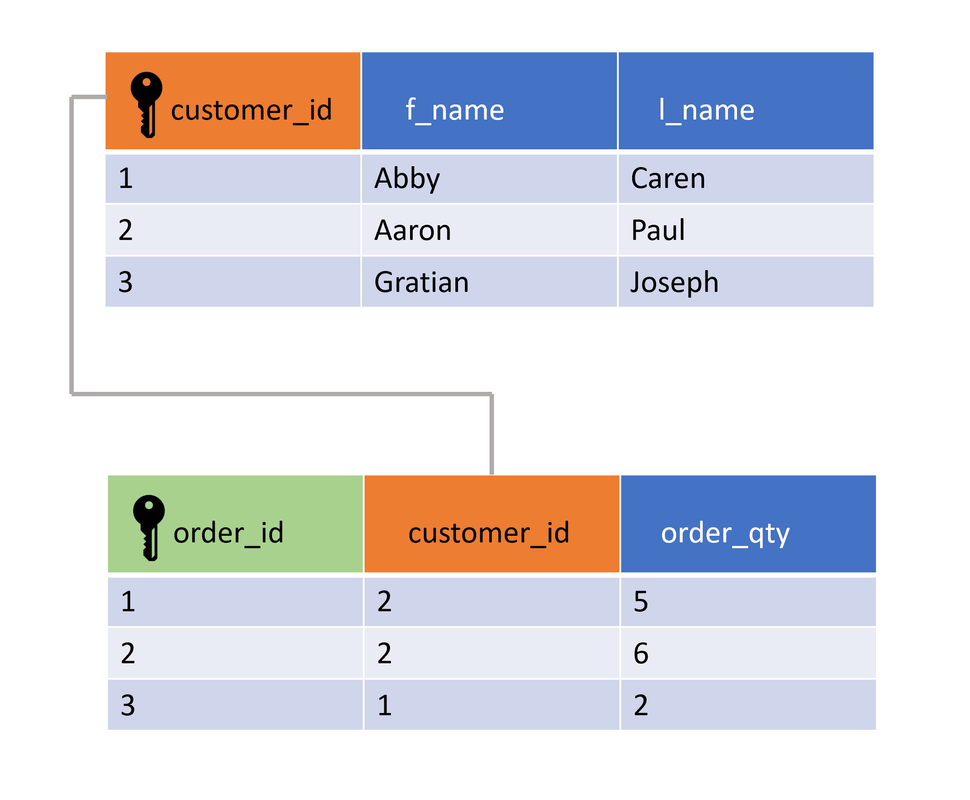
Primary Key
Ein Primärschlüssel in einer SQL-Tabelle wird verwendet, um jeden Datensatz in dieser Tabelle eindeutig zu identifizieren. Ein Primärschlüssel kann nicht NULL sein. In diesem Beispiel ist customer_id der Primärschlüssel. Derselbe Wert kann in einer Spalte nicht noch einmal vorkommen. Primärschlüssel werden oft in JOIN Operationen verwendet.
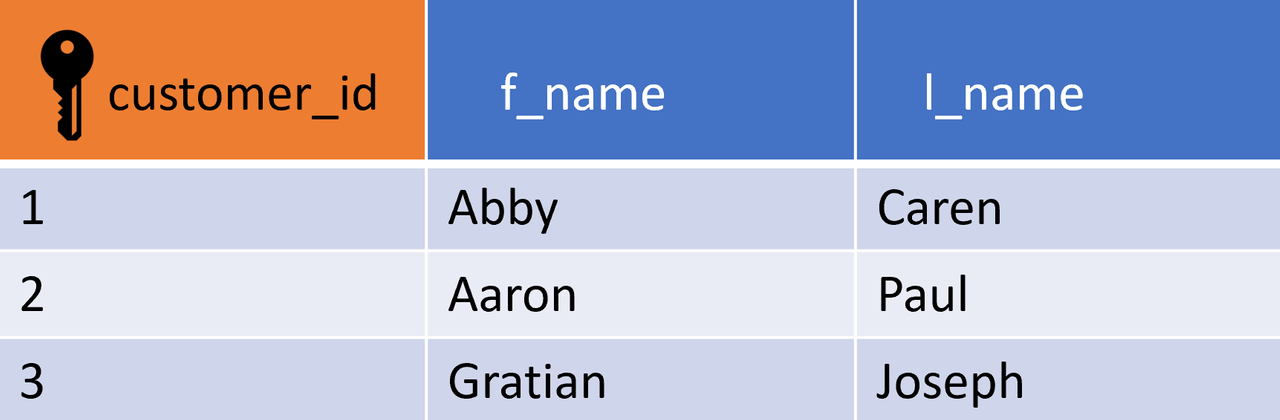
Mehrere Tabellen verbinden
Bei einem Outer Join werden Zeilen aus verschiedenen Tabellen kombiniert, auch wenn die Join-Bedingung nicht erfüllt ist. Bei einem LEFT JOIN wird jede Zeile der linken Tabelle in die Ergebnismenge zurückgegeben. Wenn die Join-Bedingung nicht erfüllt ist, wird NULL verwendet, um die Spalten der rechten Tabelle aufzufüllen. |
|
JOIN ermöglicht die Rückgabe von Ergebnissen aus mehr als einer Tabelle, indem sie diese mit anderen Ergebnissen auf der Grundlage gemeinsamer Spaltenwerte verbindet, die mit ON angegeben werden. INNER JOIN ist der Standard JOIN und gibt nur Ergebnisse zurück, die der durch ON angegebenen Bedingung entsprechen. |
|
Pseudocode
Pseudocode ist eine detaillierte und dennoch lesbare Beschreibung dessen, was ein Computerprogramm oder ein Algorithmus machen soll. Pseudocode wird in einer formal gestalteten, natürlichen Sprache und nicht in einer Programmiersprache ausgedrückt.
Fallunterscheidungen
if ... then ... else ... end if/exitwenn ... dann ... sonst ... wenn_endefalls ... dann ... falls_nicht ... falls_ende
Schleifen
wiederhole ... solange/bis ... wiederhole_endewhile ... do ...repeat ... until ...for ... to ... step Schrittweite ... next
Kommentare
// kommentar# kommentar/* kommentar */
Beispiel
WENN die Pizza in Folie eingepackt ist
Entferne Folie
schalte Ofen ein
gib Pizza auf Blech in Ofen
SOLANGE Pizza noch nicht fertig
warte eine Minute
entnimm Pizza aus dem Ofen
Python
Dateiverarbeitung
| Lesen |
|
| Schreiben |
|
| Leerzeichen entfernen |
|
Nutzerinteraktion
|
input() input("str") |
Unterbricht den Programmablauf und wartet auf Eingabe des Users. Programm wird danach fortgesetzt. Der Funktion kann ein String übergeben werde, der auf dem Bildschirm angezeigt wird. Die Eingabe des Users ist der Rückgabewert dieser Funktion. Rückgabewert ist immer String. |
|
Verzweigungen
if bmi < 19:
print("Untergewicht")
elif bmi <= 24:
print("Normalgewicht")
else:
print("Uebergewicht")Schleifen
| while |
|
| for (eigentlich foreach) |
|
Operatoren
| in |
Prüft ob Variable in angegebener Sequenz vorhanden ist vorhanden gibt "True" zurück nicht vorhanden gibt "False" zurück |
|
| range |
Funktion gibt eine Sequenz von Zahlen zurück
start = inklusiver Anfang der Sequenz, optional, default ist 0 stop = exklusves Ende der Sequenz, benötigt step = Inkrement, optional, default 1 |
|
Listen
| append() |
hängt Objekt an das Ende der Liste |
|
| index() |
gibt den ersten Index zu angegebenem Wert zurück |
|
| insert() |
fügt Wert vor Index ein
|
|
| remove() |
entfernt das erste Vorkommen des Werts |
|
| reverse() |
Umdrehen der Liste in-place |
|
| sort() |
Sortiert die Liste in-place default = aufsteigend "reverse=True" = absteigend |
|
| Ausgabe Formatierung |
Die Ausgabe von Listen kann nach folgender Notation formatiert werde
start = inklusiver Startwert, default 0 stop = exklusiver Stopwert, default Länge step = Inkrement, default 1 |
|
Umwandlung von Datentypen
Wichtig: Alle Funktionen sind KEINE in-place Ersetzung
| type() |
Gibt den Datentyp einer Variablen zurück |
|
| str() |
Rückgabewert dieser Funktion ist ein String |
|
| int() |
Rückgabewert dieser Funktion ist ein Integer |
|
| float() |
Rückgabewert dieser Funktion ist eine Fließkommazahl |
|
Web Requests
Allgemeines
Sogenannte Web Requests sind eigentlich Anfragemethoden des HTTP Protokolls. Sie dienen dazu, mit Webservern zu kommunizieren und die Anfrage zu Klassifizieren.
GET
Mithilfe des GET Requests werden Inhalte vom Server angefordert. Dieser ist so ziemlich der häufigste Vorgang. Die Anfrage wird in der URL mitgeschickt.
Mittels GET können auch Daten an den Server übertragen werden, allerdings ist hier die Menge an zu übertragenden Daten begrenzt (URL Begrenzung) daher sollten hier maximal 255 Zeichen verwendet werden.
POST
Dient zu Übertragung von Daten an den Server (zum Beispiel Formulardaten). Hiermit können unbegrenzt große Daten übertragen und auch validiert werden. Anfrage wird im "request Body" übermittelt.
HEAD
Mittels eines HEAD Requests wird der Server dazu angewiesen, nur den Header der Daten zu übertragen und nicht wie bei GET mit dem Gesamten Body.
PUT
Dient dazu Daten auf einem Server Upzudaten oder Abzulegen. Findet meist bei APIs Anwendung ist aber bei den normalen Webservern zumeist aus Sicherheitsgründen deaktiviert.
DELETE
Hiermit können Daten auf dem Webserver gelöscht werden. Allerdings ist DELETE wie auch PUT meist nicht Implementiert.
TRACE
Testet das Clientverhalten, in dem es so tut als ob der Webserver die Daten nie erhalten hat. Wird meist zum Debuggen verwendet.
Vergleich GET und POST
| GET |
POST | |
| BACK button/Reload |
kein Problem | Daten werden erneut übermittelt, Browser sollte Meldung ausgeben, dass Daten erneut übermittelt werden |
| Bookmarked (Lesezeichen dieser erstellen) |
geht als Bookmark |
geht nicht als Bookmark |
| Cached |
kann gecached werden |
kann nicht gecachet werden |
| History |
Parameter sind in Browser History |
Parameter werden nicht in der Browser History gespeichert |
| Datenlänge |
Länge der URL ist begrenzt |
keine Begrenzung |
| Datentyp |
nur ASCII Zeichen sind erlaubt |
keine Begrenzung |
| Sicherheit |
weniger sicher wie POST, da Daten in URL übertragen werden Kritisch bei Passwörtern und sensiblen Informationen |
etwas sicherer als GET, da Parameter nicht in der Browser History und den Webserver Logs gespeichert werden (verschlüsselt Übertragung aber nicht) |
| Sichtbarkeit |
Daten sind in URL sichtbar |
Daten werden nicht in der URL gezeigt |
Sortieralgorithmen
Bubblesort
Video - Bubblesort
Beim Bubblesort Algorithmus wird ein Array – also eine Eingabe-Liste – immer paarweise von links nach rechts in einer sogenannten Bubble-Phase durchlaufen. Man startet also mit der ersten Zahl und vergleicht diese dann mit ihrem direkten Nachbarn nach dem Sortierkriterium. Sollten beide Elemente nicht in der richtigen Reihenfolge sein, werden sie ganz einfach miteinander vertauscht. Danach wird direkt das nächste Paar miteinander verglichen, bis die gesamte Liste einmal durchlaufen wurde. Die Phase wird so oft wiederholt, bis der gesamte Array vollständig sortiert ist.
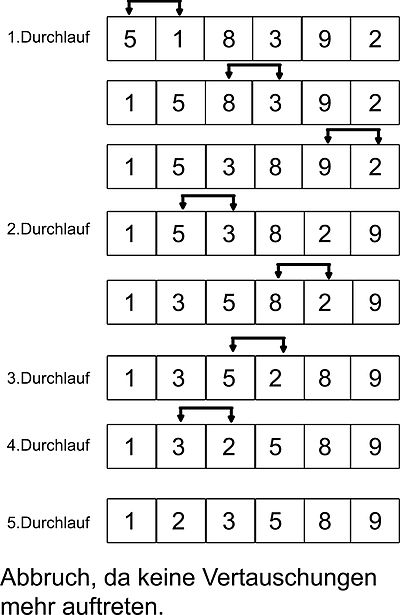
Insertionsort
Video - Insertionsort
Der Insertion Sort gehört in der Informatik zu den stabilen Sortieralgorithmen und kann als Sortieren durch Einfügen beschrieben werden, deswegen auch Einfügesortierenmethode genannt. Das Ganze lässt sich natürlich einfach durch die englischen Wörter insertion = Einfügen und sort = sortieren ableiten, weswegen der Sortieralgorithmus auch manchmal als Insertsort bezeichnet wird. Allgemein kann auch noch gesagt werden, dass der Sortieralgorithmus einfach zu implementieren ist und dabei bei kleiner oder schon teilweise vorsortierten Eingabemengen sehr effizient arbeitet. Da das Sortierverfahren keinen zusätzlichen Speicherplatz benötigt, arbeitet der Algorithmus in-place, was natürlich für seine Speicherplatzkomplexität spricht.
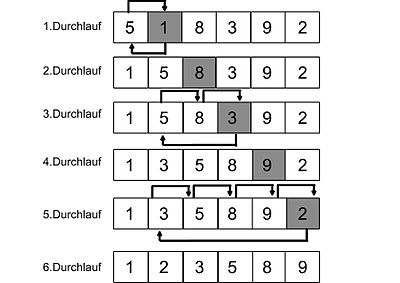
Quicksort
Video - Quicksort
Zunächst wird die zu sortierende Liste in zwei Teillisten („linke“ und „rechte“ Teilliste) getrennt. Dazu wählt Quicksort ein sogenanntes Pivotelement aus der Liste aus. Alle Elemente, die kleiner als das Pivotelement sind, kommen in die linke Teilliste, und alle, die größer sind, in die rechte Teilliste. Die Elemente, die gleich dem Pivotelement sind, können sich beliebig auf die Teillisten verteilen. Nach der Aufteilung sind die Elemente der linken Liste kleiner oder gleich den Elementen der rechten Liste.
Anschließend muss man also noch jede Teilliste in sich sortieren, um die Sortierung zu vollenden. Dazu wird der Quicksort-Algorithmus jeweils auf der linken und auf der rechten Teilliste ausgeführt. Jede Teilliste wird dann wieder in zwei Teillisten aufgeteilt und auf diese jeweils wieder der Quicksort-Algorithmus angewandt, und so weiter. Diese Selbstaufrufe werden als Rekursion bezeichnet. Wenn eine Teilliste der Länge eins oder null auftritt, so ist diese bereits sortiert und es erfolgt der Abbruch der Rekursion.
Die Positionen der Elemente, die gleich dem Pivotelement sind, hängen vom verwendeten Teilungsalgorithmus ab. Sie können sich beliebig auf die Teillisten verteilen. Da sich die Reihenfolge von gleichwertigen Elementen zueinander ändern kann, ist Quicksort im Allgemeinen nicht stabil.
Das Verfahren muss sicherstellen, dass jede der Teillisten mindestens um eins kürzer ist als die Gesamtliste. Dann endet die Rekursion garantiert nach endlich vielen Schritten. Das kann z. B. dadurch erreicht werden, dass das ursprünglich als Pivot gewählte Element auf einen Platz zwischen den Teillisten gesetzt wird und somit zu keiner Teilliste gehört.
Mergesort
Video - Mergesort
Mergesort betrachtet die zu sortierenden Daten als Liste und zerlegt sie in kleinere Listen, die jede für sich sortiert werden. Die kleinen sortierten Listen werden dann im Reißverschlussverfahren zu größeren sortierten Listen zusammengefügt, bis eine sortierte Gesamtliste erreicht ist. Das Verfahren arbeitet bei Arrays in der Regel nicht in-place, es sind dafür aber Implementierungen bekannt, in welchen die Teil-Arrays üblicherweise rekursiv zusammengeführt werden. Verkettete Listen sind besonders geeignet zur Implementierung von Mergesort, dabei ergibt sich die in-place-Sortierung fast von selbst.
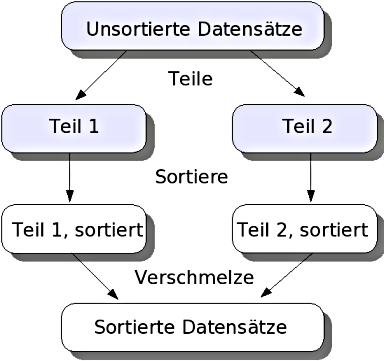
Polymorphismus & Überladen
Polymorphismus
Bei Polymorphismus gibt es eine Basisklasse, von der mehrere Klassen erben. Innerhalb der Basisklasse ist eine Methode deklariert, welche aufgrund der Vererbung in den Unterklassen implementiert werden muss. Wird nun ein Objekt einer der Unterklassen erstellt und mit diesem Objekt die Methode aus der Basisklasse aufgerufen, kann das Programm anhand der Klasse, von welcher das Objekt erstellt wurde, entscheiden, welche der Implementierungen aufgerufen wird.
Überladen
Beim Überladen wird dem gleichen Operator, Literal, usw. eine unterschiedliche Bedeutung zugeordnet. Die Bedeutung geht aus dem Kontext hervor.
a = 1 + 2
b = "abc" + "def"Bei diesem Beispiel wird der Operator "+" überladen. Je nach Kontext handelt es sich dabei um eine Stringconcatination oder um eine Addition von zwei Integern.
Programmierparadigmen
Imperative Programmierung
Die imperative Programmierung (von lateinisch imperare = befehlen) ist das älteste Programmierparadigma. Gemäß diesem Paradigma besteht ein Programm aus einer klar definierten Abfolge von Handlungsanweisungen an einen Computer.
Der Quellcode imperativer Sprachen reiht also Befehle aneinander, die festlegen, was wann vom Computer zu tun ist, um ein gewünschtes Ergebnis zu erzielen. In Variablen eingesetzte Werte werden dabei zur Laufzeit des Programms verändert. Um die Befehle zu steuern, werden Kontrollstrukturen wie Schleifen oder Verzweigungen in den Code integriert.
Strukturierte Programmierung
Beim strukturierten Programmierungsansatz handelt es sich um eine vereinfachte Form der imperativen Programmierung. Die entscheidende Änderung zum Grundprinzip: Anstelle der absoluten Sprungbefehle (Anweisungen, die dazu führen, dass die Verarbeitung nicht mit dem nachfolgenden Befehl, sondern an anderer Stelle weitergeführt wird) sieht dieses Paradigma für die Software-Programmierung den Einsatz von Kontrollschleifen bzw. -strukturen vor.
Ein Beispiel hierfür ist die Nutzung von „do…while“, um eine Anweisung automatisch so lange auszuführen, wie eine bestimmte Bedingung wahr ist (mindestens ein Mal).
Populäre Vertreter sind C und C++, C#, COBOL, Fortran, Java, Pascal, Python oder auch Visual Basic.
Prozedurale Programmierung
Das prozedurale Programmierparadigma erweitert den imperativen Ansatz um die Möglichkeit, Algorithmen in überschaubare Teile aufzugliedern. Diese werden als Prozeduren oder – je nach Programmiersprache – auch als Unterprogramme, Routinen oder Funktionen bezeichnet.
Sinn und Zweck dieser Aufteilung ist es, den Programmcode übersichtlicher zu machen und unnötige Code-Wiederholungen zu vermeiden. Durch die Abstraktion der Algorithmen stellt das prozedurale Software-Paradigma einen entscheidenden Schritt von einfachen Assemblersprachen hin zu komplexeren Hochsprachen dar.
Beispiele für typische prozedurale Programmiersprachen sind C und Pascal.
Objektorientierte Programmierung
Objektorientierte Programmierung (OOP) ist ein Modell der Computerprogrammierung, bei dem das Softwaredesign auf Daten oder Objekten basiert und nicht auf Funktionen und Logik. Ein Objekt kann als ein Datenfeld definiert werden, das eindeutige Attribute und Verhaltensweisen aufweist.
Die Struktur beziehungsweise die Bausteine der objektorientierten Programmierung umfassen:
- Klassen sind benutzerdefinierte Datentypen, die als Blaupause für individuelle Objekte, Attribute und Methoden dienen.
- Objekte sind Instanzen einer Klasse, die mit speziell definierten Daten erstellt werden. Objekte können realen Objekten oder einem abstrakten Gebilde entsprechen. Bei der anfänglichen Definition einer Klasse ist die Beschreibung das einzige Objekt, das definiert wird.
- Methoden sind Funktionen, die innerhalb einer Klasse definiert sind und das Verhalten eines Objekts beschreiben.
- Attribute werden in der Klassenvorlage definiert und stellen den Zustand eines Objekts dar. Objekte haben Daten, die im Attributfeld gespeichert werden. Klassenattribute gehören zur Klasse selbst.
Zu den Programmiersprachen, die hauptsächlich für die objektorientierter Programmierung entwickelt wurden, gehören Java, Python und C++
Deklarative Programmierung
Kennzeichnend für die deklarativen Programmiersprachen ist, dass sie immer ein gewünschtes Endergebnis beschreiben, statt alle Arbeitsschritte aufzuzeigen. Um das Ziel zu erreichen, wird bei der deklarativen Programmierung der Lösungsweg automatisch ermittelt. Dies funktioniert so lange gut, wie die Spezifikationen des Endzustands klar definiert sind und ein passendes Ausführungsverfahren existiert. Trifft beides zu, ist die deklarative Programmierung sehr effizient.
Da die deklarative Programmierung das „Wie“ nicht festschreibt, sondern auf einem sehr hohen Abstraktionsniveau arbeitet, lässt das Programmierparadigma zudem Raum für Optimierung. Wird ein besseres Ausführungsverfahren entwickelt, lässt sich dies über den integrierten Algorithmus auffinden und verwenden. Auf diese Weise ist das Paradigma sehr zukunftssicher: Beim Schreiben des Codes muss das Verfahren, wie das Ergebnis zu erreichen ist, nicht feststehen.
Logische Programmierung
Das logische Software-Paradigma, das auch als prädikative Programmierung bezeichnet wird, beruht auf der mathematischen Logik. Anstelle einer Folge von Anweisungen enthält eine Software, die nach diesem Prinzip programmiert wird, eine Menge von Grundsätzen, die sich als Sammlung von Fakten und Annahmen verstehen lässt. Jegliche Anfragen an das Programm werden verarbeitet, indem der Interpreter auf diese Grundsätze zurückgreift und zuvor definierte Regeln auf diese anwendet, um zum gewünschten Ergebnis zu kommen.
Einer der wichtigsten Vertreter der logischen Programmierung ist die Programmiersprache Prolog.
Funktionale Programmierung
Im Mittelpunkt der funktionalen Herangehensweise beim Programmieren stehen Funktionen. Bei einem funktionalen Programm können alle Elemente als Funktion aufgefasst und der Code kann durch aneinandergereihte Funktionsaufrufe ausgeführt werden. Im Umkehrschluss gibt es keine eigenständigen Zuweisungen von Werten.
Zu den wichtigsten Programmiersprachen, die auf dem funktionalen Ansatz basieren, zählen LISP, Haskell, F# oder Erlang
CSS - Cascading Style Sheet
Definition von CSS
CSS (Cascading Style Sheet) ist eine Möglichkeit das Aussehen von HTML-Elementen zu beeinflussen. Also die Schriftart, -größe, -farbe, die Umrandung, sowie den Abstand zwischen den einzelnen Elementen und zur Umrandung.
Es gibt drei Möglichkeiten in denen man speichern kann wie die einzelnen Elemente dargestellt werden sollen:
- externe CSS-Datei
- im "head" eines HTML-Files
- direkt im Attribut
Dabei gibt es zwei Grundsätze zu beachten:
- möglichst viele über die externe CSS-Datei anpassen, dass erleichtert spätere Veränderungen
- je dichter am Element eine Anpassung ist, desto höher die Priorität bei der Darstellung
Box-Modell

- Content: Inhalt der Box, hier erscheinen Text und Bilder (height, width)
- Padding: Klärt ein Gebiet um den "content" herum und erscheint transparent (top, right, bottom, left)
- Border: Rahmen um Content und Padding, ist sichtbar und kann verändert werden (size)
- Margin: Klärt ein Gebiet um die "border" herum und erscheint transparent (top, right, bottom, left)
Bei zwei benachbarten Elementen gilt die größere Margin. Sollte das eine Element eine margin von 20px und das andere Element eine margin von 30px haben, dann haben die beiden border einen Abstand von 30px (nicht 50px).
Entity-Relationship-Modell
Entity-Relationship-Modell (kurz: ER-Modell oder ERM)
- Modell zur Darstellung von Dingen, Gegenständen und Objekten, sowie deren Beziehung und Zusammenhänge
- Begriffe:
- Entiät (Entity): individuell identifizierbares Objekt der Wirklichkeit (Gegenstand, Ding, Objekt)
- Beziehung (Relationship): Verknüpfung / Zusammenhang zwischen zwei oder mehr Entitäten
- Eigenschaften (Attribut): Was über eine Entität im Kontext wichtig ist
- es gibt unterschiedliche Notationen (=Darstellungsformen) für ein ER-Modell. In der Berufsschule wurden die Chen-Notation und die Krähenfuß-Notation verwendet
- verwendete Symbole:
 |
 |
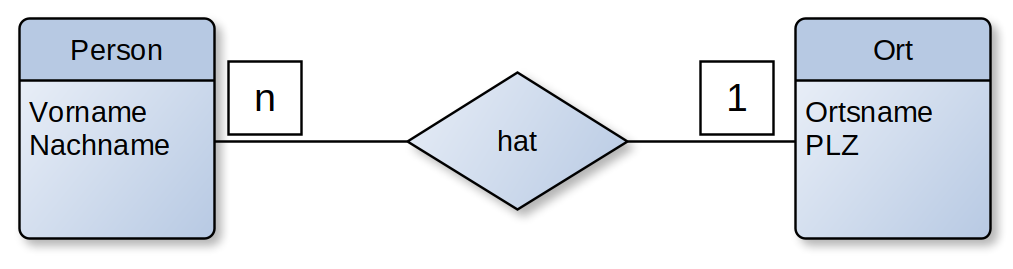 |
Chen-Notation
| 1:1 |
Jede Entität der ersten Tabelle steht mit genau einer Entiät der zweiten Tabelle in Beziehung. Jede Entität der zweiten Tabelle steht mit genau einer Entität der ersten Tabelle in Beziehung. |
| 1:n |
Jede Entiät der ersten Tabelle steht mit mindestens einer Entität der zweiten Tabelle in Beziehung. Jede Entität der zweiten Tabelle steht mit genau einer Entität der ersten Tabelle in Beziehung. |
| n:m |
Jede Entiät der ersten Tabelle steht mit mindestens einer Entität der zweiten Tabelle in Beziehung. Jede Entiät der zweiten Tabelle steht mit mindestens einer Entität der ersten Tabelle in Beziehung. Eine solche Beziehung ist nur im ER-Modell darstellbar und muss bei der Umwandlung für die Datenbank aufgelöst werden. Dazu wird eine dritte Tabelle geschaffen, die die Primary Keys der beiden ursprünglichen Tabellen enthält. Die neue Tabelle steht mit den alten Tabellen in einer 1:n Beziehung. |
Auflösen einer n:m Beziehung
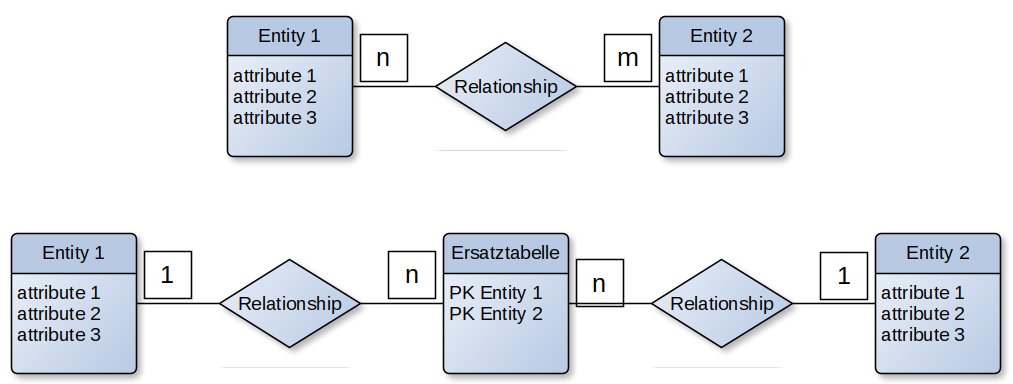
Erweiterte Chen-Notation
- in der erweiterten Chen-Notation wird der Buchstabe "c" eingeführt. Dieser kann für "0" oder "1" stehen
- Kombinationen sind mit allen oben genannten Beziehungen möglich
Krähenfuß-Notation / Martin-Notation
- in dieser Notation werden vier unterschiedliche Symbole verwendet um die Beziehung von einer Tabelle zur anderen darzustellen
| Symbolik |
Bedeutung |
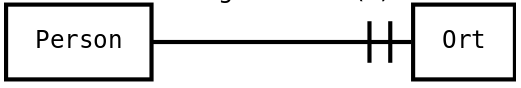 |
Person hat genau eine Beziehung zu Ort |
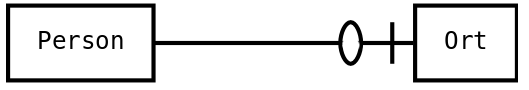 |
Person hat maximal eine Beziehung zu Ort |
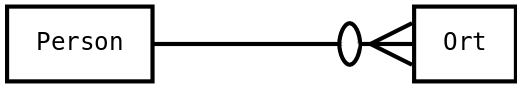 |
Person hat beliebig viele Beziehung zu Ort |
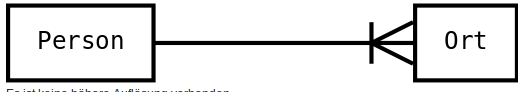 |
Person hat mindestens eine Beziehung zur Ort |
BWL
Abschlussprüfung Teil 2
Angebotsvergleich
Vergleich von Angeboten verschiedener Lieferanten, Unternehmen und Läden, von denen Leistungen in Form von Produkten oder Dienstleistungen bezogen werden
Ziel: Bestimmung des günstigsten Lieferanten
Faktoren:
- Transport- und Verpackungskosten
- Rabatte, Boni, Skonti, Sonderangebote
- Lieferzeiten bzw. Lieferfristen
- Verhandlungsmöglichkeiten
Quantitativer Angebotsvergleich: Preisvergleich
- anhand von Listeneinkaufspreis, Preisnachlässen, Bezugskosten
- Preisbestimmung gleich wie bei Handelskalkulation vorwärts, bis Bezugspreis
Qualitativer Angebotsvergleich:
- weiche Kriterien, die jedes Unternehmen für sich selbst bestimmt
- z. B. Service, Garantie, Verbrauch, …
- Beispiel für einen qualitativen Angebotsvergleich
Angebot 1 schneidet beim qualitativen Angebotsvergleich besser ab und sollte deswegen genommen werden.Kriterien Gewichtung Angebot 1 Angebot 2 Punkte gewichtete
PunkteGründe Punkte gewichtete
PunkteGründe Preis 35 2 70 billiger 1 35 teurer Lieferzeit 20 1 20 6 Wochen 2 40 2 Wochen Garantie 25 2 50 3 Jahre 1 25 2 Jahre CO2-Bilanz 20 1 20 höher 2 40 niedriger Summe 100 160 140
Lieferantenbewertungstabelle:
- Tabelle, in der quantitative und qualitative Kriterien gewichtet und bewertet werden. Auf Basis dieser Gewichtung folgt Entscheidung.
Handelskalkulation
Allgemein
| von Hundert | (Wert / 100) * Prozent |
| in Hundert | (Wert / (100 – Prozent)) * Prozent |
| auf Hundert | (Wert / (100 + Prozent)) * Prozent |
Vorwärtskalkulation
Ziel: Bestimmen zu welchem Preis man ein Produkt verkaufen kann
Gegeben ist der Einkaufspreis und man bestimmt den Verkaufspreis
| Schritt | in % | Wert | Berechnung | |
|---|---|---|---|---|
| Einkaufspreis (brutto) | 1,785.00 | |||
| - MwSt. | 19 | 285.00 | ((Preis(brutto) / (100 + MwSt)) * MwSt | auf Hundert |
| Einkaufspreis (netto) | 1,500.00 | |||
| - Lieferrabatt | 10 | 150.00 | (Einkaufspreis / 100) * Lieferrabett | von Hundert |
| Zieleinkaufspreis | 1,350.00 | |||
| - Lieferskonto | 2 | 27.00 | (Zieleinkaufspreis / 100) * Lieferskonto | von Hundert |
| Bareinkaufspreis | 1,323.00 | |||
| + Bezugskosten | 50.00 | |||
| Bezugspreis | 1,373.00 | |||
| + Handlungskosten | 20 | 274.60 | von Hundert | |
| Selbstkosten | 1,647.60 | |||
| + Gewinn | 20 | 329.52 | (Selbskosten / 100) * Gewinn | von Hundert |
| Barverkaufspreis | 1,977.12 | |||
| + Kundenskonto | 2 | 40.35 | (Barverkaufspreis / (100 – Kundenskonto)) * Kundenskonto | in Hundert |
| Zielverkaufspreis | 2,017.47 | |||
| + Kundenrabatt | 15 | 356.02 | (Zielverkaufspreis / (100 – Kundenrabatt)) * Kundenrabatt | in Hundert |
| Verkaufspreis (netto) | 2,373.49 | |||
| + MwSt. | 19 | 450.96 | ((Verkaufspreis(netto) / 100) * MwSt | von Hundert |
| Verkaufspreis (brutto) | 2,824.46 |
Rückwärtskalkulation
Ziel: Bestimmen zu welchem Preis wir ein Produkt einkaufen müssen
Gegeben ist der Verkaufspreis und man bestimmt den Einkaufspreis
| in % | Wert | Berechnung | ||
|---|---|---|---|---|
| Verkaufspreis(brutto) | 2,618.00 | |||
| - MwSt. | 19 | 418.00 | ((Verkaufspreis(brutto) / (100 + MwSt)) * MwSt | auf Hundert |
| Verkaufspreis(netto) | 2,200.00 | |||
| - Kundenrabatt | 15 | 330.00 | (Verkaufspreis(netto) / 100) * MwSt | von Hundert |
| Zielverkaufspreis | 1,870.00 | |||
| - Kundenskonto | 2 | 37.40 | (Zielverkaufspreis / 100) * Kundenskonto | von Hundert |
| Barverkaufspreis | 1,832.60 | |||
| - Gewinn | 20 | 305.43 | ((Barverkaufspreis / (100 + Gewinn)) * Gewinn | auf Hundert |
| Selbstkosten | 1,527.17 | |||
| - Handlungskosten | 20 | 254.53 | ((Selbstkosten / (100 + Handlungskosten)) * Handlungskosten | auf Hundert |
| Bezugspreis | 1,272.64 | |||
| - Bezugskosten | 50.00 | |||
| Bareinkaufspreis | 1,222.64 | |||
| + Lieferskonto | 2 | 24.95 | ((Bareinkaufspreis / (100 – Lieferskonto)) * Lieferskonto | in Hundert |
| Zieleinkaufspreis | 1,247.59 | |||
| + Lieferrabatt | 10 | 138.62 | ((Zieleinkaufspreis / (100 – Lieferrabatt)) * Lieferrabatt | in Hundert |
| Einkaufspreis(netto) | 1,386.21 | |||
| + MwSt. | 19 | 263.38 | (Einkaufspreis(netto) / 100) * MwSt | von Hundert |
| Einkaufspreis(brutto) | 1649.59 |
Differenzkalkulation
Ziel: Berechnung von Gewinn in Euro und Prozent(%)
Gegeben ist Einkaufspreis und Verkaufspreis
| Schritt | in % | Wert | Berechnung | |
|---|---|---|---|---|
| Einkaufspreis(brutto) | 1,725.50 | |||
| - MwSt | 19 | 275.50 | ((Preis(brutto) / (100 + MwSt)) * MwSt | auf Hundert |
| Einkaufspreis(netto) | 1,450.00 | |||
| - Lieferrabatt | 10 | 145.00 | (Einkaufspreis / 100) * Lieferrabett | von Hundert |
| Zieleinkaufspreis | 1,305.00 | |||
| - Lieferskonto | 2 | 26.10 | (Zieleinkaufspreis / 100) * Lieferskonto | von Hundert |
| Bareinkaufspreis | 1,278.90 | |||
| + Bezugskosten | 50.00 | |||
| Bezugspreis | 1,328.90 | |||
| + Handlungskosten | 20 | 265.78 | von Hundert | |
| Selbstkosten | 1,594.68 | |||
|
+ Gewinn |
14.92 | 237.92 |
Wert = Barverkaufspreis - Selbstkosten Prozent = (Wert * 100) / Selbskosten |
|
| Barverkaufspreis | 1,832.60 | |||
| + Kundenskonto | 2 | 37.40 | (Zielverkaufspreis / 100) * Kundenskonto |
von Hundert |
| Zielverkaufspreis | 1,870.00 | |||
| + Kundenrabatt | 15 | 330.00 | (Verkaufspreis(netto) / 100) * Kundenrabatt | von Hundert |
| Verkaufspreis(netto) | 2,200.00 | |||
| + MwSt | 19 | 418.00 | (Verkaufspreis(brutto) / (100 + MwSt)) * MwSt | auf Hundert |
| Verkaufspreis(brutto) | 2,618.00 |
Eigenproduktion
| in % | Wert | Berechnung | ||
|---|---|---|---|---|
| Materialeinzelkosten | 14.77 | |||
| + Materialgemeinkosten 6,5 % | 6,5 % | 0.96 | (Materialeinzelkosten / 100) * Materialgemeinkosten | von Hundert |
| = Materialkosten | 15.73 | |||
| + Fertigungslöhne | 20.42 | |||
| + Fertigungsgemeinkosten | 150 % | 30,63 | (Fertigungslöhne / 100) * Fertigungsgemeinkosten | von Hundert |
| + Sondereinzelkosten Fertigung | 12.55 | |||
| = Fertigungskosten | 63.60 | |||
| = Herstellkosten | 79.33 | Materialkosten + Fertigungskosten | ||
| + Verwaltungsgemeinkosten | 17,4 % | 13.80 | (Herstellkosten / 100) * Verwaltungsgemeinkosten | von Hundert |
| + Vertriebsgemeinkosten | 8 % | 6.35 | (Herstellkosten / 100) * Vertriebsgemeinkosten | von Hundert |
| = Selbstkosten | 99.48 | |||
| + Gewinn | 11 % | 10,94 | (Selbskosten / 100) * Gewinn | von Hundert |
| = Barverkaufspreis | 110.43 | |||
| + Kundenskonto | 3 % | 3.42 | (Barverkaufspreis / (100 – Kundenskonto)) * Kundenskonto | in Hundert |
| = Zielverkaufspreis | 113.85 | |||
| + Kundenrabatt | 10 % | 12.65 | (Zielverkaufspreis / (100 – Kundenrabatt)) * Kundenrabatt | in Hundert |
| = Netto-Listenverkaufspreis | 126.50 |
Break-Even-Point / Gewinnschwelle
- Punkt ab dem der Gesamtumsatz die Gesamtkosten deckt
- Grundsätzliche Fragen:
- Wie viele Teile von einem Produkt müssen produziert und abgesetzt werden, damit die Kosten gedeckt sind?
- Wie viel Umsatz muss gemacht werden, um die Kosten zu decken?
- Berechnungsarten
Grafische Bestimmung |
|
|
E = Erlöse Kg = Gesamtkosten (variable Kosten + fixe Kosten) Kv = variable Kosten Kf = fixe Kosten |
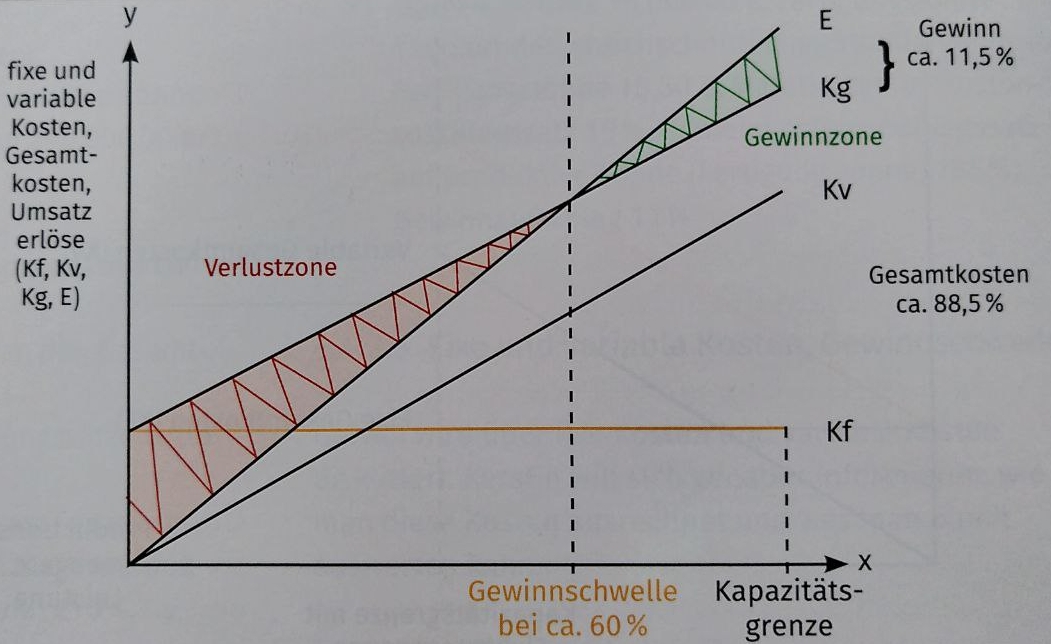 |
algebraische Bestimmung
|
|
|
E = Erlöse Kg = Gesamtkosten e = Erlöse pro Stück Kf = fixe Kosten kv = variable Stückkosten x = Stückzahl |
E = Kg x * e = Kf + x * kv | - (x * kv) (x * e) - (x * kv) = Kf x * (e - kv) = Kf x = Kf / (e - kv) |
EPK's
Wozu dient eine EPK
Bei einer EPK handelt es sich um eine Ereignissgesteuerte Prozesskette, bedeutet Geschäftsprozesse werden grafisch dargestellt um Sie zu optimieren und kosten zu sparen. Hierzu wird der Geschäftsprozess in seine einzelnen Vorgänge aufgeteilt und gezeichnet. Bei der Erstellung von EPKs sind folgende Regeln und Darstellungen zu beachten:

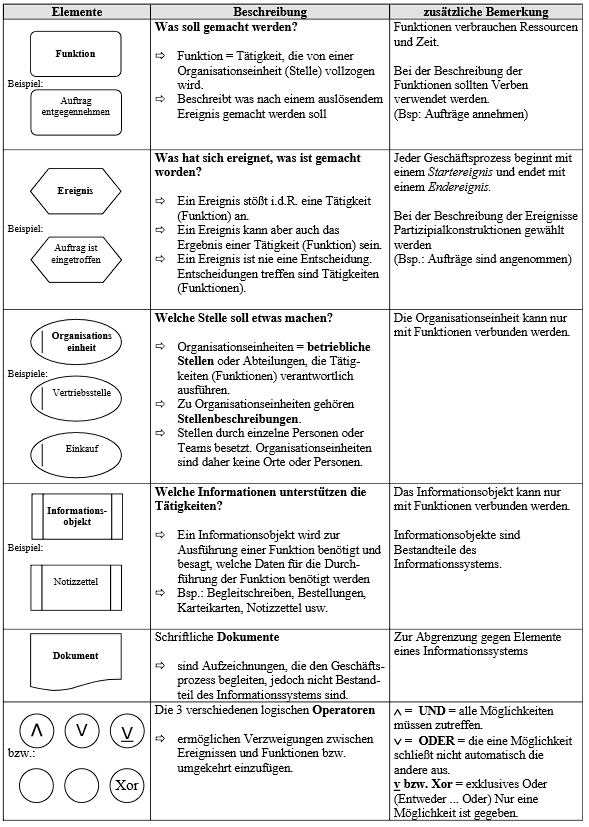
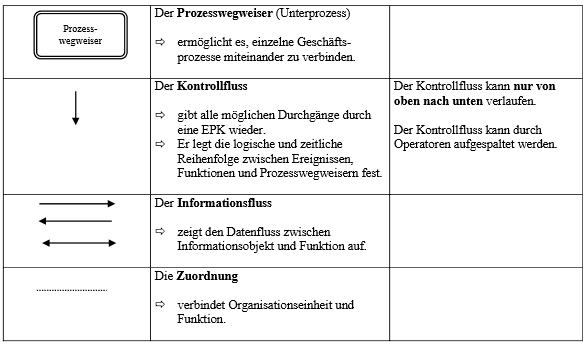
Beispiel einer EPK
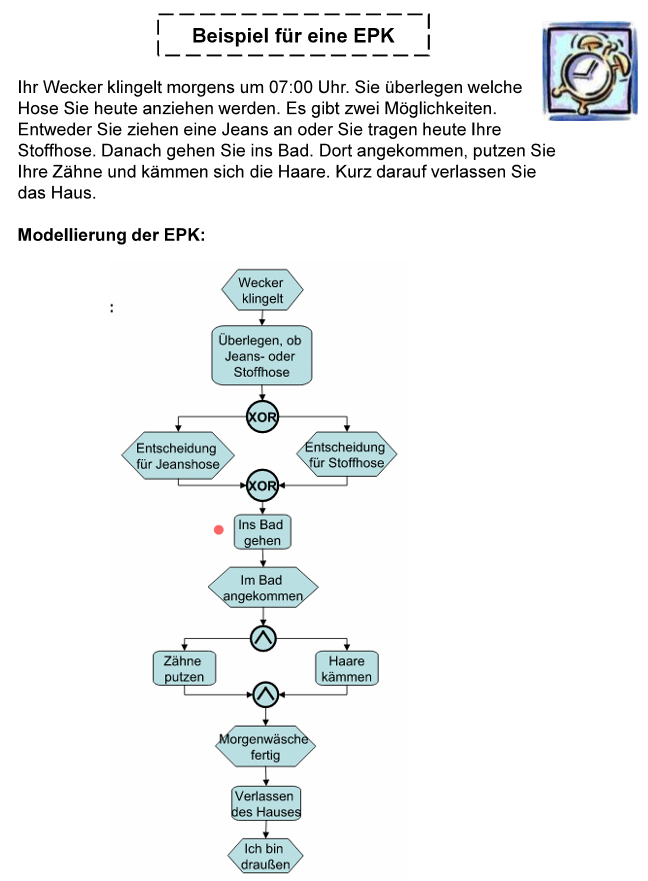
Bilanzen
Was ist eine Bilanz:
In einer Bilanz wird das Kapital (Passiva) und das Vermögen (Aktiva) zu einem bestimmten Zeitpunkt gegenübergestellt. Hierbei muss aktiv und passiv immer der genau selben Summe entsprechen.
Wozu dient eine Bilanz:
Mit Hilfe einer Bilanz kann eine Übersicht über das Vermögen mit all seinen Bestandteilen und des Kapitals mit seiner Herkunft eines Unternehmens dargestellt werden. Des weiteren wird eine Bilanz vom Finanzamt gefordert.
Bestandteile einer Bilanz:
Vermögensseite (aktiv):
Hier steht unter anderem das Anlagevermögen als erstes: Darunter sind alle Dinge zu verstehen, die längere Zeit im Unternehmen verbleiben sollen wie z.B. Grundstücke, Maschinen, Lizenzen oder auch Wertpapiere.
Umlaufvermögen: Vorräte, Guthaben auf Bankkonten, Kassenguthaben, Forderungen, Schecks.
Kapitalseite (passiv):
Eigenkapital:
- Gekennzeichnetes Kapital = Kapitaleinlagen von Gesellschaftern bei Gründung
- Kapitalrücklagen = Finanzielle Reserven die gesetzlich vorgeschrieben sind. Werden vorrangig durch Aktienausgaben gebildet.
- Gewinnrücklagen = Finanzielle Reserven, die aus einem Teil des jährlichen Gewinns einbehalten werden.
- Gewinn- Verlust-Vortrag = Restgewinn aus dem Vorjahr der übriggeblieben ist. Selbes für Verlust.
- Jahresüberschuss / Fehlbetrag = Gewinn nach Abzug aller Steuern oder Verlust.
Fremdkapital:
- Bei der Ausgabe von Anleihen leiht der Käufer dem Unternehmen Kapital. Dem Unternehmen entstehen somit Verbindlichkeiten durch den Verkauf von Wertpapieren.
- Erhaltene Anzahlungen entstehen, wenn ein Kunde einen Teil der Rechnungssumme vor der Lieferung oder Leistungserbringung begleicht.
- Verbindlichkeiten gegenüber Kreditinstituten entstehen durch die Aufnahme von Darlehen, Lieferantenkrediten oder Obligationen.
- Verbindlichkeiten aus Lieferungen und Leistungen sind finanzielle Verpflichtungen des Unternehmens gegenüber Lieferanten, deren offene Rechnungen noch nicht beglichen wurden.
- Sonstige Verbindlichkeiten, das sind z. B. Sozialversicherungsbeiträge.
Gesamtkapital: Ist das Eigenkapital - Fremdkapital
Anleitung (am Beispiel der Übungsaufgabe von Frau Danilovic):
- Bilden von Aktiva und Passiva
- Aktiva: Positionen die im Besitz sind (z.B. Grundstücke, Geschäftsausstattung, Kasse und Bank)
- Passive: Schulden und Eigenkapital (z.B. Verbindlichkeiten, Darlehen, Hypotheken)
Eigenkapital = Summe(Aktiva) - Summe(Passiva)
- Bilden von Buchungsätzen: Es gilt dabei immer Passiva an Aktiva
- Bilden von T-Konten:
- Aktiva haben Anfangsbestand im SOLL
- Passiva haben Anfangsbestand im HABEN
- Durchführen der Buchungssätze:
- Buchungssätze sind wie folgt zu lesen SOLL [Betrag] an HABEN [Betrag]
- Betrag wird beim Passivkonto in SOLL eingetragen und beim Aktivkontokonto in HABEN
- Verrechnung: Schlussbestand = Anfangsbestand - Buchung (in SOLL oder HABEN)
Wichtig: Bilanz muss ausgeglichen sein! - Schlussbilanz: Verrechnen von allen Aktiv- und Passivkonten
Einfacher Buchungssatz
Grundlagen
- Jeder Geschäftsvorfall erzeugt mindestens eine Soll-Buchung und eine Haben-Buchung.
- Der Buchungssatz gibt an, auf welchen Konten ein Geschäftsvorfall im Soll und im Haben zu buchen ist
Regeln
- Welche Konten beeinflusst der Geschäftsvorfall?
- Was für Konten sind das? Aktivkonten, Passivkonten
- Liegt auf dem entsprechenden Konto eine Mehrung oder Minderung vor?
- Ermitteln, auf welcher Seite des Kontos (Soll oder Haben) zu buchen ist!
- Bilden Sie den Buchungssatz! Zuerst wird das Soll-Konto genannt und das Haben-Konto zuletzt. Verbunden werden die beiden Konten mit „an“
Wichtig: Das Wort „an“ hat keine weitere Bedeutung und stellt im Sinne der Wortlogik keine Richtungsangabe dar.
Bsp: Bank an Kasse bedeutet nämlich nicht, das Geld auf die Kasse eingezahlt wird. Bank im Soll und Kasse im Haben gebucht bedeutet, das die Bank zunimmt und der Kassenbestand abnimmt.
Der einfache Buchungssatz
Ein Buchungssatz, bei dem nur zwei Konten betroffen sind, wird als einfacher Buchungssatz bezeichnet
|
Geschäftsvorfall |
Abarbeitung der obigen 5 Regeln zum Buchungssatz |
|
Ein Kunde begleicht unsere Forderung über 1000 € durch Banküberweisung |
|
|
Wir bezahlen unsere Verbindlichkeiten an einen Lieferanten über 1000 € durch Banküberweisungen |
|
Lineare Abschreibungen
Bei der linearen oder auch planmäßigen Abschreibung wird ein Zeitraum festgelegt, über welchen ein Wirtschaftsgut in gleichbleibenden Abständen wertverlust erfährt und abgeschrieben wird.
Die lineare Abschreibung ist die am häufigsten angewandte Abschreibungsmethode. Sie geht davon aus, dass die Abnutzung bzw. der Wertverlust konstant über die Jahre ist. Im Jahr der Anschaffung bzw. Herstellung ist eine zeitanteilige Abschreibung auf Monatsbasis vorzunehmen.
Abschreibungsbetrag = Anschaffungskosten / Nutzungsdauer.
Der Abschreibungsaufwand wird gleichmäßig über die Jahre verteilt — allerdings nehmen die Gesamtkosten des Anlageguts in der Regel über die Laufzeit aufgrund steigender Wartungs- und Reparaturkosten zu.
Beispiel für lineare Abschreibung
Ihr Unternehmen schafft zum 1. Januar 2022 eine Workstation im Wert von netto (d. h. ohne Umsatzsteuer) 3000 € an.
Diese 3000 € stellen die Anschaffungskosten des Anlagevermögens und somit die Abschreibungsbasis dar.
Die Nutzungsdauer der Workstation beträgt 5 Jahre.
Die lineare Abschreibung pro Jahr lässt sich mit folgender Formel berechnen:
Abschreibungsbetrag = Anschaffungskosten / Nutzungsdauer = 3000 € / 5 Jahre = 600 € pro Jahr.
Der Abschreibungsverlauf stellt sich wie folgt dar:
| 2022 | 2023 | 2024 | 2025 | 2026 | |
| Buchwert zum 1. Januar des Geschäftsjahres | 3000,00 € | 2400,00 € | 1800,00 € | 1200,00 € | 600,00 € |
| Abschreibung im Geschäftsjahr | 600,00 € | 600,00 € | 600,00 € | 600,00 € | 600,00 € |
| Buchwert zum 31. Dezember des Geschäftsjahres | 2400,00 € | 1800,00 € | 1200,00 € | 600,00 € | 0,00 € |
Am Ende des 5. Jahres der Nutzung – zum 31. Dezember 2026 – ist die Maschine vollständig auf 0 abgeschrieben.
Erinnerungswert 1 Euro.
Oftmals wird nicht auf 0 € abgeschrieben, sondern auf einen sogenannten Erinnerungswert bzw. Merkposten von 1 €.
Damit wird deutlich gemacht, dass der Vermögensgegenstand sich noch im Anlagevermögen befindet, aber bereits vollständig abgeschrieben ist. Eine Ausbuchung erfolgt dann bei Abgang des Anlageguts durch Veräußerung oder Verschrottung (wenn der Vermögenswert also wirklich nicht mehr da ist).
Bestellverfahren
Bestellpunktverfahren
Verfahren, um den Lagerbestand zu wahren. Bestellung wird beim Meldebestand oder am Bestellpunkt ausgelöst.
- Begriffe:
- Meldebestand: Lagerbestand, an dem eine Bestellung ausgelöst wird
- Mindestbestand: Menge, die nie unterschritten werden darf
- Bestellmenge: Menge, die zum Bestellzeitpunkt bestellt werden soll
- Vorteile:
- niedrigere Lagerkosten (als beim Bestellrhythmusverfahren)
- schnelle Reaktion auf sinkenden Bestand
- Mindestbestand kann niedriger gehalten werden, da Meldebestand ausschlaggebend für die Bestellung ist
- Nachteile:
- höhere Personalkosten, da Bestände kontrolliert werden müssen
- nicht sinnvoll beim schwankendem Verbrauch, da dieser nicht eingeschätzt werden kann
- Rechnung
- Bestellpunkt-Losgrößen-Verfahren (s,q-Politik): zuvor festgelegte Menge (q = optimale Bestellmenge) wird bestellt, wenn Meldebestand (s) erreicht
- Bestellpunkt-Lagerniveau-Verfahren(s,S-Politik): Lager wird beim Erreichen des Meldebestands (s) auf den ursprünglichen Sollbestand (S) aufgefüllt
Bestellrhythmusverfahren
Verbrauchsorientiertes Verfahren. Hierbei handelt es sich um eine terminbezogene Bestellauslösung, bei der innerhalb konstanter Zeitintervalle eine Bestellung vorgenommen wird, wobei die Bestellmenge entweder fix vorgegeben ist oder variiert. Nach Ablauf des festen Bestellintervalls wird in jedem Fall nachbestellt, sofern eine Lagerbewegung stattgefunden hat.
Anwendung
- wenn der Lieferrhythmus durch den Lieferanten vorgegeben ist.
- wenn der Fertigungsrhythmus des Unternehmens eine Bestellung fehlender Materialien nur zu bestimmten vorhergesagten Perioden zulässt.
Vergleich mit Bestellpunktverfahren
- Vorteilhaft gegenüber dem Bestellpunktverfahren ist, dass eher Sammelbestellungen für gleichartige Materialien gebildet werden können, für die unter Umständen bessere Konditionen erzielt werden können. Ein weiterer Vorteil liegt im geringeren Kontrollaufwand, da während des Bestellintervalls keine Vorratsprüfungen vorgenommen werden.
- Nachteilig ist, dass der Verbrauch in der Zeit zwischen zwei Überprüfungsterminen zusätzlich zum Verbrauch während der Wiederbeschaffungszeit zu überbrücken ist und der Lagerbestand erhöht werden muss.
Projektmanagement - Magisches Dreieck und Methoden
Magisches Dreieck
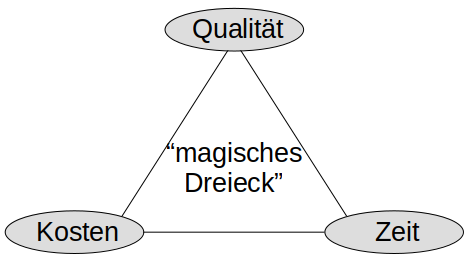
- verdeutlicht, dass Kosten, Zeit und Qualität nicht unabhängig sind
- die drei Faktoren beeinflussen sich gegenseitig
- wesentlichen Faktoren für den Erfolg eines Projekts
Projektmethoden
| Konventionelle (sequenzielle) Methoden |
Agile (flexible) Methoden |
Entwicklungsmethode |
Entwicklungsphilosophie |
|
Wasserfallmodell V-Modell Rational Unified Process |
Scrum Agile Unified Process Extreme Programming |
Prototyping Testgetriebene Entwicklung Modellgetriebene Entwicklung |
Kanban |
WI
Abschlussprüfung Teil 2
1 - Die Rolle des Mitarbeiters in der Arbeitswelt aktiv ausüben
Konzept der dualen Berufsausbildung (Lernorte, Beteiligte)
Für den Zugang zur Ausbildung im dualen System bestehen formal keine Zugangsvoraussetzungen; die Ausbildung im dualen System steht grundsätzlich allen offen. Die Mehrzahl der Auszubildenden verfügt bei Ausbildungseintritt jedoch über den mittleren Schulabschluss oder sogar über eine Hochschulzugangsberechtigung.
Das System wird als dual bezeichnet, weil die Ausbildung an zwei Lernorten stattfindet: im Betrieb und in der Berufsschule. Die Berufsausbildung hat zum Ziel, die notwendigen Kompetenzen und Qualifikationen für die Ausübung einer qualifizierten Tätigkeit in einer sich wandelnden Arbeitswelt zu vermitteln.
Rechte & Pflichten des Ausbildungsvertrages
Die wichtigsten Rechte, die du als Azubi unbedingt kennen solltest:
- Recht auf einen Ausbildungsvertrag
- Recht auf Einhaltung des Ausbildungsziels
- Recht auf einen geeigneten Ausbilder
- Recht auf Ausbildungsmittel
- Recht auf Vergütung
- Rechtliches zu Arbeitszeiten, Pausenzeiten, Überstunden & Minusstunden
- Recht auf Urlaub
- Recht, in der Ausbildung krank zu sein
- Recht auf ein Ausbildungszeugnis
- Recht auf Verkürzung der Ausbildung
- Kündigungsrecht
Wenn du eine Ausbildung machst, dann gibt es bestimmte allgemeine Pflichten, die von dir immer eingehalten werden sollten. Zusätzlich sind folgende Punkte interessant:
-
Allgemeine Pflichten
-
Berichtsheft schreiben
-
Pflicht zur Krankmeldung
-
Teilnahmepflicht und Lernpflicht
-
Sorgfaltspflicht und Bewahrungspflicht
-
Schweigepflicht
Rechtlichen Voraussetzungen zur Begründung von Ausbildungsverhältnissen
- Berufsausbildungsvertrag, § 12 BBiG
Ausbildende haben unverzüglich nach Abschluss des Berufsausbildungsvertrages, spätestens vor Beginn der Berufsausbildung, den wesentlichen Inhalt des Vertrages gemäß Satz 2 schriftlich niederzulegen; die elektronische Form ist ausgeschlossen. - Betrieblicher Ausbildungsplan
Der Betrieb muss den Ausbildungsrahmenplan vor Beginn der Ausbildung in einem betrieblichen Ausbildungsplan auf die konkreten betrieblichen Gegebenheiten anpassen. In dem betrieblichen Ausbildungsplan muss auch stehen, wie viel Lernzeit für welche Inhalte im Betrieb oder ggf. bei Verbundpartnern vorgesehen ist. - Wahlqualifikationen festlegen
In den Ausbildungsverordnungen der Ausbildungsberufe kann eine Anzahl an „Wahlqualifikationen“ vorgeschrieben sein. Sie sind von Bedeutung für die Ausbildung und Abschlussprüfung. Die dort vorgeschriebenen Wahlqualifikationen müssen bereits im Berufsausbildungsvertrag schriftlich vereinbart werden oder können mit einem Vertragszusatz als Anlage zum Berufsausbildungsvertrag nachträglich (spätestens ein Jahr vor Ausbildungsende) erfolgen. - Ärztliche Erstuntersuchung bei Minderjährigen, § 32 JArbSchG
Ein Jugendlicher, der in das Berufsleben eintritt, darf nur beschäftigt werden, wenn:
-
- er innerhalb der letzten vierzehn Monate von einem Arzt untersucht worden ist (Erstuntersuchung) und
- dem Arbeitgeber eine von diesem Arzt ausgestellte Bescheinigung vorliegt.
-
Absatz 1 gilt nicht für eine nur geringfügige oder eine nicht länger als zwei Monate dauernde Beschäftigung mit leichten Arbeiten, von denen keine gesundheitlichen Nachteile für den Jugendlichen zu befürchten sind.
-
- Probezeit, § 20 BBiG
-
Das Berufsausbildungsverhältnis beginnt mit der Probezeit. Sie muss mindestens einen Monat und darf höchstens vier Monate betragen.
-
Inhalte des Ausbildungsvertrages, § 11 BBiG
- Name und Anschrift der Ausbildenden sowie der Auszubildenden, bei Minderjährigen zusätzlich Name und Anschrift ihrer gesetzlichen Vertreter oder Vertreterinnen,
- Art, sachliche und zeitliche Gliederung sowie Ziel der Berufsausbildung, insbesondere die Berufstätigkeit, für die ausgebildet werden soll,
- Beginn und Dauer der Berufsausbildung,
- die Ausbildungsstätte und Ausbildungsmaßnahmen außerhalb der Ausbildungsstätte,
- Dauer der regelmäßigen täglichen Ausbildungszeit,
- Dauer der Probezeit,
- Zahlung und Höhe der Vergütung sowie deren Zusammensetzung, sofern sich die Vergütung aus verschiedenen Bestandteilen zusammensetzt,
- Vergütung oder Ausgleich von Überstunden,
- Dauer des Urlaubs,
- Voraussetzungen, unter denen der Berufsausbildungsvertrag gekündigt werden kann,
- ein in allgemeiner Form gehaltener Hinweis auf die Tarifverträge, Betriebs- oder Dienstvereinbarungen, die auf das Berufsausbildungsverhältnis anzuwenden sind,
- die Form des Ausbildungsnachweises nach § 13 Satz 2 Nummer 7.
Die Niederschrift ist von den Ausbildenden, den Auszubildenden und deren gesetzlichen Vertretern und Vertreterinnen zu unterzeichnen.
Ausbildende haben den Auszubildenden und deren gesetzlichen Vertretern und Vertreterinnen eine Ausfertigung der unterzeichneten Niederschrift unverzüglich auszuhändigen.
Bei Änderungen des Berufsausbildungsvertrages gelten die Absätze 1 bis 3 entsprechend.
Konfliktsituationen in der Ausbildung und Lösungsmöglichkeiten
Modell der Konflikteskalation nach Friedrich Glasl
Die Gefahren von Konflikten sind groß, gerade, wenn man diese unbeachtet lässt. Wenn festgestellt wird, dass ein Konflikt mit Auszubildenden oder Ausbildern in der Luft liegt bzw. liegen könnte, sollte so schnell wie möglich ein Konfliktgespräch arrangieren werden.
Es sollte sich mit dem Konflikt auseinandergesetzt und Lösungsmöglichkeiten gesucht werden. Beide Parteien sollten die Möglichkeit haben, Ihre Meinung mit einzubringen, denn für beide sollte eine zufriedenstellende Lösung angestrebt werden. Falls Unterstützung bei der Konfliktbewältigung gebraucht wird, empfiehlt es sich Hilfe von außen zu holen.
Beendigung von Ausbildungsverhältnissen
- Kündigung vor Ausbildungsbeginn
- Kündigung während der Probezeit (§ 22 BBiG)
- Während der Probezeit kann das Berufsausbildungsverhältnis jederzeit ohne Einhalten einer Kündigungsfrist gekündigt werden.
- Kündigung nach der Probezeit (§ 22 BBiG)
- Nach der Probezeit kann das Berufsausbildungsverhältnis nur gekündigt werden
-
-
aus einem wichtigen Grund ohne Einhalten einer Kündigungsfrist
-
- von Auszubildenden mit einer Kündigungsfrist von vier Wochen, wenn sie die Berufsausbildung aufgeben oder sich für eine andere Berufstätigkeit ausbilden lassen wollen.
-
- Nach der Probezeit kann das Berufsausbildungsverhältnis nur gekündigt werden
- Auflösung des Vertrages im gegenseitigen Einvernehmen (Aufhebungsvertrag)
- Wenn die Vertragspartner einsehen, dass aus verschiedensten Gründen eine erfolgreiche Fortsetzung der Ausbildung nicht möglich ist, sollte immer das Gespräch gesucht werden, um im Guten auseinander zu gehen. Der Aufhebungsvertrag ist die einverständliche Vereinbarung zwischen Ausbilder und Auszubildenden, das Ausbildungsverhältnis zu einem bestimmten Zeitpunkt zu beenden.
-
Beendigung durch das Ende der Berufsausbildung
§ 623 BGB: Die Beendigung von Arbeitsverhältnissen durch Kündigung oder Auflösungsvertrag bedürfen zu ihrer Wirksamkeit der Schriftform; die elektronische Form ist ausgeschlossen.
Schutzvorschriften (Jugendarbeitsschutz, Arbeitszeit, Urlaub)
§ 8 JArbSchG: Jugendliche dürfen nicht mehr als acht Stunden täglich und nicht mehr als 40 Stunden wöchentlich beschäftigt werden.
§ 11 JArbSchG: Jugendlichen müssen im voraus feststehende Ruhepausen von angemessener Dauer gewährt werden. Die Ruhepausen müssen mindestens betragen:
- 30 Minuten bei einer Arbeitszeit von mehr als viereinhalb bis zu sechs Stunden,
- 60 Minuten bei einer Arbeitszeit von mehr als sechs Stunden.
Als Ruhepause gilt nur eine Arbeitsunterbrechung von mindestens 15 Minuten.
§ 12 JArbSchG: Bei der Beschäftigung Jugendlicher darf die Schichtzeit (§ 4 Abs. 2) 10 Stunden. Ausnahmen sind für bestimmten Branchen zulässig.
§ 14 JArbSchG: Jugendliche dürfen nur in der Zeit von 6 bis 20 Uhr beschäftigt werden.
Für Azubis über 18 Jahren greift das Bundesurlaubsgesetz (BUrlG), das jedem Arbeitnehmer mindestens 24 Werktage bezahlten Urlaub zugesteht, für Jugendliche gibt es abermals das Jugendarbeitsschutzgesetz. In § 19 finden sich zum Urlaub folgende Regelungen: Ist der Auszubildende unter 16, hat er Anspruch auf 30 Werktage Urlaub. Ist er jünger als 17, stehen ihm 27 Urlaubstage zu und mit unter 18 Jahren sind es immerhin noch 25 Tage.
Gesetz zum Schutze der arbeitenden Jugend (Jugendarbeitsschutzgesetz - JArbSchG) § 9 Berufsschule
- Der Arbeitgeber hat den Jugendlichen für die Teilnahme am Berufsschulunterricht freizustellen. Er darf den Jugendlichen nicht beschäftigen
- vor einem vor 9 Uhr beginnenden Unterricht; dies gilt auch für Personen, die über 18 Jahre alt und noch berufsschulpflichtig sind,
- an einem Berufsschultag mit mehr als fünf Unterrichtsstunden von mindestens je 45 Minuten, einmal in der Woche,
- in Berufsschulwochen mit einem planmäßigen Blockunterricht von mindestens 25 Stunden an mindestens fünf Tagen; zusätzliche betriebliche Ausbildungsveranstaltungen bis zu zwei Stunden wöchentlich sind zulässig.
- Auf die Arbeitszeit des Jugendlichen werden angerechnet
- Berufsschultage nach Absatz 1 Satz 2 Nummer 2 mit der durchschnittlichen täglichen Arbeitszeit,
- Berufsschulwochen nach Absatz 1 Satz 2 Nummer 3 mit der durchschnittlichen wöchentlichen Arbeitszeit,
- im Übrigen die Unterrichtszeit einschließlich der Pausen.
- Ein Entgeltausfall darf durch den Besuch der Berufsschule nicht eintreten.
Anbahnung (zulässige und nicht zulässige Fragen) eines Arbeitsvertrages
Bei der Anbahnung eines Arbeitsverhältnisses entstehen gegenseitige Rechte und Pflichten der Vertragsparteien. Das Anbahnungsverhältnis ist dadurch charakterisiert, dass zwischen den Parteien zwar noch keine Hauptleistungspflichten (Pflicht zur Erbringung der Arbeitsleistung, Pflicht zur Entgeltzahlung) bestehen, die Parteien jedoch nach § 241 Abs. 2 BGB zur Rücksichtnahme auf die Rechte, Rechtsgüter und Interessen des anderen verpflichtet sind.
Rechte und Pflichten der Vertragsparteien
Die Rechte und Pflichten von Arbeitgebern sind ebenso gesetzlich geregelt wie die Rechte und Pflichten der Arbeitnehmer.
Die Rechte der Arbeitgeber lassen sich so zusammenfassen:
- Recht auf vollständige Leistungserfüllung
- Recht auf Treue und Solidarität
- Recht auf wahrheitsgemäße Antworten
- Direktions- und Weisungsrecht
Die Pflichten der Arbeitgeber umfassen folgende Aspekte:
- Schriftliche Fixierung der Aufgaben und Ziele
- Festlegung betrieblicher Regelungen
- Entgeltzahlung (Höhe und Auszahlung)
- Schutz- und Fürsorgepflicht
- Pflicht zur Gleichbehandlung
- Entgeltumwandlung (Altersvorsorge)
- Entgeltfortzahlung bis zum Ende der Beschäftigung
- Gewährung von bezahltem Erholungsurlaub
Beendigung von Arbeitsverhältnissen
Das Arbeitsverhältnis eines Arbeiters oder eines Angestellten (Arbeitnehmers) kann mit einer Frist von vier Wochen zum Fünfzehnten oder zum Ende eines Kalendermonats gekündigt werden. Für eine Kündigung durch den Arbeitgeber gibt es die Kündigungsfrist, welche je nach Jahre der Anstellung unterschiedlich ausfallen kann.
Während einer vereinbarten Probezeit, längstens für die Dauer von sechs Monaten, kann das Arbeitsverhältnis mit einer Frist von zwei Wochen gekündigt werden.
Die Beendigung von Arbeitsverhältnissen durch Kündigung oder Auflösungsvertrag bedürfen zu ihrer Wirksamkeit der Schriftform; die elektronische Form ist ausgeschlossen.
Besonderer Kündigungsschutz
Sinn und Zweck des Sonderkündigungsschutzes ist es, bestimmte Personengruppen, die als sozial besonders schutzwürdig angesehen werden, stärker vor dem Verlust des Arbeitsplatzes zu bewahren als andere Arbeitnehmer. Der Sonderkündigungsschutz bedeutet aber nicht, dass unter allen Umständen am Arbeitsverhältnis festgehalten werden muss.
Besonderen Kündigungsschutz haben vor allem:
- schwerbehinderte und ihnen gleichgestellte Arbeitnehmer
- Schwangere und Mütter
- Personen, die Elternzeit in Anspruch nehmen (oder beantragen)
- Betriebsräte und Personalräte sowie andere Mandatsträger des Betriebsverfassungsgesetzes bzw. der
- Personalvertretungsgesetze (auch Wahlbewerber)
- Unkündbare Arbeitnehmer
- Personen, die Pflegezeit in Anspruch nehmen (oder beantragen)
- Auszubildende
- Wehr- oder Ersatzdienstleistende
- Auch Massenentlassungen zählen im weitesten Sinne zum Sonderkündigungsschutz
Der Sonderkündigungsschutz schützt nur die Arbeitnehmer, nicht aber die Arbeitgeber vor Kündigungen des Arbeitnehmers.
Qualifiziertes Arbeitszeugnis
Der Arbeitnehmer hat bei Beendigung eines Arbeitsverhältnisses Anspruch auf ein schriftliches Zeugnis. Das Zeugnis muss mindestens Angaben zu Art und Dauer der Tätigkeit (einfaches Zeugnis) enthalten. Der Arbeitnehmer kann verlangen, dass sich die Angaben darüber hinaus auf Leistung und Verhalten im Arbeitsverhältnis (qualifiziertes Zeugnis) erstrecken.
Das Zeugnis muss klar und verständlich formuliert sein. Es darf keine Merkmale oder Formulierungen enthalten, die den Zweck haben, eine andere als aus der äußeren Form oder aus dem Wortlaut ersichtliche Aussage über den Arbeitnehmer zu treffen. Eine Erteilung des Zeugnisses in elektronischer Form ist ausgeschlossen.
Bestimmungen zur Errichtung eines Betriebsrats
- Wer kann einen Betriebsrat gründen? Alle Arbeitnehmer*innen können einen Betriebsrat gründen. Es reichen drei Beschäftigte, die gemeinsam die Gründung betreiben. Will die Betriebsleitung die Gründung verhindern, macht sie sich strafbar. Allerdings müssen mindestens fünf wahlberechtigte Beschäftigte in deinem Betrieb wahlberechtigt sein. Von ihnen müssen drei die Voraussetzung zur Kandidatur erfüllen.
- Wer ist wahlberechtigt? Alle Beschäftigten, die das 16. Lebensjahr vollendet haben und am Tag der Wahl im Betrieb angestellt sind. Nicht wahlberechtigt sind leitende Angestellte.
- Wer kann für das Amt kandidieren? Alle Kolleg*innen, die länger als sechs Monate im Betrieb beschäftigt und 18 Jahre alt sind, können sich in den Betriebsrat wählen lassen.
- Wann kann ich einen Betriebsrat gründen? In Betrieben ohne Betriebsrat kann eine erstmalige Wahl jederzeit durchgeführt werden. Allerdings wird der dann gewählte Betriebsrat in den gesetzlichen, regelmäßigen Wahlrhythmus eingebunden. Gewählt wird alle vier Jahre (2022, 2026, 2030 usw.). Die erste Amtszeit kann sich also verkürzen.
- Wie organisiere ich eine Betriebsratswahl? Bildung eines Wahlvorstand. Er ist das Gremium, das die Wahl durchführt. Der Wahlvorstand besteht in der Regel aus drei wahlberechtigten Kolleg*innen. Dieser muss immer aus einer ungeraden Zahl von Mitgliedern bestehen. Drei wahlberechtigte Kolleg*innen laden zu einer Betriebsversammlung ein und machen Vorschläge zur Zusammensetzung des Wahlvorstandes. Die Mehrheit der anwesenden Kolleg*innen kann den Wahlvorstand nun wählen.
- Wie führe ich die Betriebsratswahl durch? Es gibt zwei Verfahren. Das reguläre und das vereinfachte zweistufige Wahlverfahren. Welches Verfahren im Betrieb zulässig ist, hängt von der Größe des Betriebes ab:
- 5 bis 100 wahlberechtigte Arbeitnehmer*innen: vereinfachtes zweistufiges Wahlverfahren.
- 101 bis 200 wahlberechtigte Arbeitnehmer*innen: reguläres Wahlverfahren oder Vereinbarung mit dem Arbeitgeber, das vereinfachte Verfahren durchzuführen.
- Mehr als 200 wahlberechtigte Arbeitnehmer*innen: reguläres Wahlverfahren.
Stufen der Mitbestimmung des Betriebsrats
Spricht man von Mitbestimmungsrecht des Betriebsrats, ist damit in der Regel immer die „echte“ oder auch erzwingbare Mitbestimmung gemeint. Mitbestimmung bedeutet, dass der Arbeitgeber nicht ohne die Zustimmung des Betriebsrats Entscheidungen treffen darf. Tut er es doch, ist diese unwirksam. Im Gegenzug bedeutet dies aber auch, dass der Arbeitgeber in allen anderen Belangen frei und ohne Zustimmung des Betriebsrats entscheiden kann.
-
Das Informations- und Beratungsrecht. Der Arbeitgeber muss den Betriebsrat beispielsweise über Fragen der Unternehmensplanung rechtzeitig und umfassend informieren. Der Betriebsrat muss vom Arbeitgeber in Überlegungen miteinbezogen werden, bevor diese abgeschlossen sind.
- Das Anhörungsrecht. Will der Arbeitgeber zum Beispiel einem Beschäftigten kündigen, gilt das Anhörungsrecht. Das heißt: Der Betriebsrat darf zur beabsichtigten Kündigung Stellung nehmen. Widerspricht der Betriebsrat der Kündigung, kann der Arbeitgeber aber trotzdem die Kündigung aussprechen. Klagt allerdings der Beschäftigte gegen seine Kündigung, bleibt er in diesem Fall bis zum Abschluss des Kündigungsschutzverfahrens im Betrieb beschäftigt. Eine ohne Anhörung des Betriebsrats ausgesprochene Kündigung ist unwirksam.
- Zustimmungsverweigerung. Der Arbeitgeber muss die Zustimmung des Betriebsrates einholen, wenn er einen Mitarbeiter versetzen oder einen neuen Beschäftigten einstellen will. Lehnt der Betriebsrat die Entscheidung des Arbeitgebers ab, bleibt dem Arbeitgeber nur der Gang zum Arbeitsgericht. Dieses kann die Zustimmung des Betriebsrates ersetzen.
- Erzwingbare Mitbestimmung. Dieses Recht wird auch Mitwirkungsrecht genannt und greift bei allen Fragen der Arbeitszeitgestaltung und Urlaubsplanung. Auch Richtlinien der Personalpolitik und Fragen der Qualifizierung von Beschäftigten fallen darunter. Der Betriebsrat hat hier gegen den Arbeitgeber grundsätzlich einen Unterlassungsanspruch, kann aber umgekehrt auch immer die Initiative ergreifen, wenn er einen bisher noch nicht geregelten Sachverhalt künftig geregelt haben möchte.
Tarifvertragsarten (Entgelt-, Rahmenentgelt- und Manteltarifvertrag)
- Entgelttarifvertrag. Regelt die Grundvergütung, auch für Auszubildende.
- Rahmentarifverträge. Hier sind die Entgeltgruppen und Entgeltformen festgelegt.
- Manteltarifverträge. Sie enthalten Bestimmungen über Arbeitsbedingungen wie Einstellung und Kündigung, Arbeitszeit, Zuschläge.
Tarifverträge, Tarifautonomie und Tarifbindung
Ein Tarifvertrag ist ein Vertrag zwischen Arbeitgeber*innen und Gewerkschaften. Er regelt die Rechte und Pflichten von Arbeitnehmer*in nen und Arbeit geber:in nen. Dazu gehören auch die Arbeits bedingungen. Ein Tarifvertrag steht rechtlich über einem Arbeitsvertrag.
Tarifautonomie ist die Befugnis von Gewerkschaften einerseits und Arbeitgebenden bzw. Verbänden von Arbeitgebenden andererseits, durch verbindliche Verträge (Tarifverträge) und unabhängig von staatlicher Einflussnahme die Arbeitsverhältnisse zwischen ihren Mitgliedern selbstständig zu regeln.
Tarifgebunden sind die Mitglieder der Tarifvertragsparteien und der Arbeitgeber, der selbst Partei des Tarifvertrags ist. Rechtsnormen des Tarifvertrags über betriebliche und betriebsverfassungsrechtliche Fragen gelten für alle Betriebe, deren Arbeitgeber tarifgebunden ist.
Ablauf von Tarifverhandlungen und Arbeitskampf (Schlichtung, Streik, Aussperrung)
Bei einer Tarifverhandlung verhandeln die Gewerkschaften im Auftrag ihrer Mitglieder.
Wenn sich die Tarifvertragsparteien geeinigt haben, schreiben sie die vereinbarten Regeln in einen Tarifvertrag. Dabei wird auch die Mindestlaufzeit für den Tarifvertrag festgelegt. In dieser Zeit herrscht Friedenspflicht zwischen den Tarifvertragsparteien. Das heißt: Arbeitgeber*innen dürfen nicht wegen Forderungen streiken, die in diesem Tarifvertrag bereits geregelt sind. Wenn die Mindestlaufzeit vorbei ist, dürfen die Tarifvertragsparteien den Tarifvertrag kündigen. Dann dürfen sie für Forderungen streiken, die den gekündigten Tarifvertrag betreffen.
Arbeitnehmer:innen dürfen nur streiken, wenn die Gewerkschaft zum Streik aufruft und keine Friedenspflicht besteht.
Das ist der Fall:
- Wenn es für ihre Forderungen noch keine tarifliche Regelung gibt.
- Wenn die Regeln im Tarifvertrag durch die Kündigung des Tarifvertrages nicht mehr gültig sind.
Wenn sich die Tarifvertragsparteien nicht einigen, können sie jederzeit eine Schlichtung vereinbaren. Bei einer Schlichtung hört sich eine unabhängige Person die Forderungen beider Seiten an.
Diese Person heißt Schlichter*in. Schlichter*innen machen Vorschläge für Kompromisse im Tarifvertrag. Die Gewerkschaft stellt diese Vorschläge ihren Mitgliedern vor. Die Mitglieder
diskutieren über die Vorschläge, dann stimmen sie darüber ab. Die Arbeitgeber*innen machen das genauso. Wenn beide Tarifvertragsparteien den Vorschlägen zustimmen, gibt es eine Tarifeinigung.
Grundzüge der Sozialversicherung (Versicherungspflicht, Träger)
Die 5 Säulen der Sozialversicherung (auch 5 Säulen des Sozialstaates genannt) bilden die Basis für die gesetzliche Sozialversicherung in Deutschland.
Die Zweige der Sozialversicherung in Deutschland umfassen:
- Krankenversicherung
- Unfallversicherung
- Rentenversicherung
- Pflegeversicherung
- Arbeitslosenversicherung
Die gesetzliche Sozialversicherung ist in Deutschland eine Pflichtversicherung.
| Merkmal | Kranken-versicherung | Unfall-versicherung | Renten-versicherung | Pflege-versicherung | Arbeitslosen-versicherung |
| Einführung | 1883 |
1884 |
1889 |
1995 |
1927 |
| Träger der Sozial-versicherung | Krankenkassen | Berufs-genossenschaft | Deutsche Renten-versicherung |
Pflegekassen | Bundesagentur für Arbeit |
| Verpflichtend für | alle Einwohner Deutschlands |
Arbeitgeber muss die Versicherung für alle AN, Azubis, Schüler und Studenten abschließen |
Arbeitnehmer, Auszubildende, Handwerker, Landwirte |
alle Krankenversicherten | Arbeitnehmer, Auszubildende |
|
aktuelle Beiträge (vom Bruttolohn) |
14,6% |
unterschiedlich, hängt von Lohn, Beruf und Gefahren im Beruf ab |
18,6% Beitrags-bemessungsgrenze beachten |
3,05% Kinderlose zwischen 23 und 65 zusätzlich 0.25% (alleine vom AN) |
2,4% |
| Aufteilung der Beiträge |
50% AG 50% AN |
100% AG |
50% AG 50% AN |
50% AG 50% AN |
50% AG 50% AN |
Privater Zusatzversicherungen (Berufsunfähigkeitsversicherung, private Altersvorsorge, Haftpflichtversicherung)
Eine Berufsunfähigkeitsversicherung sichert Sie finanziell ab, wenn Sie Ihren Beruf aufgrund von Krankheit oder einem Unfall für längere Zeit oder gar dauerhaft nicht mehr ausüben können. Sie zählt damit zu den wichtigsten Versicherungen.
Eine private Rentenversicherung ist laut Definition keine Versicherung im eigentlichen Sinn, sondern es handelt sich eher um einen Sparplan. Sie zahlen bestimmte Beiträge ein und erhalten ab einem fest vereinbarten Zeitpunkt eine monatliche Rente.
Eine Haftpflichtversicherung ist eine Schadenversicherung, über die zwischen dem Versicherer und dem Versicherungsnehmer ein Versicherungsvertrag abgeschlossen wird. Die Hauptpflichten des Versicherers aus dem Vertrag bestehen in erster Linie in der Abwehr von unberechtigten Schadensersatzansprüchen Dritter gegen den Versicherungsnehmer und in zweiter Linie in der Freistellung des Versicherungsnehmers bei berechtigten Schadensersatzansprüchen des Geschädigten.
Lohnabrechnungen (Brutto-, Nettolohn, Auszahlungsbetrag)
Eine Gehaltsabrechnung bzw. eine Lohnabrechnung ist ein Dokument, in dem aufgelistet wird, aus welchen Bestandteilen sich der Lohn bzw. das Gehalt eines Mitarbeiters in einem bestimmten Zeitraum zusammensetzt. Anhand der Gehaltsabrechnung können sowohl Arbeitnehmer als auch Arbeitgeber die erfolgte Zahlung des Gehalts nachvollziehen.
Brutto-Definition: Zahlungen vor Abzug von Steuern und Abgaben.
Netto-Definition: Zahlungen nach Abzug von Steuern und Abgaben.
Das Nettogehalt ist das Gehalt (Arbeitsentgelt), das nach Abzug von Steuern und Sozialabgaben übrig bleibt:
Nettolohn = Bruttolohn − Steuern − Sozialabgaben
Netto ist also immer die aus Sicht des Geldempfängers steuerbereinigte Version, während Brutto noch um Steuern und Sozialabgaben bereinigt werden muss.
Inhalt und Aufbau der Lohnabrechnungen:
Kopfteil
- Name und Anschrift des Arbeitgebers sowie des Arbeitnehmers
- Bezugsdatum und Erstellungsdatum der Entgeltabrechnung
- Steuerdaten und Sozialversicherungsdaten des Arbeitnehmers
- Persönliche Daten / Vertragsdaten sowie Urlaubsdaten des Arbeitnehmers
Hauptteil
- Brutto-Lohn oder Gehalt
- Sachbezüge / geldwerte Vorteile
- Vermögenswirksame Leistungen
- Beitrag zur betrieblichen Altersvorsorge
- Steuerfreibeträge
- Kirchensteuerabzug
- Sozialversicherungsbeiträge des Arbeitnehmers
- Persönliche Abzüge
- Aufwandsentschädigungen
- Auszahlungsbetrag
Schlussteil
- Kontodaten des Arbeitnehmers
- Gesamtsumme des Arbeitgebers
- Verdienstbescheinigung
- Evtl. ein Hinweis darüber, dass die Abrechnung gemäß § 108 Abs. 3 Satz 1 der Gewerbeordnung erstellt wurde

2 - Als Konsument rechtliche Bestimmungen in Alltagssituationen anwenden
Rechts-u. Geschäftsfähigkeit
- Rechtsfähigkeit
- Bei der Rechtsfähigkeit wird grundsätzlich zwischen natürlichen und juristischen Personen unterschieden.
- Natürliche Personen
- sind von der Geburt bis zum Tod rechtsfähig. Können sie ihre Rechte und Pflichten nicht selbst wahrnehmen, bekommen sie einen gesetzlichen Vertreter gestellt.
- Juristische Personen
- Privates Recht
- z. B. AG, e. V., GmbH, etc. sind von der Eintragung in einem öffentlichen Register bis zur Löschung in diesem rechtsfähig.
- Öffentliches Recht
- z. B. BRD, Bundesländer, Gemeinden oder Handwerkskammern sind rechtsfähig ab staatlicher Verleihung bis zum staatlichen Entzug.
- z. B. BRD, Bundesländer, Gemeinden oder Handwerkskammern sind rechtsfähig ab staatlicher Verleihung bis zum staatlichen Entzug.
- Privates Recht
- Natürliche Personen
-
An alle Rechte sind auch automatisch Pflichten gekoppelt!
- Bei der Rechtsfähigkeit wird grundsätzlich zwischen natürlichen und juristischen Personen unterschieden.
- Geschäftsfähigkeit
- Geschäftsunfähigkeit
- alle Kinder unter 7 Jahren, es sei denn, sie handeln als Boten, dann wird die Willenserklärung durch sie überbracht.
- Rechtsgeschäfte sind nichtig
- Beschränkt Geschäftsfähig
- alle Personen ab 7 bis 18. Sie dürfen Rechtsgeschäfte mit Zustimmung der gesetzlichen Vertreter abschließen.
- Ausnahmen sind:
- Geschäfte, die mit eigenen Mitteln (Taschengeld) getätigt werden
- Geschäfte, die nur rechtliche Vorteile bringen
- Alles was das Arbeitsverhältnis betrifft, dem die Vertreter zugestimmt haben.
- Rechtsgeschäfte sind schwebend unwirksam, bis zur Zustimmung oder Ablehnung der Vertreter.
- Voll Geschäftsfähig
- alle ab 18, die auch mündig sind
- existente juristische Personen
- Rechtsgeschäfte sind voll gültig
- Geschäftsunfähigkeit
Rechtsgeschäfte
- Zustandekommen
- Willenserklärung
- Einseitig
- z. B. Testament oder Kündigung. Hier muss nur eine Person ihren Willen erklären.
- Zweiseitig
- sind meist Verträge wie z. B. ein Kaufvertrag oder ein Arbeitsvertrag. Es sind mindestens zwei Parteien notwendig, deren Willen übereinstimmt. Hierbei entstehen einseitige oder auch zweiseitige Verpflichtungen. Ware muss übergeben werden, Geld muss gezahlt werden.
- Einseitig
- Schlüssige Handlung
- Ein Kunde legt z. B. seine Einkäufe auf das Kassenband
- Schweigen
- Kaufleute
- schweigen auf abgeänderte Auftragsbestätigung
- nicht Kaufleute
- schweigen ist Ablehnung
- Kaufleute
- Willenserklärung
- Formvorschriften
- Grundsätzlich Formlos
- Gesetzlich kann bestimmte Form verlangt werden:
- Schriftform, öffentlich beglaubigt, notariell beglaubigt
- Nichtigkeit & Anfechtbarkeit
- Nichtig: (von Anfang an nichtig)
- verstoß gegen gesetzl. Verbot
- Geschäftsunfähigkeit
- Sittenwidrigkeit
- Formmangel
- Scherzgeschäft
- Scheingeschäft
- Anfechtbarkeit (erst durch Anfechtung nichtig)
- widerrechtliche Drohung
- arglistige Täuschung
- Irrtum
- Nichtig: (von Anfang an nichtig)
Kaufvertrag
- Zustandekommen von Kaufverträgen
- Grundsätzlich sind hierzu immer zwei übereinstimmende Willenserklärungen notwendig. Des Weiteren entsteht ein Kaufvertrag immer durch die Annahme eines Antrags. Dieser kann in Form einer Bestellung oder eines Angebots entstehen.
- Wichtige Inhalte
- Art und Güte der Ware
- Lieferzeit
- Verpackungskosten
- Beförderungskosten
- Zahlungsbedingungen
- Preis und Preisnachlässe
- Erfüllungsort
- Gerichtsstand
- Pflichten
- Verkäufer
- mängelfreie Lieferung
- Annahme des Kaufpreises
- Käufer
- Annahme der Ware
- Zahlung
- Verkäufer
- Besitz und Eigentum
- Besitz
- Physische Gewalt über eine Sache
- Eigentum
- rechtliche Gewalt über eine Sache
- Besitz
- Leistungsstörungen beim Kaufvertrag
- bestehen, wenn Pflichten aus dem Vertrag nicht eingehalten werden.
- Verzug
- Lieferverzug (Käuferrechte)
- Lieferung und Schadensersatz
- Rücktritt
- Schadensersatz und Rücktritt
- Zahlungsverzug (Verkäuferrechte)
- Rechnungssumme
- Verzugszinsen
- Kostenersatz
- Rücktritt
- Annahmeverzug (Verkäuferrechte)
- Einlagerung auf Käuferkosten
- Klage auf Abnahme
- Versteigerung nach Androhung
- Rücktritt
- Schadensersatz
- Lieferverzug (Käuferrechte)
- Sachmängelhaftung
- Sachmängel sind z. B.
- Schlechte Qualität, falsche Ware, zu wenig, nicht eingehaltene Werbeaussagen, Montagemängel
- Bei Verkauf an Privatperson muss es 2 Jahre Haftung geben.
- Bei Verkauf an Unternehmen kann die Haftung individuell ganz ausgeschlossen werden, über die AGB auf ein Jahr herabgesetzt werden.
- Sachmängel sind z. B.
Zahlungsverzug
- Hat grundsätzlich ein Mahnverfahren zur Folge.
- Außergerichtliches Mahnverfahren
- freundliche Zahlungserinnerung
- 1. Mahnung
- 2. Mahnung → Gerichtliches Mahnverfahren
- Gerichtliches Mahnverfahren
- Erlass eines Mahnbescheids wird beantragt und dieser wird zugestellt
- Schuldner zahlt → Verfahren eingestellt
- Schuldner erhebt innerhalb 14 Tage Einspruch → Mündliche Gerichtsverhandlung
- Schuldner reagiert nicht
- Vollstreckungsbescheid wird beantragt
- Schuldner zahlt → Verfahren eingestellt
- Schuldner erhebt innerhalb 14 Tage Einspruch → Mündliche Gerichtsverhandlung → Zwangsvollstreckung
- Schuldner reagiert nicht → Zwangsvollstreckung
- Vollstreckungsbescheid wird beantragt
- Erlass eines Mahnbescheids wird beantragt und dieser wird zugestellt
- Außergerichtliches Mahnverfahren
Verbraucherschutz
- Verbraucherberatung
- Verbraucherzentralen
- Stiftung Warentest
- Massenmedien
- Haftung & Schadenersatz?
- Gesetz gegen den unlauteren Wettbewerb UWG
- Verboten sind diverse Werbemaßnahmen, die: Angst verbreiten, Konkurrenten anschwärzen, fremde Geschäfts, waren und Firmenzeichen verwenden, Teilnahme am Gewinnspiel vom Kauf abhängt.
- Irreführende Werbung ist verboten
- Vergleichende, herabsetzende Werbung ist verboten
- belästigende Werbung ist verboten
- Haustürgeschäfte
- Sind Geschäfte, die an der Haustüre, auf offener Straße, bei Verkaufsfahrten oder einfach außerhalb der Geschäftsräume zustande kommen.
- Hier gilt ein 14 Tage Widerrufsrecht
- Wenn der Verkäufer bestellt wurde oder der Betrag unter 40 € liegt, gilt das Widerrufsrecht nicht.
- Produkthaftung
- Soll den Verbraucher vor Schäden durch ein Produkt schützen.
- Hersteller haftet egal, ob verschuldet oder nicht.
- Gilt nur bei Privatpersonen
- Preisangabenverordnung?
- Allgemeine Geschäftsbedingungen
- Nur gültig, wenn Kunde darauf hingewiesen wurde
- Mühelos les- und verstehbar sein
- Keine: überraschenden Klauseln, unangemessene lange Lieferfristen, Preiserhöhungen vor 4 Monaten nach Vertragsschluss.
- Gesetze zur Sachmängelhaftung und mangelhafter Lieferung gelten trotzdem.
Umgang mit Geld
- Zahlungsmöglichkeiten
- Barzahlung (persönliche Übergabe, Geldversand)
- Halb bare Zahlung (Barscheck, Nachnahme, Zahlschein)
- unbare Zahlung (Überweisung, Lastschrift, Kreditkarte, Verrechnungsscheck)
- Girokonten
- Um ein Girokonto zu eröffnen, muss man voll geschäftsfähig und volljährig sein, sich ausweisen und seine Unterschrift hinterlegen.
- Für jugendliche strenge Auflagen
- vor der Eröffnung sollte man Dinge wie Kontoführungsgebühren, Kosten für Serviceleistungen und Überziehungszinsen vergleichen.
- Ermöglicht halb bare und unbare Zahlungen
- Formen des Zahlungsverkehrs (Barzahlung, Überweisung, Bankkarte, Kreditkarte, elektronische Zahlungssysteme) → sollte jedem klar sein, was was ist.
- Anlageformen (Termingeld, Aktienfonds)
- Verbraucherdarlehen
- Haushaltsplan, Schuldnerberatung, Verbraucherinsolvenz
3 - Wirtschaftliches Handeln in der Sozialen Marktwirtschaft beurteilen
Marktdefinition
Ort an dem sich Angebot und Nachfrage treffen. Muss kein physikalischer Ort sein z.B. Marktplatz, Telefon, Supermarkt usw.
Marktarten
| Konsumgütermarkt |
Handel mit Gütern für die Endverbraucher, wie z.B. Nahrungsmittel oder Fernsehgeräte |
| Investitionsgütermarkt |
Handel mit Gütern, die zur Herstellung von anderen Gütern verwendet werden, wie z.B. Maschinen |
| Geldmarkt |
Bereitstellung von kurzfristigen Krediten durch Banken, Sparkassen und Privatpersonen |
| Kapitalmarkt |
Bereitstellung von langfristigen Krediten durch Banken, Sparkassen und Privatpersonen |
| Arbeitsmarkt |
menschliche Arbeitskraft wird angeboten bzw. nachgefragt |
| Immobilienmarkt |
Handel mit Grundstücken und Gebäuden |
| Devisenmarkt |
Handel mit ausländischen Währungen (Devisen) |
| sonstige Märkte |
Handel mit Rohstoffen, Berauchtwagen, Kundgegenständen usw. |
Marktformen
- Polypol = auf einem Markt treffen viele Nachfrage auf viele Anbieter. Wird auch "vollständige Konkurrenz" genannt. Kein Marktteilnehmer ist groß genug um den Marktpreis zu beeinflussen
- Oligopol
- Angebotsoligopol = wenige Anbieter stehen vielen Nachfragern gegenüber. Kommt häufig in Industriegeselleschaften vor. Beispiele: Automarkt, Zigarettenmarkt, Benzinmarkt
- Nachfrageoligopol = viele Anbieter stehen wenigen Nachfragern gegenüber. Beispiel: wenig Molkereien stehen viele Bauern gegenüber
- Monopol
- Angebotsmonopol = alleiniger Anbieter auf einem Markt. Beispiel: Wasserwerke
- Nachfragemonopol = alleinger Nachfrager auf einem Markt. Beispiele: Deutsche Bahn (Lokomotiven) und Bundeswehr (Schützenpanzer)
Gesamtangebot, Gesamtnachfrage und Gleichgewichtspreis tabellarisch und zeichnerich ermitteln
| Zusammenspiel von Preis, Angebot und Nachfrage |
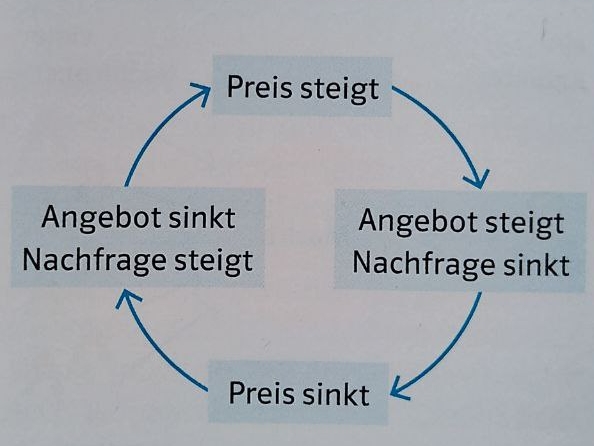 |
|
|
Bestimmung des Gleichgewichtspreises |
|
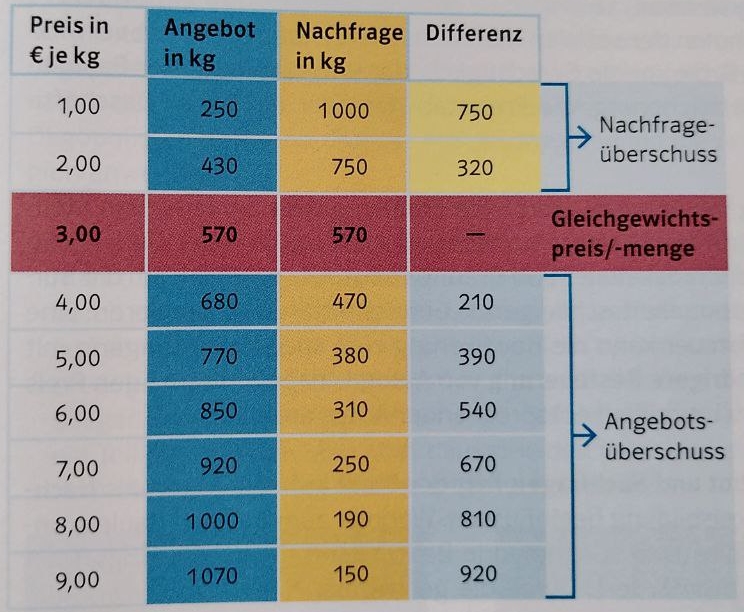 |
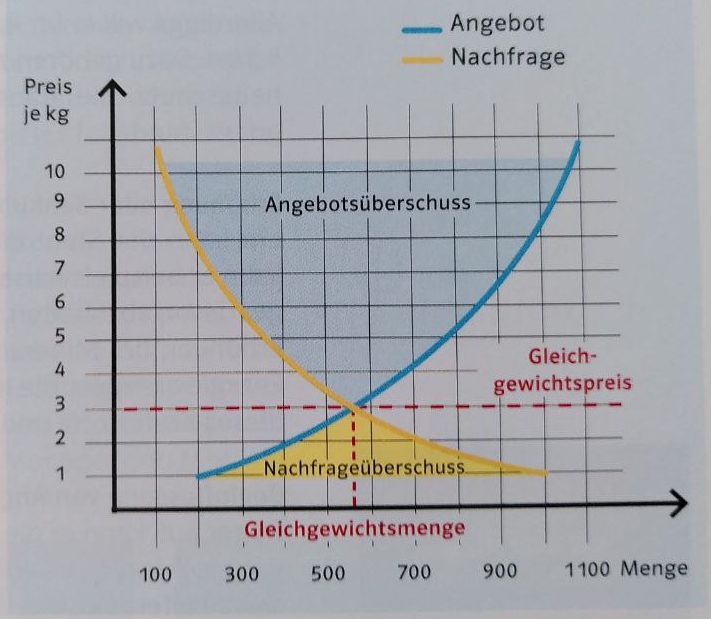
Auswirkungen von Angebots- und Nachfrageänderungen auf den Gleichgewichtspreis und die Gleichgewichtsmenge darstellen:
- Verschieben der Angebotskurve:
- nach links (Angebot sinkt) -> Gleichgewichtspreis steigt
- nach rechts (Angebot steigt) -> Gleichgewichtspreis sinkt
- Verschieben der Nachfragekurve:
- nach links (Nachfrage sinkt) -> Gleichgewichtspreis sinkt
- nach rechts (Nachfrage steigt) -> Gleichgewichtspreis steigt
Nachteile der freien Markpreisbildung
Einflussmöglichkeiten des Staats auf die Marktpreisbildung
- Erhöhung oder Senkung von Steuern, somit Veränderung des Endverkaufpreises
- Beeinflussung von Angebot und Nachfrage
- Staat kann selbst als Nachfrager auftretten z.B. Bauleistungen
- Staat kann Subventionen zahlen z.B. Wohngeld
- Festsetzung von Höchstpreisen
- Gefahr von Schwarzmärkten
- Festsetzung von Mindespreisen
- Gefahr von Überproduktion die direkt vernichtet werden muss
Soziale Marktwirtschaft
- Ziel: ermöglichen der Vorteile der Marktwirtschaft, bei gleichzeitiger Vermeidung der Nachteile
- hohes Maß an persönlicher Freiheit wird ermöglicht
- Abwendung der Missstände einer freien Marktwirtschaft
- Folge: Eingriff des Staats in den Markt auf Seiten der Schwachen
- Grundwerte:
- Der Staat unterstützt das Privateigentum, welches zugleich aber der Allgemeinheit dienen soll
- Vertragsfreiheit ist eingeschränkt, wenn Unternehmen Preisabsprachen treffen wollen
- Zur Eröffnung von Handwerksbetrieben sind Meisterprüfung oder Berufspraxis erforderlich
Wirkung der Instrumente der sozialen Marktwirtschaft
- Sozialpolitik
- wer in Not gerät, kann mit der Hilfe des Staats rechnen
- System der Sozialversicherungen
- Arbeitsschutzbestimmungen
- Einkommens- und Vermögenspolitik
- wer mehr Verdient zahlt absolut sowie relativ mehr Steuern (Steuerprogression)
- Wettbewerbspolitik
- Vermeidung von Kartellen, da diese zum Nachteil der Verbraucher sind
- Umweltpolitik
- Schaffung von Anreizen für Umweltbewusstesverhalten
- Schutz der Lebensgrundlage zukünftiger Generationen
4 - Entscheidungen im Rahmen einer beruflichen Selbstständigkeit treffen
Anforderungen an eine Unternehmerpersönlichkeit
Eine hohe Anzahl von gescheiterten Existenzgründungen zeigen, dass der Schritt in die Selbständigkeit gut überlegt sein sollte. Der Unternehmenserfolg hängt sehr von der Person des Existenzgründers ab. Ein Gründer muss bestimmte persönliche und fachliche Voraussetzungen erfüllen.
- Persönliche Voraussetzungen
- Belastbarkeit: in den jersten Jahren ist die zeichtliche, körperliche und psychische Belastung sehr hoch
- Verantwortungsbewusstsein: muss für seine Entscheidungen einstehen und manchmal gegen die eigenen Interessen verstoßen, im Sinne des Kunden und der Mitarbeiter
- Eigeninitiative: es gibt niemanden der einen antreibt
- Führungseigenschaften: MitarbeiterInnen führen und anspornen
- Risikobereitschaft: viele Entscheidungen sind auch mit einem Risiko verbunden
- Duchtsetzungsvermögen: darf sich nicht entmutigen lassen und muss gegenüber Mitarbeitern und Kunden einstehen
- Entscheidungsfreudigkeit: Entscheidungen müssen in der Gründungsphase schnell erfolgen
- Familiärer Rückhalt: die Familie muss in der Gründungsphase auf vieles verzichten und unterstützen
- Organisationstalent: muss Arbeit verwalten, koordinieren und übertragen
- Fachliche Voraussetzungen
- Fachkenntnisse: ohne eine Ahnung von den Inhalten geht nichts
- betriebswirtschaftliche Grundkenntnisse: Steuerrecht, Vertragsrecht und Rechnungswesen
Chancen einer Unternehmensgründung:
- höhreres Ansehen in der Öffentlichkeit
- Unabhängigkeit
- höheres Einkommen
- Selbstverantwortung und Selbstverwirklichung
Risiken einer Unternehmensgründung:
- Hohe Arbeitsbelastung: Gründungsformalitäten, Auftragsbeschaffung, Arbeitszeiten
- Einkommens- und Vermögensverluste: misslingt eine Unternehmensgründung, dann sind Einkommensverluste die Folge
- Verantwortung: GründerIn trägt nicht nur für sich selbst die Verantwortung, sondern auch für Mitarbeiter und deren Familien
- Verlust der sozialen Sicherung: Selbstständige müssen selbst für ihre soziale Sicherung sorgen (Sozialversicherungen müssen selbst gezahlt werden und werden nicht vom Bruttogehalt abgezogen)
Geschäftsplan
Vor der Ausarbeitung eines Geschäftsplan sollte man sich über die Zielgruppe Gedanken machen. Wenn die Zielgruppe fachfremd ist, müssen eventuell Fachbegriffe erklärt werden. Ein Geschäftsplan sollte nicht länger als 30 Seiten sein, auf technische Details sollte verzichtet werden, einen vollständen aber kurzen Abriss zu Chancen, Risiken und Aufgaben beinhalten und vor allem realistisch und sachlich sein, um nicht unglaubhaft zu wirken. Beim Inhalt kann man sich an folgendem Schema orientieren:
| Zusammenfassung |
|
||||||||||||||||
| Grundinfos über das Unternehmen und rechtliche Verhältnisse |
|
||||||||||||||||
| Idee des Unternehmens (Produkt) |
|
||||||||||||||||
| Markt, Standort und Konkurrenz |
Überprüfung der aktuellen Marktposition. Fakten zur aktuellen Marktsituation, Kunden und Standort. Quellen für Markt- und Datenrecherchen sind:
|
||||||||||||||||
| Zielmarkt |
Marktentwicklung berücksichtigen (Kosten, Absatz) |
||||||||||||||||
| Zielgruppe |
|
||||||||||||||||
| Konkurrenz |
Wettbewerbsanalyse der Konkurrenz:
|
||||||||||||||||
| Standort |
Standortanalyse anhand der Standortfaktoren |
||||||||||||||||
| Marketing und Vertrieb |
Marketingkonzept - wie soll das Unternehmen auf den Markt und die Zielgruppe ausgerichtet werden Vertriebskonzept - Kosten/Nutzen-Analyse der geplanten Absatzwege |
||||||||||||||||
| Preispolitik |
|
||||||||||||||||
| Produktpolitik |
|
||||||||||||||||
| Distributionspolitik |
|
||||||||||||||||
| Kommunikationspolitik |
|
||||||||||||||||
| Management und Personal |
|
Standortfaktoren
Wer ein Unternehmen gründet bzw. mit einem bestehenden Unternehmen expandieren will und deshalb neue Standorte etablieren will, sollte sich über bestimmte Faktoren Gedanken machen. Anhand dieser kann ermittelt werden, ob der Standort für das eigene Unternehmen günstig ist.
Es gibt harte und weiche Standortfaktoren.
Harte Standortfaktoren sind Faktoren, die quantifizierbar sind, z.B. Verkehrsanbindung oder Mietkosten. Weitere harte Standortfaktoren sind:
- Lage
- Transportkosten
- Arbeitsmarkt
- Steuern und Abgaben
- Fördermittel
- Rohstoffverfügbarkeit
- Mitarbeiterentwicklung
- Kundenanzahl
Weiche Standortfaktoren sind eher subjektive Faktoren, z.B. Wohnort der gegenwärtigen Angestellten politische oder bürokratische Verhältnisse.
Weiterhin wird zwischen unternehmens- und personenbezogenen Faktoren unterschieden.
Unternehmensbezogene Faktoren sind Faktoren, die sich direkt auf auf die Wettbewerbsfähigkeit des Unternehmens auswirken, z.B. Konkurrenzlage und wirtschaftliche Lage des Standorts.
Personenbezogene Faktoren sind Faktoren, die die Lebensqualität der Angestellten beeinflussen, z.B. Schulen/Ausbildungseinrichtungen, Freizeitangebot, medizinische Versorgung, Umwelt oder Wohnumgebung.
Im Bezug auf die Betriebswirtschaft kann auch noch zwischen beschaffungsorientierten, also Faktoren, welche sich auf die Versorgung mit Rohstoffen für die Produktion auswirken (z.B. Verkehrsanbindung), produktionsorientierten, also Faktoren, welche Einfluss auf den Produktionsprozess haben (z.B. Mitarbeiter), und absatzorientierten, also Faktoren, die sich auf den Absatz der eigenen Produkte auswirken (z.B. Lage), unterschieden werden.
Rechtsformen / Unternehmensformen
Zunächst werden die folgenden Rechtsformen unterschieden:
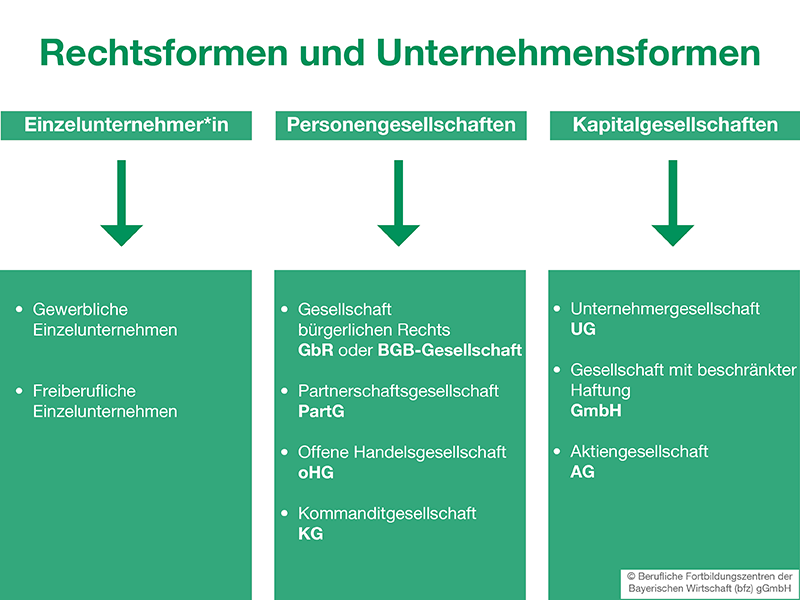
An die Unternehmensformen sind unter Umständen bestimmte Voraussetzungen gekoppelt, manche Formen müssen bspw. ins Handelsregister eingetragen werden oder sind nur mit mindestens 2 Personen gründbar.
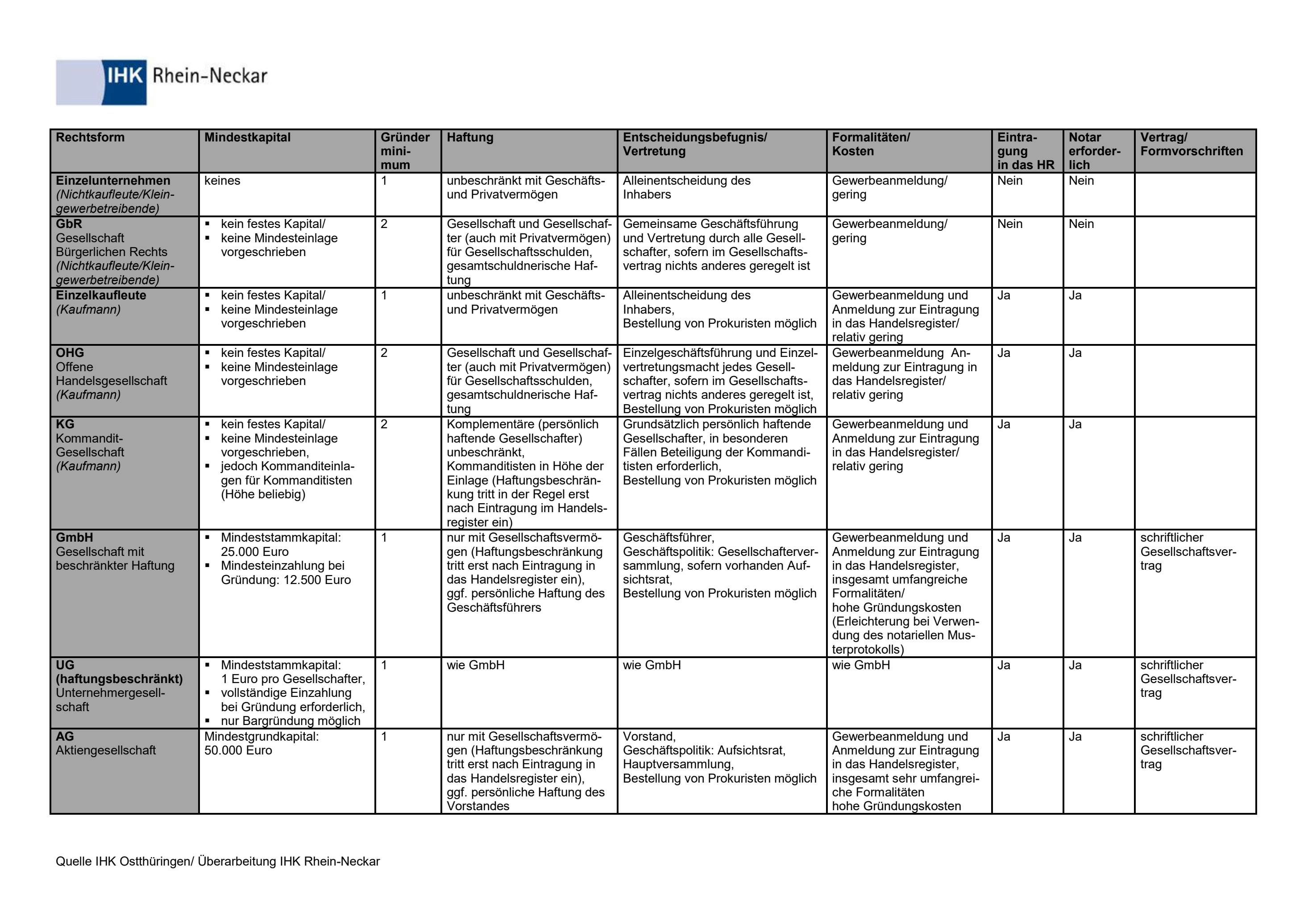
Gegenüberstellung GmbH & Einzelunternehmen
| Einzelunternehmung | GmbH | |
| Mindestkapital |
keines |
Mindeststammkapital: 25'000€ bei Gründung mindestens 12'500€ |
| Gründerminium |
1 |
1 |
| Haftung |
unbeschränkt mit Gesellschafts-und Privatvermögen |
nur mit Gesellschaftsvermögen (erst nach Eintragung ins HR), ggf. Haftung des Geschäftsführers mit Privatvermögen (bei Sorgfaltspflichverletzung) |
| Entscheidungsbefugnis/Vertretung |
Alleinentscheidung des Inhabers |
Geschäftsführer Geschäftspolitik: Gesellschaftsversammlung, Aufsichtsrat (sofern vorhanden) ggf. Prokuristen (Kaufmann mit weitreichenden Vertretungsrechten) |
| Formalitäten/Kosten |
Gewerbeanmeldung (gering) |
Gewerbeanmeldung und Eintragung ins HR (umfangreiche Formalitäten, hoch) |
| Eintragung ins HR notwendig? |
Nein |
Ja |
| Notar erforderlich? |
Nein |
Ja |
| Vertrag |
schriftlicher Gesellschaftervertrag |
Kapitalbedarf bei einer Unternehmensgründung (Kapitalbedarfsplan)
Drei-Säulen-Modell (Nachhaltigkeit)
Nachhaltigkeit oder nachhaltige Entwicklung bedeutet, die Bedürfnisse der Gegenwart so zu befriedigen, dass die Möglichkeiten zukünftiger Generationen nicht eingeschränkt werden.

Das Drei-Säulen-Modell der nachhaltigen Entwicklung geht von der Vorstellung aus, dass nachhaltige Entwicklung nur durch das gleichzeitige und gleichberechtigte Umsetzen von umweltbezogenen, wirtschaftlichen und sozialen Zielen erreicht werden kann. Nur auf diese Weise kann die ökologische, ökonomische und soziale Leistungsfähigkeit einer Gesellschaft sichergestellt und verbessert werden. Die drei Aspekte bedingen dabei einander.
Mit diesen drei Dimensionen der Nachhaltigkeit sind im Wesentlichen gemeint:
- Ökologische Nachhaltigkeit: Sie orientiert sich am stärksten am ursprünglichen Gedanken, keinen Raubbau an der Natur zu betreiben. Ökologisch nachhaltig wäre eine Lebensweise, die die natürlichen Lebensgrundlagen nur in dem Maße beansprucht, wie diese sich regenerieren.
- Ökonomische Nachhaltigkeit: Eine Gesellschaft sollte wirtschaftlich nicht über ihre Verhältnisse leben, da dies zwangsläufig zu Einbußen der nachkommenden Generationen führen würde. Allgemein gilt eine Wirtschaftsweise dann als nachhaltig, wenn sie dauerhaft betrieben werden kann.
- Soziale Nachhaltigkeit: Ein Staat oder eine Gesellschaft sollte so organisiert sein, dass sich die sozialen Spannungen in Grenzen halten und Konflikte nicht eskalieren, sondern auf friedlichem und zivilem Wege ausgetragen werden können.
Unternehmenszusammenschlüsse
Horizontale Zusammenschlüsse
Horizontalen Zusammenschlüsse sind ein Zusammenschluss von Unternehmen der gleichen Produktionsstufe beziehungsweise Handelsstufe. Ziel eines horizontalen Zusammenschlusses ist die Stärkung der eigenen Marktposition.
Ein Beispiel sind der Zusammenschluss von Brauerei I und Brauerei II.
Vertikale Zusammenschlüsse
Vertikale Zusammenschlüsse sind ein Zusammenschluss von Unternehmen nachgelagerter oder aufeinander folgender Produktionsstufen beziehungsweise Handelsstufen. Ziel eines vertikalen Zusammenschlusses ist die Sicherung von Beschaffung und Absatz.
Ein Beispiel ist der Zusammenschluss eines Stahlwerkes mit einem Hüttenwerk, einem Stahlhandel und einer Schlosserei.
Anorganische Zusammenschlüsse
Anorganische Zusammenschlüsse sind der Zusammenschluss von Unternehmen verschiedener Branchen oder Produktionsstufen. Sie werden auch „konglomerate Zusammenschlüsse“ genannt. Ziel anorganischer Zusammenschlüsse ist der Ausgleich von Branchenrisiken.
Ein Beispiel ist der Zusammenschluss eines Stahlwerkes mit einer Textilfabrik, einem Kaufhaus und einer Tankstelle.